
《LocalAI部署教程:把开源模型变成本地API服务》
网站发布教程文章 + SEO 文档

封面图:LocalAI 本地 API 服务部署教程
本文适合想把开源模型部署成私有 API 服务的用户:既可以用于个人本地开发,也可以作为企业内网 AI 应用、知识库问答、Agent 工具调用和自媒体 AI 工具站的后端服务。
一、文章摘要与发布信息
一句话摘要:LocalAI 可以把多种开源模型封装成本地 OpenAI 兼容 API 服务,让网站、脚本、RAG 应用和企业内网系统像调用云端 API 一样调用本地模型。
| 项目 | 内容 |
| 推荐标题 | 不用买云端 API,也能搭建自己的 AI 接口:LocalAI 本地部署完整教程 |
| 主标题 | LocalAI部署教程:把开源模型变成本地API服务 |
| 适合人群 | 开发者、AI 工具站站长、企业内网运维、自媒体技术博主、本地大模型玩家 |
| 核心关键词 | LocalAI部署, 本地AI API, OpenAI兼容API, Docker部署大模型, 开源模型服务 |
| 文章分类 | 保姆级教程 / 安装部署教程;实战工作流 / 自动化工作流;AI资源库 / 开源模型资源 |
二、先说结论:LocalAI适合什么场景?
LocalAI 不是单纯的聊天客户端,而是一个本地 AI 服务网关。它的核心价值,是把本地模型、开源模型、图片模型、语音模型、Embedding 模型等能力,统一暴露成兼容 OpenAI 风格的接口。
- 想把本地模型接入自己的网站、公众号自动发文脚本、企业 CRM、知识库问答系统,优先考虑 LocalAI。
- 只想在电脑上和本地模型聊天,LM Studio 或 Ollama 更简单。
- 需要极致推理吞吐、高并发服务,尤其是多 GPU 服务器,可考虑 vLLM。
- 想要“一个本地 AI API 入口”,同时覆盖聊天、向量、图片、音频、Agents,LocalAI 更合适。
| 工具 | 定位 | 优点 | 适合人群 |
| Ollama | 本地模型运行器 | 命令简单、模型拉取方便、生态广 | 个人开发者、本地学习 |
| LM Studio | 桌面图形化本地模型工具 | 下载模型、聊天、开 API 都很直观 | 零基础用户、内容创作者 |
| vLLM | 高性能推理服务 | 吞吐高、适合生产并发 | 服务器部署、企业推理平台 |
| LocalAI | 本地 AI API 中枢 | OpenAI 兼容、WebUI、模型管理、多模态能力 | 开发者、内网 AI 服务、工具站后端 |
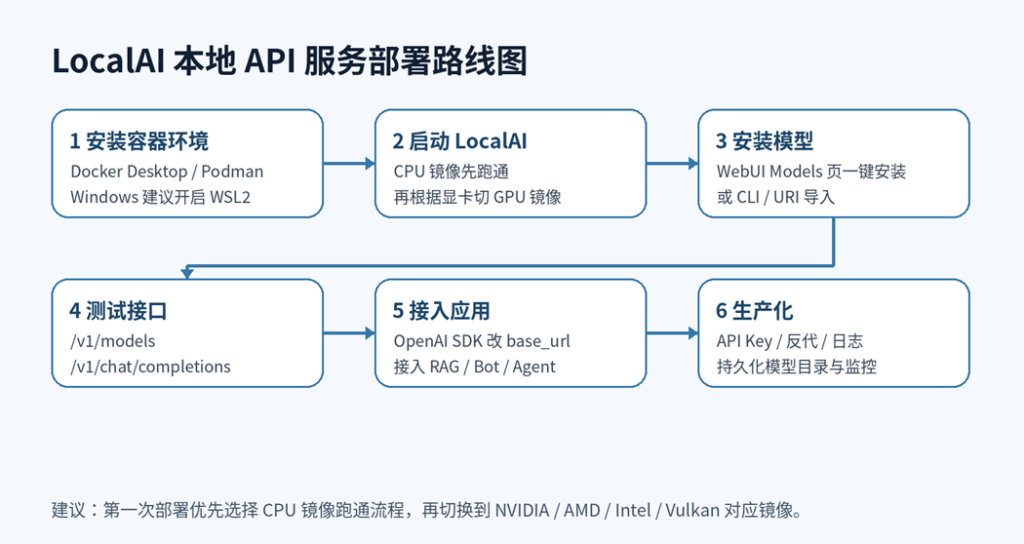
图1:LocalAI 推荐部署路线图
三、LocalAI是什么?
LocalAI 可以理解为“本地版 OpenAI API 服务层”。你可以在自己的电脑或服务器上运行模型,再通过 HTTP API 给网站、脚本、插件或内部系统调用。它重点解决三个问题:
- 统一入口:不同模型、不同后端、不同能力,都通过 LocalAI 对外提供服务。
- 兼容生态:现有 OpenAI SDK、聊天应用、RAG 框架,大多只需要修改 base_url 即可接入。
- 私有可控:数据留在本机或内网,适合对数据安全、成本控制和模型可控性有要求的场景。
截至本文整理时,LocalAI 官方文档强调它是一个可通过单个二进制或容器运行的本地 AI 栈,提供 OpenAI 兼容 API、内置 Web 界面、模型管理、Agent、GPU 加速、分布式模式以及多种模型能力。
四、安装前准备:硬件、系统与软件
| 准备项 | 最低可用 | 推荐配置 | 说明 |
| 系统 | Windows / macOS / Linux + Docker | Linux 服务器或 Windows + WSL2 + Docker Desktop | 新手建议 Docker 路线,跨平台最省心 |
| CPU | 4 核以上 | 8 核以上 | CPU 可以跑,但响应速度取决于模型大小与量化等级 |
| 内存 | 8GB | 16GB / 32GB+ | 7B Q4 模型建议 16GB 起步,多模型建议 32GB+ |
| 显卡 | 非必须 | NVIDIA 8GB+ 显存 | GPU 不是必须,但能显著提升推理速度 |
| 磁盘 | 20GB 可用空间 | 100GB+ SSD | 模型文件通常几个 GB 到几十 GB |
| 网络 | 能访问模型源 | 稳定外网或可配置镜像源 | 首次下载模型与镜像需要网络 |
新手建议:第一次不要一上来就部署 32B 或 70B 模型。先用 1B、3B、7B 的量化模型跑通流程,再根据硬件升级模型。
五、部署方式选择:Docker优先,其次二进制/源码
LocalAI 支持多种安装方式,但对大多数网站读者来说,Docker 是最稳妥的路线。原因是环境隔离好、卸载容易、迁移方便,并且官方文档也把 Docker 作为多数用户的推荐安装方式。
| 方式 | 难度 | 适合场景 | 建议 |
| Docker run | 低 | 快速体验、本地测试 | 最推荐新手 |
| Docker Compose | 中 | 长期运行、挂载模型目录、反向代理 | 推荐生产/内网部署 |
| Podman | 中 | Linux 服务器、无 Docker 环境 | 适合运维用户 |
| 二进制/源码 | 高 | 定制构建、特殊硬件、开发贡献 | 不建议零基础优先选择 |
六、Docker 快速部署 LocalAI(CPU 版)
这是最适合新手的启动方式:先用 CPU 镜像确认 LocalAI 能访问,再安装模型并测试 API。
1. 安装 Docker Desktop 或 Docker Engine
- Windows:安装 Docker Desktop,并启用 WSL2 后端。
- macOS:安装 Docker Desktop,Apple Silicon 用户注意选择 arm64 版本。
- Linux:可安装 Docker Engine 或 Podman。
2. 启动 LocalAI 容器
docker run -p 8080:8080 –name local-ai -ti localai/localai:latest-cpu
如果你看到服务启动日志,说明容器已经运行。然后打开浏览器访问:
http://localhost:8080
在 WebUI 中进入 Models 页面,选择一个小模型安装。安装完成后,回到 Chat 页面测试对话。
3. 检查容器状态
docker ps
docker logs local-ai
如果容器没有运行,可以先删除旧容器后重新启动:
docker rm -f local-ai
docker run -p 8080:8080 –name local-ai -ti localai/localai:latest-cpu
七、Docker Compose 长期部署方案
如果你准备长期使用 LocalAI,建议使用 Docker Compose,并把模型目录挂载到宿主机,避免容器重建后模型丢失。
mkdir -p localai/models
cd localai
cat > docker-compose.yml <<‘YAML’
services:
localai:
image: localai/localai:latest-cpu
container_name: local-ai
ports:
– “8080:8080”
volumes:
– ./models:/models
environment:
– DEBUG=true
restart: unless-stopped
YAML
docker compose up -d
部署完成后访问 http://localhost:8080。后续模型文件会保存在当前目录的 models 文件夹。
八、GPU 加速部署:NVIDIA、AMD、Intel 怎么选?
LocalAI 的 GPU 路线主要看你的显卡类型。官方文档中列出了 CPU、NVIDIA CUDA、AMD ROCm、Intel GPU、Vulkan 等镜像/后端选择。一般用户最常见的是 NVIDIA CUDA。
| 硬件类型 | 推荐方向 | 示例镜像/注意点 |
| 无独立显卡 | CPU 镜像 | localai/localai:latest-cpu,适合先跑通流程 |
| NVIDIA 显卡 | CUDA 镜像 | 使用 NVIDIA/CUDA 镜像,并在 docker run 中加入 –gpus all |
| AMD 显卡 | ROCm / HIPBLAS | 需要系统和驱动支持,Linux 环境更常见 |
| Intel GPU | Intel/SYCL 相关镜像 | 适合特定 Intel GPU 环境 |
| Apple Silicon | 优先查官方 Mac/构建说明 | Docker 中 GPU 加速限制较多,个人桌面建议先 CPU 或专用客户端 |
NVIDIA 示例命令:
docker run –gpus all -p 8080:8080 –name local-ai -ti localai/localai:latest-gpu-nvidia-cuda-12
显卡没有生效时,先确认宿主机能运行 nvidia-smi,再确认 Docker 能把 GPU 暴露给容器。
九、安装模型:WebUI 一键安装、CLI安装、URI导入
LocalAI 支持从内置模型库安装模型,也支持通过 URI 导入 Hugging Face、Ollama、YAML 配置、OCI 等来源。对新手来说,最推荐 WebUI Models 页面一键安装。
方式1:WebUI安装模型
- 打开 http://localhost:8080。
- 进入顶部导航栏的 Models 页面。
- 选择一个体积较小的模型,例如 1B、3B、7B 量化模型。
- 点击 Install,等待下载和后端初始化。
- 回到 Chat 页面选择模型测试。
方式2:CLI安装模型
local-ai models list
local-ai models install llama-3.2-1b-instruct:q4_k_m
local-ai run llama-3.2-1b-instruct:q4_k_m
方式3:通过 URI 导入模型
local-ai run huggingface://TheBloke/phi-2-GGUF/phi-2.Q8_0.gguf
local-ai run ollama://gemma:2b
local-ai run oci://localai/phi-2:latest
注意:模型许可非常重要。商业网站或企业使用前,要确认模型许可证是否允许商用、是否要求署名、是否存在地域或用途限制。
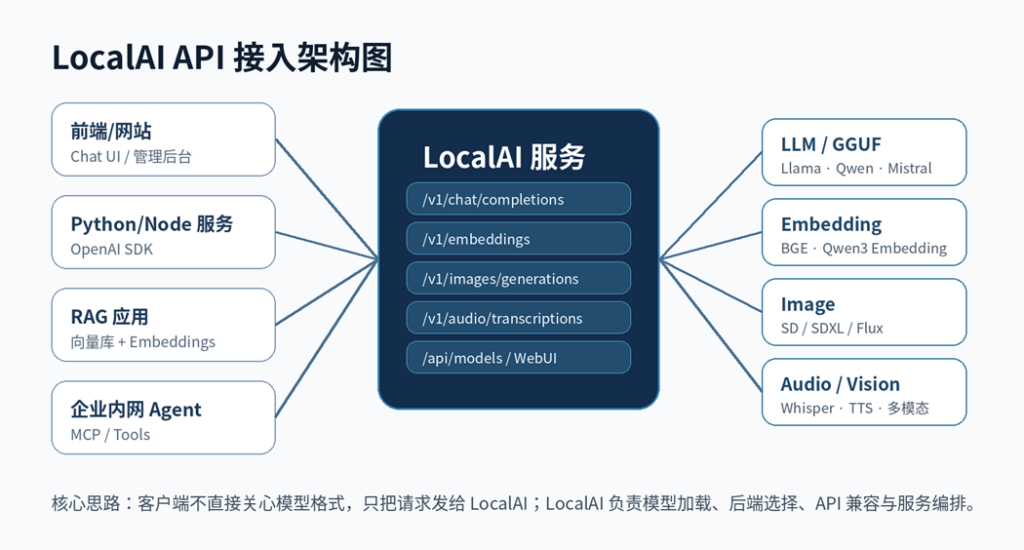
图2:LocalAI API 接入架构图
十、测试 OpenAI 兼容 API
LocalAI 的核心玩法,是把本地模型通过 API 提供给外部程序。最常用的接口是 /v1/chat/completions 和 /v1/models。
1. 查看模型列表
curl http://localhost:8080/v1/models
2. 调用聊天接口
curl http://localhost:8080/v1/chat/completions \
-H “Content-Type: application/json” \
-d ‘{
“model”: “llama-3.2-1b-instruct:q4_k_m”,
“messages”: [
{“role”: “user”, “content”: “用三句话介绍 LocalAI”}
],
“temperature”: 0.7
}’
3. Python SDK 接入示例
很多 OpenAI 兼容应用只需要把 base_url 改成本地地址。实际模型名以 /v1/models 返回结果为准。
from openai import OpenAI
client = OpenAI(
base_url=”http://localhost:8080/v1″,
api_key=”localai” # 本地测试可随意填写;生产环境请配置真实鉴权
)
resp = client.chat.completions.create(
model=”llama-3.2-1b-instruct:q4_k_m”,
messages=[{“role”: “user”, “content”: “写一个 LocalAI 的部署说明”}],
)
print(resp.choices[0].message.content)
4. Node.js 接入示例
import OpenAI from “openai”;
const client = new OpenAI({
baseURL: “http://localhost:8080/v1”,
apiKey: “localai”
});
const completion = await client.chat.completions.create({
model: “llama-3.2-1b-instruct:q4_k_m”,
messages: [{ role: “user”, content: “你好,LocalAI” }]
});
console.log(completion.choices[0].message.content);
十一、Embedding、图片、音频与 Agent 能力
LocalAI 不只适合聊天模型。根据官方功能文档,它还支持 Embeddings、图像生成、音频转文字、文本转语音、工具调用、MCP、Agents 等能力。做网站或企业应用时,建议分阶段启用:
| 能力 | 典型用途 | 接口/入口 | 建议 |
| 聊天生成 | 客服、写作、代码解释、自动发文 | /v1/chat/completions | 先跑通这个 |
| Embeddings | 知识库检索、RAG、相似度搜索 | /embeddings 或兼容接口 | 搭配向量数据库使用 |
| 图片生成 | 封面图、素材生成、海报图 | /v1/images/generations | 注意模型体积和显存 |
| 音频处理 | 语音转文字、TTS | Audio 相关接口 | 适合内容生产链路 |
| Agents/MCP | 自动工具调用、任务执行 | WebUI Agents / MCP | 先小范围测试再生产化 |
Embedding 调用示例
curl http://localhost:8080/embeddings \
-X POST \
-H “Content-Type: application/json” \
-d ‘{
“input”: “这是一段需要向量化的文本”,
“model”: “qwen3-embedding-0.6b”
}’
图片生成调用示例
curl http://localhost:8080/v1/images/generations \
-H “Content-Type: application/json” \
-d ‘{
“prompt”: “a clean futuristic local AI server dashboard, blue neon, 16:9”,
“size”: “512×512”
}’
十二、把 LocalAI 接入 Open WebUI、Dify、LangChain、WordPress 自动化
只要工具支持 OpenAI 兼容 API,通常就能接入 LocalAI。通用配置逻辑如下:
| 配置项 | 填写示例 | 说明 |
| API Base URL | http://localhost:8080/v1 | 如果是容器互联,可能要写服务名或宿主机地址 |
| API Key | localai 或你设置的密钥 | 本地测试可随意,生产环境必须启用鉴权 |
| Model | 以 /v1/models 返回为准 | 不要凭记忆填写模型名 |
| Timeout | 60-180 秒 | 本地模型首 token 较慢时要放宽超时 |
| Streaming | 建议开启 | 前端体验更好 |
以 WordPress 自动发文为例:脚本不需要知道底层是 Qwen、Llama 还是 Mistral,只要请求 LocalAI 的 chat completions 接口,就能把标题生成、正文润色、摘要生成、标签推荐等流程私有化。
十三、生产化部署建议:不要只跑通,还要跑稳
- 模型目录持久化:Docker Compose 中挂载 /models,避免容器更新导致模型丢失。
- 接口鉴权:内网测试可以宽松,公网或多人使用必须开启 API Key、反向代理和访问控制。
- 反向代理:可用 Nginx、Caddy、Traefik,把 https://ai.example.com/v1 转发到 LocalAI。
- 日志与监控:记录请求耗时、错误率、显存占用、模型加载时间。
- 模型分层:聊天模型、Embedding 模型、图片模型分开配置,避免一个服务承担所有负载。
- 并发控制:本地小机器不适合无限并发,可在上层网关做限流。
- 备份策略:备份模型配置 YAML、Compose 文件、反向代理配置和环境变量。
Nginx 反向代理示例
server {
listen 80;
server_name ai.example.com;
location / {
proxy_pass http://127.0.0.1:8080;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_read_timeout 300;
}
}
十四、常见问题排查

图3:LocalAI 常见问题排查树
| 问题 | 可能原因 | 解决办法 |
| 访问 localhost:8080 失败 | 容器未启动、端口占用、Docker 未运行 | docker ps / docker logs local-ai,必要时换端口 |
| 模型列表为空 | 还没有安装模型 | 进入 WebUI Models 页面安装,或使用 CLI 安装 |
| API 返回 model not found | 请求中的模型名与实际名称不一致 | 先 curl /v1/models,复制真实模型 ID |
| 速度太慢 | CPU 推理、小模型未量化、上下文过大 | 换 Q4 量化模型,降低上下文,使用 GPU 镜像 |
| 显卡不工作 | 镜像不匹配、未传递 GPU、驱动缺失 | NVIDIA 检查 nvidia-smi 和 –gpus all |
| 内存爆掉 | 模型过大、并发太高、上下文太长 | 换小模型,减少并发,降低 context_size |
| OpenAI SDK 调不通 | base_url 少了 /v1,端口不对,网络容器隔离 | base_url 写 http://localhost:8080/v1,并检查容器网络 |
十五、FAQ
Q1:LocalAI 和 Ollama 有什么区别?
Ollama 更像本地模型运行器,模型拉取和命令行体验更简单;LocalAI 更像 API 服务中枢,适合把本地模型封装成 OpenAI 兼容服务,接入网站、RAG、工具链和企业内部系统。
Q2:没有显卡能用 LocalAI 吗?
可以。LocalAI 支持 CPU 运行,但速度会受模型大小和量化方式影响。新手建议从 1B、3B、7B 的量化模型开始。
Q3:LocalAI 可以商用吗?
LocalAI 项目本身是开源项目,但具体能否商用还取决于你加载的模型许可证。商业项目必须逐一检查模型 license。
Q4:为什么我用 OpenAI SDK 调用失败?
通常是 base_url、模型名、端口或鉴权配置错误。先用 curl http://localhost:8080/v1/models 验证服务,再把 SDK 的 base_url 改为 http://localhost:8080/v1。
Q5:LocalAI 能不能做知识库问答?
可以。推荐搭配 Embedding 模型和向量数据库,构建 RAG 流程:文档切分、向量化、检索、把检索内容送入聊天模型回答。
Q6:公网部署安全吗?
不要直接裸露 8080 端口。建议启用 API Key、HTTPS、反向代理、IP 白名单、日志监控和限流。
Q7:LocalAI 能生成图片吗?
可以。LocalAI 官方功能中包含图像生成能力,可通过 /v1/images/generations 等接口调用,但图片模型通常更吃显存和磁盘。
Q8:Windows 能部署吗?
可以通过 Docker Desktop + WSL2 路线部署。若要 GPU 加速,需要额外确认 NVIDIA 驱动、CUDA、Docker GPU 支持是否正常。
官方参考来源
- LocalAI Overview:https://localai.io/docs/overview/index.html
- LocalAI Quickstart:https://localai.io/basics/getting_started/
- LocalAI Containers:https://localai.io/installation/containers/index.html
- LocalAI Container Images:https://localai.io/basics/container/
- LocalAI GPU Acceleration:https://localai.io/features/gpu-acceleration/
- LocalAI Model Gallery:https://localai.io/models/
- LocalAI Text Generation API:https://localai.io/features/text-generation/
- LocalAI API Discovery:https://localai.io/features/api-discovery/
- LocalAI Embeddings:https://localai.io/features/embeddings/
- LocalAI Image Generation:https://localai.io/features/image-generation/
- LocalAI GitHub:https://github.com/mudler/LocalAI
环境配置与 Docker 工作流
适合阅读安装部署、本地配置、服务器搭建和自动化流程类文章后继续转化。
