

vLLM部署教程:高性能本地AI服务搭建指南
从零搭建 OpenAI 兼容本地推理 API,适合开发者、AI工具站与企业内部应用
别再只会 Ollama:vLLM 本地部署高并发 AI 服务完整教程
如果你只是想在电脑上和本地模型聊天,Ollama、LM Studio 已经足够好用;但如果你想把本地大模型做成一个可被网站、工作流、RAG 系统、代码插件或内部业务系统调用的高性能 API 服务,vLLM 就是更偏“工程化”和“生产化”的选择。
vLLM 的核心定位不是“桌面聊天软件”,而是面向大模型推理和在线服务的高吞吐引擎。它更适合处理多用户并发、API 调用、批处理、服务端部署、GPU 资源利用率优化等场景。
| 本文目标:用一篇教程讲清 vLLM 是什么、适合谁、需要什么硬件、如何用 Docker 快速部署、如何启动 OpenAI 兼容接口、如何用 Python 调用,以及常见报错如何排查。 |
目录
- 1. vLLM 是什么,和 Ollama/LM Studio 有什么区别
- 2. 安装前准备:系统、GPU、驱动、Docker 与模型账号
- 3. 路线一:Docker 快速部署 vLLM 服务
- 4. 路线二:Python 环境安装 vLLM
- 5. 启动 OpenAI 兼容 API 服务
- 6. 用 Python / curl 调用本地模型
- 7. 模型选择、量化与显存估算
- 8. 性能优化:并发、上下文、KV Cache 与多卡
- 9. 常见报错排查
- 10. FAQ、相关阅读与 SEO 文档
一、vLLM 是什么?适合哪些人使用
vLLM 是一个面向大语言模型推理与服务的开源引擎,强调高吞吐、内存效率和易于部署。它最常见的用法,是把 Hugging Face 上的模型启动成一个 OpenAI 兼容 API 服务,然后让前端、RAG、工作流平台、企业系统或代码工具调用。
- 适合开发者:想把本地模型封装成 API,供前端或后端项目调用。
- 适合 AI 工具站:想搭建一个可持续调用的本地推理服务,而不是每次手动打开聊天软件。
- 适合企业内部:需要私有化部署、权限控制、日志监控和多用户并发。
- 适合进阶玩家:想研究吞吐、KV Cache、张量并行、量化、OpenAI 兼容协议等。
二、vLLM、Ollama、LM Studio 怎么选
| 工具 | 最适合场景 | 优势 | 限制 |
| Ollama | 个人本地模型、快速拉模型、命令行体验 | 安装简单,模型管理方便,适合入门 | 更偏个人/轻服务,复杂并发和生产部署能力有限 |
| LM Studio | 桌面端本地聊天、模型下载、OpenAI 兼容本地 API | 图形界面友好,适合非程序员 | 高并发和生产化部署不是主要定位 |
| vLLM | 服务端推理、API 服务、多用户并发、企业内部部署 | 吞吐高,支持 OpenAI 兼容 API、Docker、多卡、量化等 | 安装门槛更高,最好有 Linux 和 NVIDIA GPU 环境 |
| 简单判断:只想本机聊天选 LM Studio 或 Ollama;想给网站/工作流/插件提供统一模型接口,优先考虑 vLLM。 |
三、安装前准备:先确认这 6 件事
vLLM 对运行环境的要求比普通桌面工具高。部署前先确认系统、Python、GPU、驱动、Docker、模型权限这几项,能避免一半以上的报错。
| 检查项 | 推荐配置 | 验证命令/说明 |
| 系统 | Linux 服务器、Ubuntu 22.04/24.04,Windows 用户建议 WSL2 | vLLM 官方 GPU 安装要求为 Linux;Windows 原生不支持 |
| Python | 3.10 – 3.13;新环境优先 Python 3.12 | python3 –version |
| GPU | NVIDIA CUDA 最稳;生产建议 24GB+ 显存 | nvidia-smi |
| 驱动/CUDA | 优先使用官方 Docker 镜像减少依赖冲突 | Docker 路线不必手动装完整 CUDA Toolkit |
| Docker | Docker Engine + NVIDIA Container Toolkit | docker –version;docker run –gpus all … |
| 模型权限 | 公开模型可直接下载;受限模型需要 Hugging Face Token | export HF_TOKEN=你的token |
官方 GPU 文档列出 vLLM 的基础要求包括 Linux、Python 3.10-3.13;NVIDIA CUDA 方向要求计算能力 7.5 或以上,Windows 原生不支持,需要通过 WSL 或其他方式运行。
- 个人测试:RTX 3060/4060/4070/4080/4090 这类显卡可以从小模型开始。
- 团队服务:优先 24GB、48GB、80GB 以上显存,模型越大、上下文越长、并发越高,对显存要求越高。
- 生产部署:建议单独 Linux 服务器,不建议在日常办公电脑上长期跑高并发服务。

四、路线一:Docker 快速部署 vLLM 服务(新手推荐)
如果你是第一次部署 vLLM,最推荐先用官方 Docker 镜像。好处是依赖已经打包好,减少 CUDA、PyTorch、Python 环境冲突。
1. 安装并验证 Docker 与 GPU
在 Linux 服务器上安装 Docker 和 NVIDIA Container Toolkit 后,先确认宿主机能看到 GPU:
nvidia-smi
docker –version
再用一个带 GPU 的容器测试 Docker 是否能调用显卡:
docker run –rm –gpus all nvidia/cuda:12.4.1-base-ubuntu22.04 nvidia-smi
如果这一步失败,不要急着装 vLLM,先处理驱动、Docker、nvidia-container-toolkit 的问题。
2. 准备 Hugging Face Token(可选但建议)
如果模型是公开模型,可能不需要 Token;如果模型需要申请授权,或者你希望稳定拉取模型,建议设置 HF_TOKEN。
export HF_TOKEN=”你的_HuggingFace_Token”
3. 用官方镜像启动 vLLM
下面用 Qwen/Qwen3-0.6B 做示例,它体积较小,适合第一次验证服务是否跑通:
docker run –runtime nvidia –gpus all \
-v ~/.cache/huggingface:/root/.cache/huggingface \
–env “HF_TOKEN=$HF_TOKEN” \
-p 8000:8000 \
–ipc=host \
vllm/vllm-openai:latest \
–model Qwen/Qwen3-0.6B
| 为什么要加 –ipc=host:vLLM 底层使用 PyTorch,张量并行等场景会用到共享内存。官方 Docker 文档说明可以使用 –ipc=host 或 –shm-size,让容器访问足够的共享内存。 |
4. 固定版本更适合生产
教程测试可以使用 latest,但生产环境建议固定镜像版本,避免一次拉镜像后行为变化。示例:
docker pull vllm/vllm-openai:v0.11.0
# 生产环境建议把镜像、模型、启动参数都写入 docker compose 或部署脚本
五、路线二:Python 环境安装 vLLM(开发者路线)
如果你要改 vLLM 代码、做插件开发、调试源码或不想用 Docker,可以走 Python 环境安装。新手不建议直接在系统 Python 里装,务必使用干净虚拟环境。
1. 创建虚拟环境
官方文档推荐使用 uv 创建和管理 Python 环境:
uv venv –python 3.12 –seed –managed-python
source .venv/bin/activate
2. 安装预编译 wheel
NVIDIA CUDA 场景可使用下面的方式安装:
uv pip install vllm –torch-backend=auto
如果使用 pip,官方示例给出 CUDA 12.9 的 extra-index-url:
pip install vllm –extra-index-url https://download.pytorch.org/whl/cu129
| 环境建议:如果你本机已有复杂 PyTorch/CUDA 环境,安装 vLLM 时更容易冲突。优先新建环境;如果需要复用已有 PyTorch,则要更认真检查 CUDA、Torch、vLLM wheel 的兼容性。 |
六、启动 OpenAI 兼容 API 服务
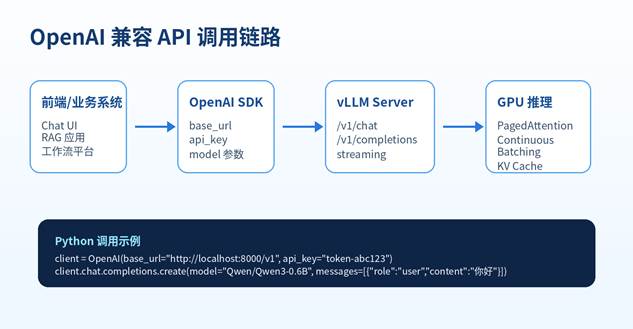
vLLM 很重要的一点是提供 OpenAI 兼容服务。也就是说,很多原本调用 OpenAI SDK 的项目,只要把 base_url 改成本地 vLLM 地址,就可以调用你的本地模型。
vllm serve NousResearch/Meta-Llama-3-8B-Instruct \
–dtype auto \
–api-key token-abc123
服务启动后,默认可以通过类似下面的地址访问:
http://localhost:8000/v1
如果是远程服务器,把 localhost 换成服务器 IP 或域名;生产环境不要直接裸露 8000 端口,建议放在 Nginx、网关或内网服务后面。
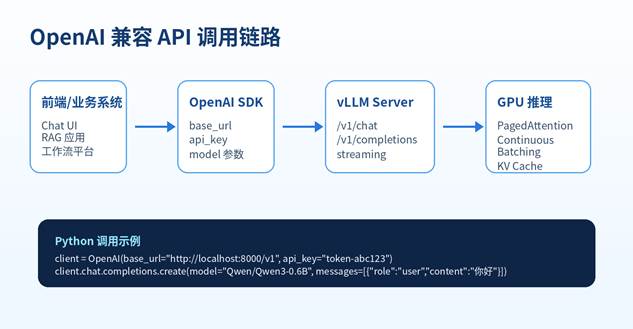
七、用 curl 测试接口
服务启动后,先不要急着接业务系统,先用 curl 测试接口是否返回。
curl http://localhost:8000/v1/chat/completions \
-H “Content-Type: application/json” \
-H “Authorization: Bearer token-abc123” \
-d ‘{
“model”: “Qwen/Qwen3-0.6B”,
“messages”: [{“role”: “user”, “content”: “用一句话解释 vLLM 是什么”}],
“temperature”: 0.7
}’
如果这里返回 JSON,说明服务端、模型加载、端口映射和鉴权基本都正常。
八、用 Python 调用本地 vLLM
Python 项目可以继续使用 OpenAI 官方 SDK 的调用习惯,只需要把 base_url 指向本地 vLLM。
from openai import OpenAI
client = OpenAI(
base_url=”http://localhost:8000/v1″,
api_key=”token-abc123″,
)
completion = client.chat.completions.create(
model=”Qwen/Qwen3-0.6B”,
messages=[
{“role”: “user”, “content”: “写一个适合公众号的 AI 工具推荐开头”}
],
)
print(completion.choices[0].message.content)
流式输出示例
stream = client.chat.completions.create(
model=”Qwen/Qwen3-0.6B”,
messages=[{“role”: “user”, “content”: “列出 vLLM 的 3 个优势”}],
stream=True,
)
for chunk in stream:
delta = chunk.choices[0].delta.content
if delta:
print(delta, end=””, flush=True)
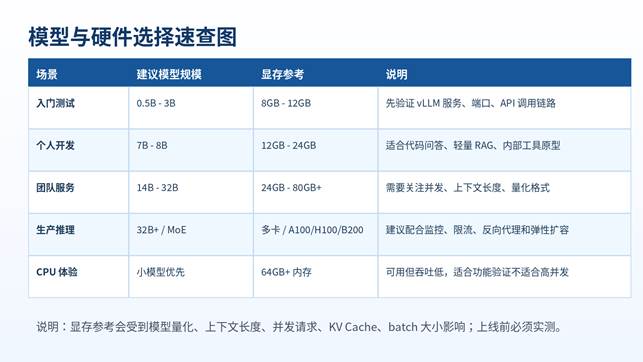
九、模型选择、量化与显存估算
vLLM 可以直接加载很多 Hugging Face 模型,但并不是模型越大越好。新手第一次部署建议先小后大:先用 0.5B、1.5B、3B 模型确认服务跑通,再尝试 7B、14B、32B。
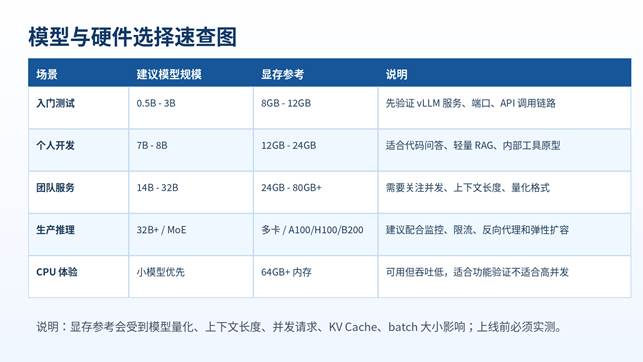
模型选择建议
- 只验证部署:选择小模型,缩短下载和加载时间。
- 中文问答:优先选中文能力较好的 instruct/chat 模型。
- 代码能力:选择代码模型或综合能力较强的通用模型。
- 长文本/RAG:关注上下文长度和 KV Cache 占用,不要只看参数量。
- 高并发:同样显存下,较小模型往往能提供更稳定的吞吐。
量化怎么理解
量化可以降低显存占用,常见有 AWQ、GPTQ、FP8、INT8、INT4、GGUF、bitsandbytes 等。vLLM 支持多种量化方式,但不同硬件、模型、量化格式的支持情况会变动,部署前应以官方文档和模型页面为准。
| 实战建议:别一上来就追求“最大模型”。对网站工具或内部应用来说,稳定、低延迟、可维护,比单次回答质量的极限更重要。 |
十、性能优化:从能跑到好用
vLLM 的价值在于高吞吐服务。跑通只是第一步,真正上线还要关注显存、并发、上下文长度、批处理、网络、监控和限流。
| 优化项 | 作用 | 建议 |
| –max-model-len | 限制上下文长度,影响 KV Cache 占用 | 长文本需求明确时再调大;默认过大可能浪费显存 |
| –gpu-memory-utilization | 控制 vLLM 可用 GPU 显存比例 | 显存紧张时降低;生产环境保留余量 |
| –tensor-parallel-size | 多卡张量并行 | 大模型单卡放不下时使用;要求多卡通信稳定 |
| 量化模型 | 降低显存占用 | 优先选择社区验证较多的量化格式 |
| Nginx / 网关 | 鉴权、限流、负载入口 | 不要直接暴露 vLLM 端口到公网 |
| Prometheus / 日志 | 观测吞吐、延迟、错误 | 生产环境必须保留服务日志和指标 |
多卡部署示例
如果模型较大,可以尝试张量并行。示例:
docker run –runtime nvidia –gpus all \
-v ~/.cache/huggingface:/root/.cache/huggingface \
–env “HF_TOKEN=$HF_TOKEN” \
-p 8000:8000 \
–ipc=host \
vllm/vllm-openai:latest \
–model meta-llama/Llama-3.1-70B-Instruct \
–tensor-parallel-size 4
多卡部署不是简单地“卡越多越快”,还要看模型大小、并发、通信开销、PCIe/NVLink、batch 策略等。
十一、生产部署建议:别把测试命令直接上线
- 固定版本:固定 vLLM 镜像版本、模型版本、启动参数,避免更新后接口行为变化。
- 安全边界:本地服务不要直接暴露公网,前面加 Nginx、鉴权、IP 白名单、限流。
- 日志与监控:记录请求量、错误率、平均延迟、显存使用、GPU 利用率。
- 模型缓存:把 Hugging Face 缓存目录挂载出来,避免容器重启后重复下载。
- 灰度切换:新模型先在测试端口运行,确认稳定后再切主服务。
- 容量规划:上线前用真实 prompt、真实并发压测,不要只用单条短问答判断性能。
docker compose 示例
services:
vllm:
image: vllm/vllm-openai:latest
container_name: vllm-server
runtime: nvidia
ipc: host
ports:
– “8000:8000”
environment:
– HF_TOKEN=${HF_TOKEN}
volumes:
– ~/.cache/huggingface:/root/.cache/huggingface
command: >
–model Qwen/Qwen3-0.6B
–dtype auto
–api-key ${VLLM_API_KEY}
十二、常见报错排查

| 问题 | 可能原因 | 处理办法 |
| No CUDA GPUs are available | 容器未拿到 GPU;驱动或 nvidia-container-toolkit 异常 | 先跑 docker –gpus all nvidia/cuda… nvidia-smi,确认容器可见 GPU |
| CUDA / torch 版本冲突 | 复用旧环境、PyTorch 与 vLLM wheel 不匹配 | 新建虚拟环境;优先用 Docker;不要混装多个 CUDA/Torch |
| 显存不足 / OOM | 模型过大、上下文过长、并发过高 | 换小模型;降低 max_model_len;用量化;减少并发 |
| HTTP 401/403 下载失败 | 模型需要 Hugging Face 授权或 Token 无效 | 申请模型权限;设置 HF_TOKEN;检查容器环境变量 |
| chat template 报错 | 模型不是 chat/instruct 或 tokenizer 缺模板 | 换 instruct 模型;手动指定 –chat-template |
| 接口能访问但响应慢 | 模型太大、CPU/RAM/磁盘/网络瓶颈 | 观察 GPU 利用率、显存、日志;从小模型重新验证 |
十三、FAQ:新手最常问的问题
1. vLLM 能在 Windows 直接安装吗?
官方 GPU 安装文档说明 vLLM 不支持 Windows 原生运行。Windows 用户建议使用 WSL2、Linux 服务器或云 GPU。
2. 没有 NVIDIA 显卡能用吗?
可以尝试 CPU 路线或 AMD/Intel 平台,但新手和生产场景最省心的是 Linux + NVIDIA CUDA + Docker。CPU 路线更适合功能验证,不适合高并发。
3. vLLM 和 Ollama 可以同时安装吗?
可以。Ollama 适合个人本地模型和快速测试,vLLM 适合 API 服务和高并发。二者端口不要冲突即可。
4. 为什么推荐 Docker?
Docker 镜像已经打包依赖,能明显降低 CUDA、PyTorch、Python 版本冲突。新手先用 Docker 跑通,再考虑源码或 Python 安装。
5. 模型越大效果就越好吗?
不一定。模型大小、任务类型、量化、上下文、提示词、推理参数都会影响效果。网站服务更应关注稳定、成本和响应速度。
6. vLLM 可以接 Open WebUI、Dify、LangChain 吗?
可以。只要对方支持 OpenAI 兼容 API,一般把 base_url 改成 vLLM 地址即可。具体字段要按平台设置。
7. 生产环境是否需要 Nginx?
建议需要。Nginx 或 API 网关可以做 HTTPS、反向代理、限流、鉴权、日志和多服务转发。
8. 如何判断显存够不够?
先用小模型验证链路,再按模型参数量、量化格式、上下文长度和并发量逐步压测。真实业务请求比理论估算更可靠。
十四、相关阅读
• Ollama本地部署大模型完整教程:/ollama-local-llm-deployment-guide/
• 本地部署DeepSeek的详细步骤:/local-deploy-deepseek-guide/
• LM Studio安装与本地模型使用教程:/lm-studio-install-local-model-guide/
• VSCode里安装AI编程插件全流程:/vscode-ai-coding-plugins-install-guide/
• IDEA里安装AI编程插件全流程:/idea-ai-coding-plugins-install-guide/
• Windows电脑如何安装常见AI工具:/windows-ai-tools-install-guide/
• Mac电脑安装AI工具完整教程:/mac-ai-tools-install-guide/
十五、SEO 文档
| SEO字段 | 内容 |
| 文章摘要 | 本文是一篇面向新手和开发者的 vLLM 本地部署教程,系统讲解 vLLM 的适用场景、硬件准备、Docker 快速部署、Python 安装、OpenAI 兼容 API 调用、模型选择、性能优化、生产部署建议和常见报错排查。 |
| 主标题 | vLLM部署教程:高性能本地AI服务搭建指南 |
| 爆款标题 | 别再只会 Ollama:vLLM 本地部署高并发 AI 服务完整教程 |
| 别名 / Slug | vllm-local-ai-service-deployment-guide |
| 分类 | 保姆级教程 / 安装部署教程;AI工具库 / AI编程与开发工具;实战工作流 / 自动化工作流 |
| 标签 | vLLM、本地部署、大模型部署、AI服务、OpenAI兼容API、Docker部署、GPU推理、模型推理服务、RAG、私有化部署 |
| SEO标题 | vLLM部署教程:高性能本地AI服务搭建指南(Docker + OpenAI API) |
| SEO描述 | 想把本地大模型部署成可调用的高性能 AI 服务?本文从环境准备、Docker 启动、模型加载、OpenAI 兼容 API、Python 调用到性能优化和报错排查,完整讲解 vLLM 本地部署流程。 |
| 5个关键词 | vLLM部署教程, 本地大模型部署, OpenAI兼容API, Docker部署AI服务, 高性能AI推理 |
| 特色图替代文本 | vLLM 高性能本地 AI 服务部署教程封面图,展示模型、GPU、vLLM 引擎和 OpenAI API 调用链路 |
| 特色图标题 | vLLM部署教程:高性能本地AI服务搭建指南 |
| 特色图说明 | 本文适合希望搭建本地大模型 API 服务的开发者和企业用户,重点讲解 vLLM 的安装部署与接口调用。 |
| 特色图描述 | 一张科技风封面图,包含 GPU 服务器、模型权重、vLLM 引擎、OpenAI API 和业务应用的部署流程。 |
| 推荐URL | /vllm-local-ai-service-deployment-guide/ |
| 面向读者 | AI 工具站长、后端开发者、算法工程师、独立开发者、企业内部知识库负责人 |
| 搜索意图 | 用户想了解如何在本地或服务器上部署 vLLM,并将本地模型封装为可被应用调用的高性能 API 服务。 |
十六、发布前检查清单
- 文中命令里的模型 ID、端口、API Key 已按自己的环境修改。
- 如果发布到网站,代码块建议使用等宽字体和横向滚动。
- 封面图 ALT 文本已填写,便于搜索引擎识别。
- 相关阅读使用站内相对路径,发布后检查链接是否存在。
- 官方参考来源保留在文末,避免读者安装时遇到版本变化。
十七、官方参考来源
- vLLM Installation: https://docs.vllm.ai/en/latest/getting_started/installation/
- vLLM GPU Installation: https://docs.vllm.ai/en/latest/getting_started/installation/gpu/
- vLLM CPU Installation: https://docs.vllm.ai/en/latest/getting_started/installation/cpu/
- vLLM Docker Deployment: https://docs.vllm.ai/en/stable/deployment/docker/
- vLLM OpenAI-Compatible Server: https://docs.vllm.ai/en/latest/serving/openai_compatible_server/
- vLLM Quantization: https://docs.vllm.ai/en/latest/features/quantization/
- vLLM GitHub: https://github.com/vllm-project/vllm

vLLM部署教程:高性能本地AI服务搭建指南
从零搭建 OpenAI 兼容本地推理 API,适合开发者、AI工具站与企业内部应用
别再只会 Ollama:vLLM 本地部署高并发 AI 服务完整教程
如果你只是想在电脑上和本地模型聊天,Ollama、LM Studio 已经足够好用;但如果你想把本地大模型做成一个可被网站、工作流、RAG 系统、代码插件或内部业务系统调用的高性能 API 服务,vLLM 就是更偏“工程化”和“生产化”的选择。
vLLM 的核心定位不是“桌面聊天软件”,而是面向大模型推理和在线服务的高吞吐引擎。它更适合处理多用户并发、API 调用、批处理、服务端部署、GPU 资源利用率优化等场景。
| 本文目标:用一篇教程讲清 vLLM 是什么、适合谁、需要什么硬件、如何用 Docker 快速部署、如何启动 OpenAI 兼容接口、如何用 Python 调用,以及常见报错如何排查。 |
目录
- 1. vLLM 是什么,和 Ollama/LM Studio 有什么区别
- 2. 安装前准备:系统、GPU、驱动、Docker 与模型账号
- 3. 路线一:Docker 快速部署 vLLM 服务
- 4. 路线二:Python 环境安装 vLLM
- 5. 启动 OpenAI 兼容 API 服务
- 6. 用 Python / curl 调用本地模型
- 7. 模型选择、量化与显存估算
- 8. 性能优化:并发、上下文、KV Cache 与多卡
- 9. 常见报错排查
- 10. FAQ、相关阅读与 SEO 文档
一、vLLM 是什么?适合哪些人使用
vLLM 是一个面向大语言模型推理与服务的开源引擎,强调高吞吐、内存效率和易于部署。它最常见的用法,是把 Hugging Face 上的模型启动成一个 OpenAI 兼容 API 服务,然后让前端、RAG、工作流平台、企业系统或代码工具调用。
- 适合开发者:想把本地模型封装成 API,供前端或后端项目调用。
- 适合 AI 工具站:想搭建一个可持续调用的本地推理服务,而不是每次手动打开聊天软件。
- 适合企业内部:需要私有化部署、权限控制、日志监控和多用户并发。
- 适合进阶玩家:想研究吞吐、KV Cache、张量并行、量化、OpenAI 兼容协议等。
二、vLLM、Ollama、LM Studio 怎么选
| 工具 | 最适合场景 | 优势 | 限制 |
| Ollama | 个人本地模型、快速拉模型、命令行体验 | 安装简单,模型管理方便,适合入门 | 更偏个人/轻服务,复杂并发和生产部署能力有限 |
| LM Studio | 桌面端本地聊天、模型下载、OpenAI 兼容本地 API | 图形界面友好,适合非程序员 | 高并发和生产化部署不是主要定位 |
| vLLM | 服务端推理、API 服务、多用户并发、企业内部部署 | 吞吐高,支持 OpenAI 兼容 API、Docker、多卡、量化等 | 安装门槛更高,最好有 Linux 和 NVIDIA GPU 环境 |
| 简单判断:只想本机聊天选 LM Studio 或 Ollama;想给网站/工作流/插件提供统一模型接口,优先考虑 vLLM。 |
三、安装前准备:先确认这 6 件事
vLLM 对运行环境的要求比普通桌面工具高。部署前先确认系统、Python、GPU、驱动、Docker、模型权限这几项,能避免一半以上的报错。
| 检查项 | 推荐配置 | 验证命令/说明 |
| 系统 | Linux 服务器、Ubuntu 22.04/24.04,Windows 用户建议 WSL2 | vLLM 官方 GPU 安装要求为 Linux;Windows 原生不支持 |
| Python | 3.10 – 3.13;新环境优先 Python 3.12 | python3 –version |
| GPU | NVIDIA CUDA 最稳;生产建议 24GB+ 显存 | nvidia-smi |
| 驱动/CUDA | 优先使用官方 Docker 镜像减少依赖冲突 | Docker 路线不必手动装完整 CUDA Toolkit |
| Docker | Docker Engine + NVIDIA Container Toolkit | docker –version;docker run –gpus all … |
| 模型权限 | 公开模型可直接下载;受限模型需要 Hugging Face Token | export HF_TOKEN=你的token |
官方 GPU 文档列出 vLLM 的基础要求包括 Linux、Python 3.10-3.13;NVIDIA CUDA 方向要求计算能力 7.5 或以上,Windows 原生不支持,需要通过 WSL 或其他方式运行。
- 个人测试:RTX 3060/4060/4070/4080/4090 这类显卡可以从小模型开始。
- 团队服务:优先 24GB、48GB、80GB 以上显存,模型越大、上下文越长、并发越高,对显存要求越高。
- 生产部署:建议单独 Linux 服务器,不建议在日常办公电脑上长期跑高并发服务。

四、路线一:Docker 快速部署 vLLM 服务(新手推荐)
如果你是第一次部署 vLLM,最推荐先用官方 Docker 镜像。好处是依赖已经打包好,减少 CUDA、PyTorch、Python 环境冲突。
1. 安装并验证 Docker 与 GPU
在 Linux 服务器上安装 Docker 和 NVIDIA Container Toolkit 后,先确认宿主机能看到 GPU:
nvidia-smi
docker –version
再用一个带 GPU 的容器测试 Docker 是否能调用显卡:
docker run –rm –gpus all nvidia/cuda:12.4.1-base-ubuntu22.04 nvidia-smi
如果这一步失败,不要急着装 vLLM,先处理驱动、Docker、nvidia-container-toolkit 的问题。
2. 准备 Hugging Face Token(可选但建议)
如果模型是公开模型,可能不需要 Token;如果模型需要申请授权,或者你希望稳定拉取模型,建议设置 HF_TOKEN。
export HF_TOKEN=”你的_HuggingFace_Token”
3. 用官方镜像启动 vLLM
下面用 Qwen/Qwen3-0.6B 做示例,它体积较小,适合第一次验证服务是否跑通:
docker run –runtime nvidia –gpus all \
-v ~/.cache/huggingface:/root/.cache/huggingface \
–env “HF_TOKEN=$HF_TOKEN” \
-p 8000:8000 \
–ipc=host \
vllm/vllm-openai:latest \
–model Qwen/Qwen3-0.6B
| 为什么要加 –ipc=host:vLLM 底层使用 PyTorch,张量并行等场景会用到共享内存。官方 Docker 文档说明可以使用 –ipc=host 或 –shm-size,让容器访问足够的共享内存。 |
4. 固定版本更适合生产
教程测试可以使用 latest,但生产环境建议固定镜像版本,避免一次拉镜像后行为变化。示例:
docker pull vllm/vllm-openai:v0.11.0
# 生产环境建议把镜像、模型、启动参数都写入 docker compose 或部署脚本
五、路线二:Python 环境安装 vLLM(开发者路线)
如果你要改 vLLM 代码、做插件开发、调试源码或不想用 Docker,可以走 Python 环境安装。新手不建议直接在系统 Python 里装,务必使用干净虚拟环境。
1. 创建虚拟环境
官方文档推荐使用 uv 创建和管理 Python 环境:
uv venv –python 3.12 –seed –managed-python
source .venv/bin/activate
2. 安装预编译 wheel
NVIDIA CUDA 场景可使用下面的方式安装:
uv pip install vllm –torch-backend=auto
如果使用 pip,官方示例给出 CUDA 12.9 的 extra-index-url:
pip install vllm –extra-index-url https://download.pytorch.org/whl/cu129
| 环境建议:如果你本机已有复杂 PyTorch/CUDA 环境,安装 vLLM 时更容易冲突。优先新建环境;如果需要复用已有 PyTorch,则要更认真检查 CUDA、Torch、vLLM wheel 的兼容性。 |
六、启动 OpenAI 兼容 API 服务
vLLM 很重要的一点是提供 OpenAI 兼容服务。也就是说,很多原本调用 OpenAI SDK 的项目,只要把 base_url 改成本地 vLLM 地址,就可以调用你的本地模型。
vllm serve NousResearch/Meta-Llama-3-8B-Instruct \
–dtype auto \
–api-key token-abc123
服务启动后,默认可以通过类似下面的地址访问:
http://localhost:8000/v1
如果是远程服务器,把 localhost 换成服务器 IP 或域名;生产环境不要直接裸露 8000 端口,建议放在 Nginx、网关或内网服务后面。
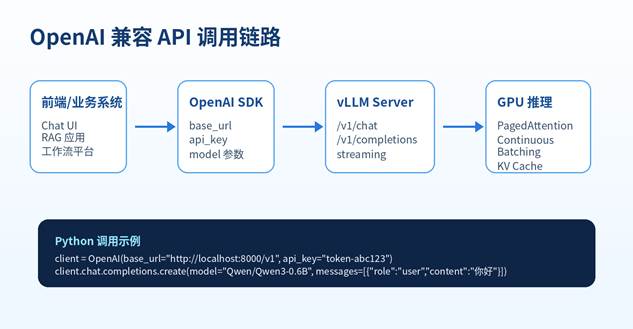
七、用 curl 测试接口
服务启动后,先不要急着接业务系统,先用 curl 测试接口是否返回。
curl http://localhost:8000/v1/chat/completions \
-H “Content-Type: application/json” \
-H “Authorization: Bearer token-abc123” \
-d ‘{
“model”: “Qwen/Qwen3-0.6B”,
“messages”: [{“role”: “user”, “content”: “用一句话解释 vLLM 是什么”}],
“temperature”: 0.7
}’
如果这里返回 JSON,说明服务端、模型加载、端口映射和鉴权基本都正常。
八、用 Python 调用本地 vLLM
Python 项目可以继续使用 OpenAI 官方 SDK 的调用习惯,只需要把 base_url 指向本地 vLLM。
from openai import OpenAI
client = OpenAI(
base_url=”http://localhost:8000/v1″,
api_key=”token-abc123″,
)
completion = client.chat.completions.create(
model=”Qwen/Qwen3-0.6B”,
messages=[
{“role”: “user”, “content”: “写一个适合公众号的 AI 工具推荐开头”}
],
)
print(completion.choices[0].message.content)
流式输出示例
stream = client.chat.completions.create(
model=”Qwen/Qwen3-0.6B”,
messages=[{“role”: “user”, “content”: “列出 vLLM 的 3 个优势”}],
stream=True,
)
for chunk in stream:
delta = chunk.choices[0].delta.content
if delta:
print(delta, end=””, flush=True)
九、模型选择、量化与显存估算
vLLM 可以直接加载很多 Hugging Face 模型,但并不是模型越大越好。新手第一次部署建议先小后大:先用 0.5B、1.5B、3B 模型确认服务跑通,再尝试 7B、14B、32B。
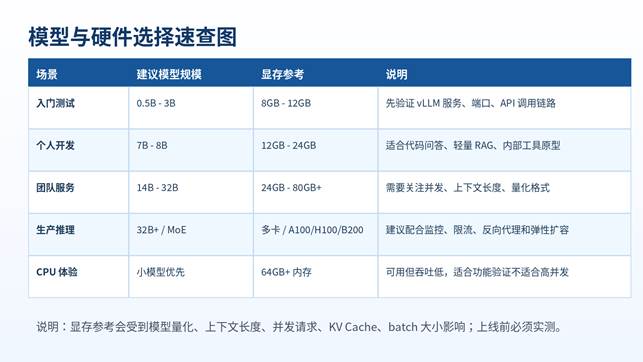
模型选择建议
- 只验证部署:选择小模型,缩短下载和加载时间。
- 中文问答:优先选中文能力较好的 instruct/chat 模型。
- 代码能力:选择代码模型或综合能力较强的通用模型。
- 长文本/RAG:关注上下文长度和 KV Cache 占用,不要只看参数量。
- 高并发:同样显存下,较小模型往往能提供更稳定的吞吐。
量化怎么理解
量化可以降低显存占用,常见有 AWQ、GPTQ、FP8、INT8、INT4、GGUF、bitsandbytes 等。vLLM 支持多种量化方式,但不同硬件、模型、量化格式的支持情况会变动,部署前应以官方文档和模型页面为准。
| 实战建议:别一上来就追求“最大模型”。对网站工具或内部应用来说,稳定、低延迟、可维护,比单次回答质量的极限更重要。 |
十、性能优化:从能跑到好用
vLLM 的价值在于高吞吐服务。跑通只是第一步,真正上线还要关注显存、并发、上下文长度、批处理、网络、监控和限流。
| 优化项 | 作用 | 建议 |
| –max-model-len | 限制上下文长度,影响 KV Cache 占用 | 长文本需求明确时再调大;默认过大可能浪费显存 |
| –gpu-memory-utilization | 控制 vLLM 可用 GPU 显存比例 | 显存紧张时降低;生产环境保留余量 |
| –tensor-parallel-size | 多卡张量并行 | 大模型单卡放不下时使用;要求多卡通信稳定 |
| 量化模型 | 降低显存占用 | 优先选择社区验证较多的量化格式 |
| Nginx / 网关 | 鉴权、限流、负载入口 | 不要直接暴露 vLLM 端口到公网 |
| Prometheus / 日志 | 观测吞吐、延迟、错误 | 生产环境必须保留服务日志和指标 |
多卡部署示例
如果模型较大,可以尝试张量并行。示例:
docker run –runtime nvidia –gpus all \
-v ~/.cache/huggingface:/root/.cache/huggingface \
–env “HF_TOKEN=$HF_TOKEN” \
-p 8000:8000 \
–ipc=host \
vllm/vllm-openai:latest \
–model meta-llama/Llama-3.1-70B-Instruct \
–tensor-parallel-size 4
多卡部署不是简单地“卡越多越快”,还要看模型大小、并发、通信开销、PCIe/NVLink、batch 策略等。
十一、生产部署建议:别把测试命令直接上线
- 固定版本:固定 vLLM 镜像版本、模型版本、启动参数,避免更新后接口行为变化。
- 安全边界:本地服务不要直接暴露公网,前面加 Nginx、鉴权、IP 白名单、限流。
- 日志与监控:记录请求量、错误率、平均延迟、显存使用、GPU 利用率。
- 模型缓存:把 Hugging Face 缓存目录挂载出来,避免容器重启后重复下载。
- 灰度切换:新模型先在测试端口运行,确认稳定后再切主服务。
- 容量规划:上线前用真实 prompt、真实并发压测,不要只用单条短问答判断性能。
docker compose 示例
services:
vllm:
image: vllm/vllm-openai:latest
container_name: vllm-server
runtime: nvidia
ipc: host
ports:
– “8000:8000”
environment:
– HF_TOKEN=${HF_TOKEN}
volumes:
– ~/.cache/huggingface:/root/.cache/huggingface
command: >
–model Qwen/Qwen3-0.6B
–dtype auto
–api-key ${VLLM_API_KEY}
十二、常见报错排查

| 问题 | 可能原因 | 处理办法 |
| No CUDA GPUs are available | 容器未拿到 GPU;驱动或 nvidia-container-toolkit 异常 | 先跑 docker –gpus all nvidia/cuda… nvidia-smi,确认容器可见 GPU |
| CUDA / torch 版本冲突 | 复用旧环境、PyTorch 与 vLLM wheel 不匹配 | 新建虚拟环境;优先用 Docker;不要混装多个 CUDA/Torch |
| 显存不足 / OOM | 模型过大、上下文过长、并发过高 | 换小模型;降低 max_model_len;用量化;减少并发 |
| HTTP 401/403 下载失败 | 模型需要 Hugging Face 授权或 Token 无效 | 申请模型权限;设置 HF_TOKEN;检查容器环境变量 |
| chat template 报错 | 模型不是 chat/instruct 或 tokenizer 缺模板 | 换 instruct 模型;手动指定 –chat-template |
| 接口能访问但响应慢 | 模型太大、CPU/RAM/磁盘/网络瓶颈 | 观察 GPU 利用率、显存、日志;从小模型重新验证 |
十三、FAQ:新手最常问的问题
1. vLLM 能在 Windows 直接安装吗?
官方 GPU 安装文档说明 vLLM 不支持 Windows 原生运行。Windows 用户建议使用 WSL2、Linux 服务器或云 GPU。
2. 没有 NVIDIA 显卡能用吗?
可以尝试 CPU 路线或 AMD/Intel 平台,但新手和生产场景最省心的是 Linux + NVIDIA CUDA + Docker。CPU 路线更适合功能验证,不适合高并发。
3. vLLM 和 Ollama 可以同时安装吗?
可以。Ollama 适合个人本地模型和快速测试,vLLM 适合 API 服务和高并发。二者端口不要冲突即可。
4. 为什么推荐 Docker?
Docker 镜像已经打包依赖,能明显降低 CUDA、PyTorch、Python 版本冲突。新手先用 Docker 跑通,再考虑源码或 Python 安装。
5. 模型越大效果就越好吗?
不一定。模型大小、任务类型、量化、上下文、提示词、推理参数都会影响效果。网站服务更应关注稳定、成本和响应速度。
6. vLLM 可以接 Open WebUI、Dify、LangChain 吗?
可以。只要对方支持 OpenAI 兼容 API,一般把 base_url 改成 vLLM 地址即可。具体字段要按平台设置。
7. 生产环境是否需要 Nginx?
建议需要。Nginx 或 API 网关可以做 HTTPS、反向代理、限流、鉴权、日志和多服务转发。
8. 如何判断显存够不够?
先用小模型验证链路,再按模型参数量、量化格式、上下文长度和并发量逐步压测。真实业务请求比理论估算更可靠。
十四、相关阅读
• Ollama本地部署大模型完整教程:/ollama-local-llm-deployment-guide/
• 本地部署DeepSeek的详细步骤:/local-deploy-deepseek-guide/
• LM Studio安装与本地模型使用教程:/lm-studio-install-local-model-guide/
• VSCode里安装AI编程插件全流程:/vscode-ai-coding-plugins-install-guide/
• IDEA里安装AI编程插件全流程:/idea-ai-coding-plugins-install-guide/
• Windows电脑如何安装常见AI工具:/windows-ai-tools-install-guide/
• Mac电脑安装AI工具完整教程:/mac-ai-tools-install-guide/
十五、SEO 文档
| SEO字段 | 内容 |
| 文章摘要 | 本文是一篇面向新手和开发者的 vLLM 本地部署教程,系统讲解 vLLM 的适用场景、硬件准备、Docker 快速部署、Python 安装、OpenAI 兼容 API 调用、模型选择、性能优化、生产部署建议和常见报错排查。 |
| 主标题 | vLLM部署教程:高性能本地AI服务搭建指南 |
| 爆款标题 | 别再只会 Ollama:vLLM 本地部署高并发 AI 服务完整教程 |
| 别名 / Slug | vllm-local-ai-service-deployment-guide |
| 分类 | 保姆级教程 / 安装部署教程;AI工具库 / AI编程与开发工具;实战工作流 / 自动化工作流 |
| 标签 | vLLM、本地部署、大模型部署、AI服务、OpenAI兼容API、Docker部署、GPU推理、模型推理服务、RAG、私有化部署 |
| SEO标题 | vLLM部署教程:高性能本地AI服务搭建指南(Docker + OpenAI API) |
| SEO描述 | 想把本地大模型部署成可调用的高性能 AI 服务?本文从环境准备、Docker 启动、模型加载、OpenAI 兼容 API、Python 调用到性能优化和报错排查,完整讲解 vLLM 本地部署流程。 |
| 5个关键词 | vLLM部署教程, 本地大模型部署, OpenAI兼容API, Docker部署AI服务, 高性能AI推理 |
| 特色图替代文本 | vLLM 高性能本地 AI 服务部署教程封面图,展示模型、GPU、vLLM 引擎和 OpenAI API 调用链路 |
| 特色图标题 | vLLM部署教程:高性能本地AI服务搭建指南 |
| 特色图说明 | 本文适合希望搭建本地大模型 API 服务的开发者和企业用户,重点讲解 vLLM 的安装部署与接口调用。 |
| 特色图描述 | 一张科技风封面图,包含 GPU 服务器、模型权重、vLLM 引擎、OpenAI API 和业务应用的部署流程。 |
| 推荐URL | /vllm-local-ai-service-deployment-guide/ |
| 面向读者 | AI 工具站长、后端开发者、算法工程师、独立开发者、企业内部知识库负责人 |
| 搜索意图 | 用户想了解如何在本地或服务器上部署 vLLM,并将本地模型封装为可被应用调用的高性能 API 服务。 |
十六、发布前检查清单
- 文中命令里的模型 ID、端口、API Key 已按自己的环境修改。
- 如果发布到网站,代码块建议使用等宽字体和横向滚动。
- 封面图 ALT 文本已填写,便于搜索引擎识别。
- 相关阅读使用站内相对路径,发布后检查链接是否存在。
- 官方参考来源保留在文末,避免读者安装时遇到版本变化。
十七、官方参考来源
- vLLM Installation: https://docs.vllm.ai/en/latest/getting_started/installation/
- vLLM GPU Installation: https://docs.vllm.ai/en/latest/getting_started/installation/gpu/
- vLLM CPU Installation: https://docs.vllm.ai/en/latest/getting_started/installation/cpu/
- vLLM Docker Deployment: https://docs.vllm.ai/en/stable/deployment/docker/
- vLLM OpenAI-Compatible Server: https://docs.vllm.ai/en/latest/serving/openai_compatible_server/
- vLLM Quantization: https://docs.vllm.ai/en/latest/features/quantization/
- vLLM GitHub: https://github.com/vllm-project/vllm

vLLM部署教程:高性能本地AI服务搭建指南
从零搭建 OpenAI 兼容本地推理 API,适合开发者、AI工具站与企业内部应用
别再只会 Ollama:vLLM 本地部署高并发 AI 服务完整教程
如果你只是想在电脑上和本地模型聊天,Ollama、LM Studio 已经足够好用;但如果你想把本地大模型做成一个可被网站、工作流、RAG 系统、代码插件或内部业务系统调用的高性能 API 服务,vLLM 就是更偏“工程化”和“生产化”的选择。
vLLM 的核心定位不是“桌面聊天软件”,而是面向大模型推理和在线服务的高吞吐引擎。它更适合处理多用户并发、API 调用、批处理、服务端部署、GPU 资源利用率优化等场景。
| 本文目标:用一篇教程讲清 vLLM 是什么、适合谁、需要什么硬件、如何用 Docker 快速部署、如何启动 OpenAI 兼容接口、如何用 Python 调用,以及常见报错如何排查。 |
目录
- 1. vLLM 是什么,和 Ollama/LM Studio 有什么区别
- 2. 安装前准备:系统、GPU、驱动、Docker 与模型账号
- 3. 路线一:Docker 快速部署 vLLM 服务
- 4. 路线二:Python 环境安装 vLLM
- 5. 启动 OpenAI 兼容 API 服务
- 6. 用 Python / curl 调用本地模型
- 7. 模型选择、量化与显存估算
- 8. 性能优化:并发、上下文、KV Cache 与多卡
- 9. 常见报错排查
- 10. FAQ、相关阅读与 SEO 文档
一、vLLM 是什么?适合哪些人使用
vLLM 是一个面向大语言模型推理与服务的开源引擎,强调高吞吐、内存效率和易于部署。它最常见的用法,是把 Hugging Face 上的模型启动成一个 OpenAI 兼容 API 服务,然后让前端、RAG、工作流平台、企业系统或代码工具调用。
- 适合开发者:想把本地模型封装成 API,供前端或后端项目调用。
- 适合 AI 工具站:想搭建一个可持续调用的本地推理服务,而不是每次手动打开聊天软件。
- 适合企业内部:需要私有化部署、权限控制、日志监控和多用户并发。
- 适合进阶玩家:想研究吞吐、KV Cache、张量并行、量化、OpenAI 兼容协议等。
二、vLLM、Ollama、LM Studio 怎么选
| 工具 | 最适合场景 | 优势 | 限制 |
| Ollama | 个人本地模型、快速拉模型、命令行体验 | 安装简单,模型管理方便,适合入门 | 更偏个人/轻服务,复杂并发和生产部署能力有限 |
| LM Studio | 桌面端本地聊天、模型下载、OpenAI 兼容本地 API | 图形界面友好,适合非程序员 | 高并发和生产化部署不是主要定位 |
| vLLM | 服务端推理、API 服务、多用户并发、企业内部部署 | 吞吐高,支持 OpenAI 兼容 API、Docker、多卡、量化等 | 安装门槛更高,最好有 Linux 和 NVIDIA GPU 环境 |
| 简单判断:只想本机聊天选 LM Studio 或 Ollama;想给网站/工作流/插件提供统一模型接口,优先考虑 vLLM。 |
三、安装前准备:先确认这 6 件事
vLLM 对运行环境的要求比普通桌面工具高。部署前先确认系统、Python、GPU、驱动、Docker、模型权限这几项,能避免一半以上的报错。
| 检查项 | 推荐配置 | 验证命令/说明 |
| 系统 | Linux 服务器、Ubuntu 22.04/24.04,Windows 用户建议 WSL2 | vLLM 官方 GPU 安装要求为 Linux;Windows 原生不支持 |
| Python | 3.10 – 3.13;新环境优先 Python 3.12 | python3 –version |
| GPU | NVIDIA CUDA 最稳;生产建议 24GB+ 显存 | nvidia-smi |
| 驱动/CUDA | 优先使用官方 Docker 镜像减少依赖冲突 | Docker 路线不必手动装完整 CUDA Toolkit |
| Docker | Docker Engine + NVIDIA Container Toolkit | docker –version;docker run –gpus all … |
| 模型权限 | 公开模型可直接下载;受限模型需要 Hugging Face Token | export HF_TOKEN=你的token |
官方 GPU 文档列出 vLLM 的基础要求包括 Linux、Python 3.10-3.13;NVIDIA CUDA 方向要求计算能力 7.5 或以上,Windows 原生不支持,需要通过 WSL 或其他方式运行。
- 个人测试:RTX 3060/4060/4070/4080/4090 这类显卡可以从小模型开始。
- 团队服务:优先 24GB、48GB、80GB 以上显存,模型越大、上下文越长、并发越高,对显存要求越高。
- 生产部署:建议单独 Linux 服务器,不建议在日常办公电脑上长期跑高并发服务。

四、路线一:Docker 快速部署 vLLM 服务(新手推荐)
如果你是第一次部署 vLLM,最推荐先用官方 Docker 镜像。好处是依赖已经打包好,减少 CUDA、PyTorch、Python 环境冲突。
1. 安装并验证 Docker 与 GPU
在 Linux 服务器上安装 Docker 和 NVIDIA Container Toolkit 后,先确认宿主机能看到 GPU:
nvidia-smi
docker –version
再用一个带 GPU 的容器测试 Docker 是否能调用显卡:
docker run –rm –gpus all nvidia/cuda:12.4.1-base-ubuntu22.04 nvidia-smi
如果这一步失败,不要急着装 vLLM,先处理驱动、Docker、nvidia-container-toolkit 的问题。
2. 准备 Hugging Face Token(可选但建议)
如果模型是公开模型,可能不需要 Token;如果模型需要申请授权,或者你希望稳定拉取模型,建议设置 HF_TOKEN。
export HF_TOKEN=”你的_HuggingFace_Token”
3. 用官方镜像启动 vLLM
下面用 Qwen/Qwen3-0.6B 做示例,它体积较小,适合第一次验证服务是否跑通:
docker run –runtime nvidia –gpus all \
-v ~/.cache/huggingface:/root/.cache/huggingface \
–env “HF_TOKEN=$HF_TOKEN” \
-p 8000:8000 \
–ipc=host \
vllm/vllm-openai:latest \
–model Qwen/Qwen3-0.6B
| 为什么要加 –ipc=host:vLLM 底层使用 PyTorch,张量并行等场景会用到共享内存。官方 Docker 文档说明可以使用 –ipc=host 或 –shm-size,让容器访问足够的共享内存。 |
4. 固定版本更适合生产
教程测试可以使用 latest,但生产环境建议固定镜像版本,避免一次拉镜像后行为变化。示例:
docker pull vllm/vllm-openai:v0.11.0
# 生产环境建议把镜像、模型、启动参数都写入 docker compose 或部署脚本
五、路线二:Python 环境安装 vLLM(开发者路线)
如果你要改 vLLM 代码、做插件开发、调试源码或不想用 Docker,可以走 Python 环境安装。新手不建议直接在系统 Python 里装,务必使用干净虚拟环境。
1. 创建虚拟环境
官方文档推荐使用 uv 创建和管理 Python 环境:
uv venv –python 3.12 –seed –managed-python
source .venv/bin/activate
2. 安装预编译 wheel
NVIDIA CUDA 场景可使用下面的方式安装:
uv pip install vllm –torch-backend=auto
如果使用 pip,官方示例给出 CUDA 12.9 的 extra-index-url:
pip install vllm –extra-index-url https://download.pytorch.org/whl/cu129
| 环境建议:如果你本机已有复杂 PyTorch/CUDA 环境,安装 vLLM 时更容易冲突。优先新建环境;如果需要复用已有 PyTorch,则要更认真检查 CUDA、Torch、vLLM wheel 的兼容性。 |
六、启动 OpenAI 兼容 API 服务
vLLM 很重要的一点是提供 OpenAI 兼容服务。也就是说,很多原本调用 OpenAI SDK 的项目,只要把 base_url 改成本地 vLLM 地址,就可以调用你的本地模型。
vllm serve NousResearch/Meta-Llama-3-8B-Instruct \
–dtype auto \
–api-key token-abc123
服务启动后,默认可以通过类似下面的地址访问:
http://localhost:8000/v1
如果是远程服务器,把 localhost 换成服务器 IP 或域名;生产环境不要直接裸露 8000 端口,建议放在 Nginx、网关或内网服务后面。
七、用 curl 测试接口
服务启动后,先不要急着接业务系统,先用 curl 测试接口是否返回。
curl http://localhost:8000/v1/chat/completions \
-H “Content-Type: application/json” \
-H “Authorization: Bearer token-abc123” \
-d ‘{
“model”: “Qwen/Qwen3-0.6B”,
“messages”: [{“role”: “user”, “content”: “用一句话解释 vLLM 是什么”}],
“temperature”: 0.7
}’
如果这里返回 JSON,说明服务端、模型加载、端口映射和鉴权基本都正常。
八、用 Python 调用本地 vLLM
Python 项目可以继续使用 OpenAI 官方 SDK 的调用习惯,只需要把 base_url 指向本地 vLLM。
from openai import OpenAI
client = OpenAI(
base_url=”http://localhost:8000/v1″,
api_key=”token-abc123″,
)
completion = client.chat.completions.create(
model=”Qwen/Qwen3-0.6B”,
messages=[
{“role”: “user”, “content”: “写一个适合公众号的 AI 工具推荐开头”}
],
)
print(completion.choices[0].message.content)
流式输出示例
stream = client.chat.completions.create(
model=”Qwen/Qwen3-0.6B”,
messages=[{“role”: “user”, “content”: “列出 vLLM 的 3 个优势”}],
stream=True,
)
for chunk in stream:
delta = chunk.choices[0].delta.content
if delta:
print(delta, end=””, flush=True)
九、模型选择、量化与显存估算
vLLM 可以直接加载很多 Hugging Face 模型,但并不是模型越大越好。新手第一次部署建议先小后大:先用 0.5B、1.5B、3B 模型确认服务跑通,再尝试 7B、14B、32B。
模型选择建议
- 只验证部署:选择小模型,缩短下载和加载时间。
- 中文问答:优先选中文能力较好的 instruct/chat 模型。
- 代码能力:选择代码模型或综合能力较强的通用模型。
- 长文本/RAG:关注上下文长度和 KV Cache 占用,不要只看参数量。
- 高并发:同样显存下,较小模型往往能提供更稳定的吞吐。
量化怎么理解
量化可以降低显存占用,常见有 AWQ、GPTQ、FP8、INT8、INT4、GGUF、bitsandbytes 等。vLLM 支持多种量化方式,但不同硬件、模型、量化格式的支持情况会变动,部署前应以官方文档和模型页面为准。
| 实战建议:别一上来就追求“最大模型”。对网站工具或内部应用来说,稳定、低延迟、可维护,比单次回答质量的极限更重要。 |
十、性能优化:从能跑到好用
vLLM 的价值在于高吞吐服务。跑通只是第一步,真正上线还要关注显存、并发、上下文长度、批处理、网络、监控和限流。
| 优化项 | 作用 | 建议 |
| –max-model-len | 限制上下文长度,影响 KV Cache 占用 | 长文本需求明确时再调大;默认过大可能浪费显存 |
| –gpu-memory-utilization | 控制 vLLM 可用 GPU 显存比例 | 显存紧张时降低;生产环境保留余量 |
| –tensor-parallel-size | 多卡张量并行 | 大模型单卡放不下时使用;要求多卡通信稳定 |
| 量化模型 | 降低显存占用 | 优先选择社区验证较多的量化格式 |
| Nginx / 网关 | 鉴权、限流、负载入口 | 不要直接暴露 vLLM 端口到公网 |
| Prometheus / 日志 | 观测吞吐、延迟、错误 | 生产环境必须保留服务日志和指标 |
多卡部署示例
如果模型较大,可以尝试张量并行。示例:
docker run –runtime nvidia –gpus all \
-v ~/.cache/huggingface:/root/.cache/huggingface \
–env “HF_TOKEN=$HF_TOKEN” \
-p 8000:8000 \
–ipc=host \
vllm/vllm-openai:latest \
–model meta-llama/Llama-3.1-70B-Instruct \
–tensor-parallel-size 4
多卡部署不是简单地“卡越多越快”,还要看模型大小、并发、通信开销、PCIe/NVLink、batch 策略等。
十一、生产部署建议:别把测试命令直接上线
- 固定版本:固定 vLLM 镜像版本、模型版本、启动参数,避免更新后接口行为变化。
- 安全边界:本地服务不要直接暴露公网,前面加 Nginx、鉴权、IP 白名单、限流。
- 日志与监控:记录请求量、错误率、平均延迟、显存使用、GPU 利用率。
- 模型缓存:把 Hugging Face 缓存目录挂载出来,避免容器重启后重复下载。
- 灰度切换:新模型先在测试端口运行,确认稳定后再切主服务。
- 容量规划:上线前用真实 prompt、真实并发压测,不要只用单条短问答判断性能。
docker compose 示例
services:
vllm:
image: vllm/vllm-openai:latest
container_name: vllm-server
runtime: nvidia
ipc: host
ports:
– “8000:8000”
environment:
– HF_TOKEN=${HF_TOKEN}
volumes:
– ~/.cache/huggingface:/root/.cache/huggingface
command: >
–model Qwen/Qwen3-0.6B
–dtype auto
–api-key ${VLLM_API_KEY}
十二、常见报错排查

| 问题 | 可能原因 | 处理办法 |
| No CUDA GPUs are available | 容器未拿到 GPU;驱动或 nvidia-container-toolkit 异常 | 先跑 docker –gpus all nvidia/cuda… nvidia-smi,确认容器可见 GPU |
| CUDA / torch 版本冲突 | 复用旧环境、PyTorch 与 vLLM wheel 不匹配 | 新建虚拟环境;优先用 Docker;不要混装多个 CUDA/Torch |
| 显存不足 / OOM | 模型过大、上下文过长、并发过高 | 换小模型;降低 max_model_len;用量化;减少并发 |
| HTTP 401/403 下载失败 | 模型需要 Hugging Face 授权或 Token 无效 | 申请模型权限;设置 HF_TOKEN;检查容器环境变量 |
| chat template 报错 | 模型不是 chat/instruct 或 tokenizer 缺模板 | 换 instruct 模型;手动指定 –chat-template |
| 接口能访问但响应慢 | 模型太大、CPU/RAM/磁盘/网络瓶颈 | 观察 GPU 利用率、显存、日志;从小模型重新验证 |
十三、FAQ:新手最常问的问题
1. vLLM 能在 Windows 直接安装吗?
官方 GPU 安装文档说明 vLLM 不支持 Windows 原生运行。Windows 用户建议使用 WSL2、Linux 服务器或云 GPU。
2. 没有 NVIDIA 显卡能用吗?
可以尝试 CPU 路线或 AMD/Intel 平台,但新手和生产场景最省心的是 Linux + NVIDIA CUDA + Docker。CPU 路线更适合功能验证,不适合高并发。
3. vLLM 和 Ollama 可以同时安装吗?
可以。Ollama 适合个人本地模型和快速测试,vLLM 适合 API 服务和高并发。二者端口不要冲突即可。
4. 为什么推荐 Docker?
Docker 镜像已经打包依赖,能明显降低 CUDA、PyTorch、Python 版本冲突。新手先用 Docker 跑通,再考虑源码或 Python 安装。
5. 模型越大效果就越好吗?
不一定。模型大小、任务类型、量化、上下文、提示词、推理参数都会影响效果。网站服务更应关注稳定、成本和响应速度。
6. vLLM 可以接 Open WebUI、Dify、LangChain 吗?
可以。只要对方支持 OpenAI 兼容 API,一般把 base_url 改成 vLLM 地址即可。具体字段要按平台设置。
7. 生产环境是否需要 Nginx?
建议需要。Nginx 或 API 网关可以做 HTTPS、反向代理、限流、鉴权、日志和多服务转发。
8. 如何判断显存够不够?
先用小模型验证链路,再按模型参数量、量化格式、上下文长度和并发量逐步压测。真实业务请求比理论估算更可靠。
官方参考来源
- vLLM Installation: https://docs.vllm.ai/en/latest/getting_started/installation/
- vLLM GPU Installation: https://docs.vllm.ai/en/latest/getting_started/installation/gpu/
- vLLM CPU Installation: https://docs.vllm.ai/en/latest/getting_started/installation/cpu/
- vLLM Docker Deployment: https://docs.vllm.ai/en/stable/deployment/docker/
- vLLM OpenAI-Compatible Server: https://docs.vllm.ai/en/latest/serving/openai_compatible_server/
- vLLM Quantization: https://docs.vllm.ai/en/latest/features/quantization/
- vLLM GitHub: https://github.com/vllm-project/vllm
环境配置与 Docker 工作流
适合阅读安装部署、本地配置、服务器搭建和自动化流程类文章后继续转化。
