
《Text Generation WebUI部署教程:本地玩转大模型》

网站发布教程文章 + 封面图 + FAQ + 相关阅读 + SEO 文档
适用对象:想在 Windows / macOS / Linux 上本地运行大模型、搭建私有 AI 对话界面或本地 API 服务的新手与开发者
目录
1. 一、爆款标题与文章摘要
2. 二、Text Generation WebUI 是什么
3. 三、安装前准备:硬件、系统与模型格式
4. 四、四种部署路线:Portable、One-click、Conda、Docker
5. 五、模型下载与加载:GGUF、Safetensors、LoRA
6. 六、WebUI 使用方法:聊天、参数、角色与提示词
7. 七、开启本地 API:接入脚本、插件和工作流
8. 八、性能优化与安全设置
9. 九、常见报错排查
10. 十、FAQ
11. 十一、相关阅读
12. 十二、SEO 文档
13. 十三、官方参考来源
一、文章摘要
文章摘要:Text Generation WebUI,也常被称为 Oobabooga 或 TextGen,是一款老牌本地大模型 Web 界面。它适合想在本机离线运行大模型、加载 GGUF / Safetensors / LoRA、尝试多种后端、开启本地 API、甚至做 LoRA 微调和扩展功能的用户。本文从新手角度出发,完整讲清楚下载安装、模型选择、启动参数、WebUI 使用、本地 API 接入、性能优化和常见报错排查。
一句话定位:如果 Ollama 更像“本地模型命令行服务”,LM Studio 更像“图形化本地模型客户端”,那么 Text Generation WebUI 更像“可折腾、可扩展、可训练、可接 API 的本地大模型控制台”。
二、Text Generation WebUI 是什么
Text Generation WebUI 的核心价值,是把复杂的大模型运行环境包装成浏览器可访问的本地控制台。用户可以在浏览器里加载模型、调整生成参数、切换聊天/指令/笔记本模式、叠加 LoRA、启用扩展,并将本地模型作为 API 服务提供给其他应用调用。
需要注意的是,项目官方主仓库当前显示为 oobabooga/textgen,README 中把它描述为“original local LLM interface”,并强调具备文本、视觉、工具调用、训练、图像生成、UI + API、离线和私有化能力。很多中文教程仍然沿用“Text Generation WebUI”或“Oobabooga”这个叫法,读者搜索时看到不同名称不要误以为是两个项目。
- 适合本地大模型爱好者:可以尝试各种开源模型、量化版本和推理后端。
- 适合开发者:可以打开 API,把本地模型接入 Python、Node.js、VS Code 插件、自动化工作流。
- 适合隐私敏感场景:模型与对话主要在本地运行,不必把全部数据发到云端。
- 适合折腾扩展:支持语音、翻译、角色、训练、图像生成等扩展方向。
不适合谁?如果你只想“双击软件、下载模型、直接聊天”,LM Studio 通常更省心;如果你只想用命令拉模型、跑 API,Ollama 更轻量;如果你要高并发生产服务,vLLM 更适合服务器部署。
三、安装前准备:硬件、系统与模型格式
1. 硬件建议
| 配置类型 | 适合模型 | 体验说明 |
| 普通办公电脑 / 8GB 内存 | 1B-3B 小模型、低量化 GGUF | 能跑,但速度和上下文有限,适合体验。 |
| 16GB 内存 / 无独显 | 3B-7B Q4 GGUF | 新手入门可用,建议选择 llama.cpp 加载。 |
| NVIDIA 8GB 显存 | 7B Q4/Q5、部分 8B 模型 | 聊天体验明显提升,但上下文不要开太大。 |
| NVIDIA 12GB-16GB 显存 | 7B/8B Q5/Q8、14B 低量化 | 适合日常本地助手、代码模型、轻量 RAG。 |
| 24GB+ 显存 | 14B/32B 量化、ExLlamaV3/Transformers | 适合深度折腾、多加载器和更高上下文。 |
| 服务器多卡 | 大模型、多用户、API 服务 | 建议优先评估 vLLM / TGI / Docker 部署。 |
2. 系统建议
- Windows:优先使用 Portable 或 One-click Installer;NVIDIA 显卡用户注意驱动版本与 CUDA/PyTorch 匹配。
- macOS:Apple Silicon 可体验 GGUF / llama.cpp 路线;Intel Mac 性能有限,不建议追求大模型。
- Linux:最适合长期部署和折腾 Docker、NVIDIA、ROCm、依赖编译。
- WSL:Windows 用户想走 Linux 路线时可选,但新手优先用 Windows 便携包更省事。
3. 模型格式先搞清楚
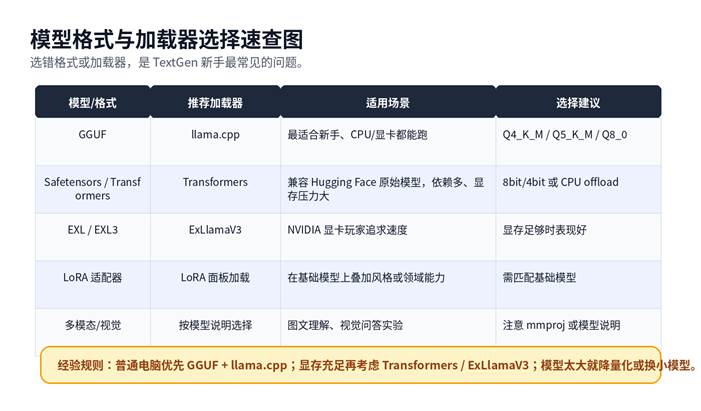
模型格式决定加载器。新手优先找 GGUF 模型,直接放进 user_data/models 文件夹,配合 llama.cpp 使用;多文件 Safetensors 模型需要放在单独子文件夹里,通常需要 Transformers 后端和更完整的依赖。
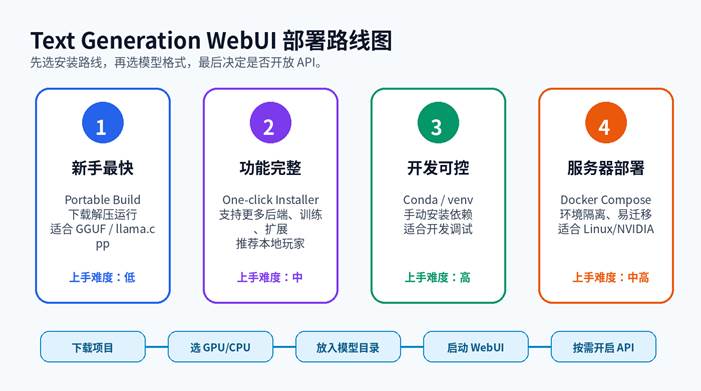
四、四种部署路线:Portable、One-click、Conda、Docker
路线 A:Portable 便携版,最适合新手
官方 README 目前推荐“Zero setup. Download, unzip, run.”的便携构建,提供 Linux、Windows、macOS,以及 CUDA、Vulkan、ROCm、CPU-only 等选项。它包含依赖,主要面向 GGUF / llama.cpp 模型,非常适合第一次上手。
1. 打开 oobabooga/textgen 的 Releases 页面,下载与你系统和硬件匹配的 portable 包。
2. 解压到英文路径,例如 D:\AI\textgen 或 ~/AI/textgen,避免中文路径、空格和权限问题。
3. 下载一个 GGUF 模型文件,放入 user_data/models 文件夹。
4. 运行启动脚本,等待终端显示 Local URL。
5. 浏览器打开 http://127.0.0.1:7860,进入模型加载页面。
适用建议:只想本地聊天、试模型、体验不同提示词的用户,优先选这条路线。
路线 B:One-click Installer,功能更完整
如果你需要 ExLlamaV3、Transformers、训练、图像生成、TTS、语音输入、翻译等扩展功能,建议使用 One-click Installer。官方说明该路线会下载 PyTorch,并在 installer_files 目录中用 Miniforge 建立独立环境。
1. 克隆仓库:git clone https://github.com/oobabooga/textgen
2. 进入目录:cd textgen
3. Windows 运行 start_windows.bat;Linux 运行 ./start_linux.sh;macOS 运行 ./start_macos.sh。
4. 首次启动时按提示选择 GPU 厂商或 CPU 模式。
5. 安装完成后浏览器打开 http://127.0.0.1:7860。
6. 后续更新运行 update_wizard_windows.bat / update_wizard_linux.sh / update_wizard_macos.sh。
注意:官方明确提示不需要以管理员/root 方式运行 start、update 或 cmd 脚本。遇到环境损坏,可以删除 installer_files 文件夹后重新运行 start 脚本。
路线 C:Conda / venv 手动安装,适合开发者
手动安装的优势是可控,适合需要调试依赖、固定版本、二次开发和服务器环境的用户。官方 README 给出了 Python 3.9+ 的 portable venv 快速方式,也给出了 Conda 完整安装路线。
示例:venv 快速安装
git clone https://github.com/oobabooga/textgen
cd textgen
python -m venv venv
# Windows:
venv\Scripts\activate
# macOS/Linux:
source venv/bin/activate
pip install -r requirements/portable/requirements.txt –upgrade
python server.py –portable –api –auto-launch
手动安装需要你自己处理 PyTorch、CUDA、ROCm、Apple Silicon 或 CPU-only 对应依赖。新手遇到依赖冲突时,不要在系统 Python 里硬装,建议使用独立虚拟环境。
路线 D:Docker 部署,适合 Linux 服务器
Docker 的优势是环境隔离、便于迁移和重装。官方 README 提供了 nvidia、amd、intel、cpu 等 Dockerfile / docker-compose.yml 路线,并提示需要 Docker Compose v2.17 或更高版本。
示例:NVIDIA 路线思路
git clone https://github.com/oobabooga/textgen
cd textgen
ln -s docker/nvidia/Dockerfile .
ln -s docker/nvidia/docker-compose.yml .
ln -s docker/.dockerignore .
cp docker/.env.example .env
mkdir -p user_data/logs user_data/cache
# 根据显卡修改 .env 和 user_data/CMD_FLAGS.txt
docker compose up –build
服务器部署时,建议先只绑定本机或内网访问,确认安全后再加反向代理、鉴权和访问控制。
五、模型下载与加载:GGUF、Safetensors、LoRA
1. 下载模型:先从小模型开始
新手不要一上来下载 30B、70B 模型。建议先从 3B、7B、8B 的 GGUF 量化模型开始,例如 Q4_K_M 或 Q5_K_M。模型越大,内存/显存占用越高,加载和生成速度越慢。
- 低配置电脑:1.5B、3B、7B Q4。
- 16GB 内存:7B Q4/Q5 更合适。
- 8GB 显存:7B Q4/Q5,适当降低上下文。
- 16GB 显存:8B、14B 低量化可尝试。
- 24GB+ 显存:可尝试更高量化、更高上下文或 ExLlamaV3 路线。
2. 放置模型文件
GGUF 单文件模型:直接放入 user_data/models 文件夹。WebUI 会自动检测。
多文件 Transformers / Safetensors 模型:需要放在 user_data/models 下的单独子文件夹,例如:
textgen/
└── user_data/
└── models/
└── Qwen_Qwen3-8B/
├── config.json
├── model-00001-of-00004.safetensors
├── tokenizer.json
└── tokenizer_config.json
3. 在 WebUI 中加载模型
1. 打开 WebUI 后进入 Model 页面。
2. 刷新模型列表,选择刚放入的模型。
3. 选择合适加载器:GGUF 通常选 llama.cpp;Safetensors 通常选 Transformers;EXL 模型按说明选 ExLlamaV3。
4. 设置上下文长度、GPU layers、cache 等参数。
5. 点击 Load,等待终端日志显示加载完成。
6. 回到 Chat / Instruct / Notebook 页面测试输出。
4. LoRA 使用思路
LoRA 不是独立大模型,而是叠加在基础模型上的适配器。使用 LoRA 时要确认基础模型架构、版本和 tokenizer 是否匹配。基础模型不匹配时,轻则效果变差,重则加载报错。
六、WebUI 使用方法:聊天、参数、角色与提示词
1. Chat / Instruct / Notebook 怎么选
| 模式 | 适合场景 | 使用建议 |
| Chat | 多轮对话、角色扮演、日常问答 | 适合模拟聊天助手,可保存角色设定。 |
| Instruct | 指令式问答、写作、代码、总结 | 更接近 ChatGPT 的指令模式,适合办公任务。 |
| Notebook | 长文本续写、自由生成、提示词实验 | 适合写小说、生成段落、测试采样参数。 |
| Parameters | 调温度、top_p、top_k、重复惩罚等 | 不要一次改太多,先保存默认值。 |
| Model | 选择模型、加载器、上下文、显存分配 | 加载失败时第一时间回到这里检查。 |
2. 常用生成参数怎么调
| 参数 | 作用 | 新手建议 |
| Temperature | 控制随机性,越高越发散 | 写作 0.7-1.0;问答 0.3-0.7。 |
| Top_p | 限制候选词累计概率 | 常用 0.8-0.95。 |
| Top_k | 限制候选词数量 | 不懂可默认。 |
| Repetition penalty | 减少重复句子和循环 | 重复严重时略微调高。 |
| Context size | 上下文长度 | 越大越吃内存/显存,不要盲目拉满。 |
| Max new tokens | 单次最大输出长度 | 长文可增大,聊天不宜过高。 |
3. 角色与提示词建议
- 角色设定要清晰:说明身份、任务、输出格式、限制条件。
- 复杂任务拆成步骤:先让模型列提纲,再扩写,再润色。
- 本地小模型不要期待“全能”:给足上下文和示例,效果会更稳定。
- 代码任务优先选择代码模型或更强的 instruct 模型。
七、开启本地 API:接入脚本、插件和工作流
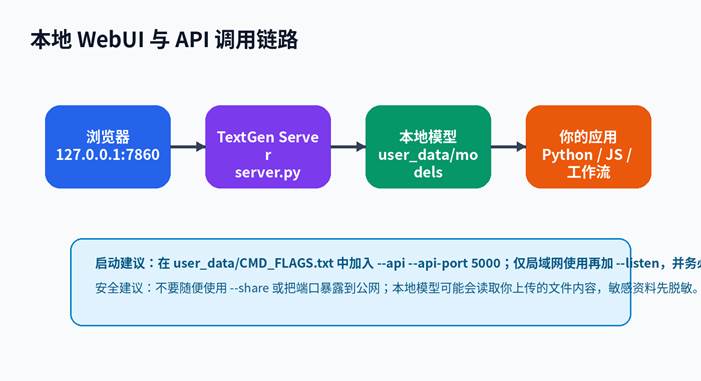
TextGen 支持 OpenAI / Anthropic-compatible API,适合把本地模型作为“本地接口”接入脚本、插件、知识库或自动化工具。官方 README 中说明可以使用 Chat、Completions、Messages 等端点,并通过 –api、–api-port、–api-key 等参数配置。
1. 推荐做法:把启动参数写进 CMD_FLAGS.txt
在 user_data/CMD_FLAGS.txt 中写入:
–api –api-port 5000 –auto-launch
如果只在本机使用,不要加 –listen;如果需要局域网访问,可以加 –listen,并同时设置 –gradio-auth 或 API key。
2. Python 调用示例
from openai import OpenAI
client = OpenAI(
base_url=”http://127.0.0.1:5000/v1″,
api_key=”local-key” # 本地服务可按你的启动参数配置
)
response = client.chat.completions.create(
model=”local-model”,
messages=[{“role”: “user”, “content”: “用三句话介绍 Text Generation WebUI”}],
temperature=0.7,
)
print(response.choices[0].message.content)
3. 可以接入哪些工具
- 本地 Python 脚本:批量生成、摘要、文本分类、数据清洗。
- VS Code / IDEA 插件:部分插件支持自定义 OpenAI-compatible base_url。
- RAG 知识库:让本地检索系统调用 TextGen 模型生成回答。
- 自动化工作流:n8n、Dify、Flowise、LangChain 等可按兼容接口配置。
八、性能优化与安全设置
1. 性能优化优先级
1. 先换合适模型:大模型不一定比小模型更适合你的电脑。
2. 优先用 GGUF + llama.cpp:兼容性强,入门门槛低。
3. 降低量化等级:从 Q8 降到 Q5 或 Q4,显存压力会明显降低。
4. 降低上下文长度:上下文越大,KV cache 越占内存/显存。
5. 合理设置 gpu-layers:显存不够就少放几层到 GPU。
6. 减少同时请求:本地消费级显卡不适合高并发。
2. 安全设置
- 默认本机访问即可,不要随意把服务暴露到公网。
- 局域网访问时,必须设置账号密码或 API key。
- 谨慎使用 –share,它会创建外部可访问链接,适合临时演示,不适合长期使用。
- 上传 PDF、Word 或文本文件前,先确认其中没有敏感信息。
- 下载第三方模型时,优先选择可信发布者,谨慎启用 trust_remote_code。
3. 文件管理建议
- 模型统一放在 user_data/models,便于备份和迁移。
- 角色、配置、日志、扩展不要混放到系统目录。
- 升级前备份 user_data 文件夹。
- 环境坏了优先重建 installer_files,不要把系统 Python 搞乱。
九、常见报错排查
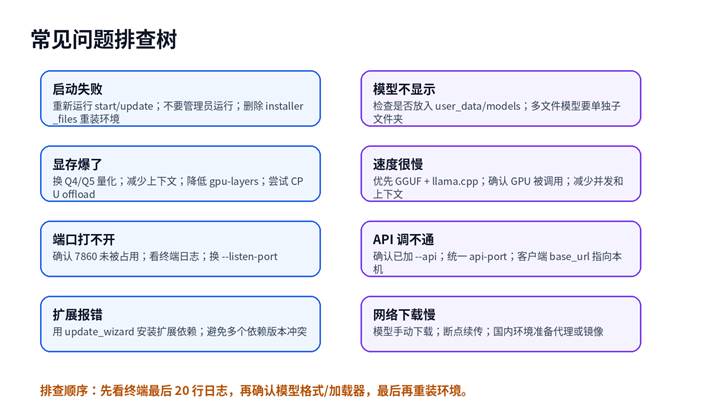
| 问题 | 可能原因 | 解决方法 |
| 启动脚本闪退 | 路径权限、依赖下载失败、环境损坏 | 放到英文路径;重新运行 start/update;删除 installer_files 后重装。 |
| 浏览器打不开 7860 | 服务未启动、端口被占用、防火墙拦截 | 看终端 URL;换 –listen-port;放行本地防火墙。 |
| 模型列表为空 | 模型目录放错、格式不对 | GGUF 放 user_data/models;多文件模型放单独子文件夹。 |
| 加载模型显存不足 | 模型太大、上下文太高、量化过高 | 换 Q4/Q5;降低 ctx-size;减少 gpu-layers。 |
| 生成速度极慢 | CPU 跑大模型、未调用 GPU、上下文过大 | 换小模型;检查 GPU;使用 llama.cpp;降低上下文。 |
| Transformers 报依赖错 | PyTorch/CUDA/requirements 不匹配 | 使用 update wizard;按 GPU 选择对应 requirements。 |
| 扩展安装失败 | 扩展依赖冲突、网络中断 | 用更新脚本安装扩展依赖;必要时单独开 cmd 脚本排查。 |
| API 404/连接失败 | 未启用 –api、端口不一致 | 在 CMD_FLAGS.txt 加 –api –api-port 5000,客户端 base_url 保持一致。 |
十、FAQ
Q1:Text Generation WebUI 和 TextGen 是同一个吗?
可以这样理解。官方主仓库现在显示为 oobabooga/textgen,很多用户仍称它为 Text Generation WebUI 或 Oobabooga。搜索教程时,这几个名字经常混用。
Q2:新手应该选择哪种安装方式?
优先选择 Portable 便携版。如果你需要训练、扩展、Transformers、ExLlamaV3 等高级功能,再使用 One-click Installer。
Q3:为什么我下载的模型加载不了?
最常见原因是模型格式与加载器不匹配。GGUF 通常选 llama.cpp;Safetensors 多文件模型通常要放入独立文件夹,并用 Transformers 加载。
Q4:没有显卡能不能用?
可以,但要选择小模型和低量化 GGUF。CPU 模式能体验,但速度通常不如显卡。
Q5:它能替代 Ollama 吗?
不完全替代。Ollama 更轻量,适合命令行和本地 API;TextGen 更像功能丰富的 Web 控制台,适合多加载器、扩展、训练和参数调试。
Q6:它能替代 LM Studio 吗?
如果你更重视简单易用,LM Studio 更友好;如果你更重视可折腾、参数、扩展、加载器和训练,TextGen 更合适。
Q7:本地 API 可以给网站或插件用吗?
可以。建议使用 OpenAI-compatible 接口,并显式指定 base_url、api-port 和鉴权方式。
Q8:可以公网访问吗?
技术上可以,但不建议新手直接暴露端口。至少要设置密码、API key、反向代理和防火墙规则。
Q9:更新后坏了怎么办?
先运行 update wizard;如果仍有问题,备份 user_data,然后删除 installer_files 重建环境。
Q10:模型下载很慢怎么办?
可以手动下载模型文件后放入 user_data/models;大模型建议使用支持断点续传的下载工具。
官方参考来源
- oobabooga/textgen GitHub 主仓库:https://github.com/oobabooga/textgen
- TextGen Releases / Portable Builds:https://github.com/oobabooga/textgen/releases
- PyTorch 官方安装命令:https://pytorch.org/get-started/locally/
- Miniforge 官方发布页:https://github.com/conda-forge/miniforge/releases/latest
- Docker Compose 安装文档:https://docs.docker.com/compose/install/
- Hugging Face 模型库:https://huggingface.co/models
环境配置与 Docker 工作流
适合阅读安装部署、本地配置、服务器搭建和自动化流程类文章后继续转化。
