

本地大模型运行环境配置:Ollama、LM Studio、vLLM 怎么选
网站发布教程文章|封面图|流程图|FAQ|SEO 文档
文章摘要
想在电脑或服务器上运行本地大模型,最容易纠结的不是“能不能装”,而是“到底选 Ollama、LM Studio 还是 vLLM”。这篇教程从新手视角出发,把三类运行环境的定位、硬件要求、安装复杂度、API 能力、适用场景和常见坑一次讲清楚:个人电脑试模型优先 LM Studio,开发者本地 API 优先 Ollama,服务器高并发推理优先 vLLM。
发布信息速览
| 项目 | 内容 |
| 推荐栏目 | 保姆级教程 / 环境配置教程 / 安装部署教程 |
| 目标读者 | AI 工具爱好者、开发者、自媒体站长、独立开发者、想本地部署模型的新手 |
| 核心关键词 | 本地大模型运行环境、Ollama 怎么选、LM Studio 教程、vLLM 部署、本地 AI API |
| 内容定位 | 选型指南 + 安装路线 + API 接入 + 常见问题排查 |
| 标题层级 | 正文一级标题使用 H2,正文二级标题使用 H3 |
目录
- 为什么本地大模型运行环境要先选型
- 三者一句话结论
- Ollama:最适合开发者的本地模型运行器
- LM Studio:最适合新手的图形化本地模型工具
- vLLM:最适合服务器高性能推理服务
- 三者怎么选:按设备、场景和预算判断
- 从零配置推荐路线
- API 接入示例
- 常见问题排查
- FAQ
- SEO 文档
- 官方参考来源
为什么本地大模型运行环境要先选型
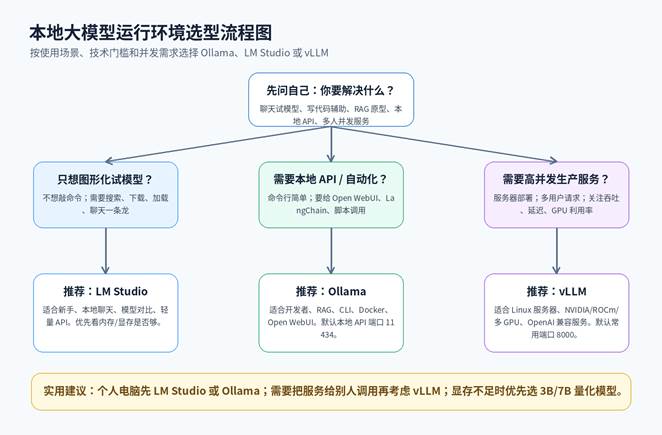
很多新手一上来就问“哪个最好”,但本地大模型工具没有绝对最好,只有是否适合你的电脑、使用场景和技术能力。Ollama、LM Studio、vLLM 看起来都能跑模型,但它们的定位完全不同。
- 如果你只是想像 ChatGPT 一样聊天、试提示词、比较模型,优先考虑 LM Studio。
- 如果你想给本地脚本、RAG、Open WebUI、Dify 或 LangChain 提供一个轻量 API,优先考虑 Ollama。
- 如果你要在服务器上提供多人访问、API 服务、高吞吐推理,优先考虑 vLLM。
一句话总结:LM Studio 偏“桌面应用”,Ollama 偏“本地模型服务”,vLLM 偏“生产级推理引擎”。
三者一句话结论
| 工具 | 一句话定位 | 最推荐人群 | 不太适合谁 |
| Ollama | 本地模型命令行运行器 + 轻量 API 服务 | 开发者、RAG 原型、自动化工作流用户 | 完全不想碰命令行的新手 |
| LM Studio | 图形化下载、加载、聊天和本地 API 工具 | 零基础用户、内容创作者、模型评测者 | 需要生产级高并发服务的团队 |
| vLLM | 高性能大模型推理与 OpenAI 兼容 API 服务 | 服务器部署、企业应用、API 平台、多人并发 | 只想在个人电脑上随便试模型的新手 |

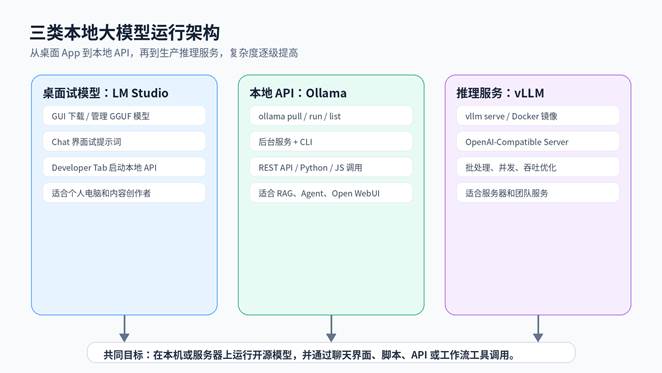
Ollama:最适合开发者的本地模型运行器
Ollama 适合什么场景
Ollama 的优势是简单、轻量、命令统一。你只要记住 pull、run、list、serve 这些命令,就能快速下载模型、运行模型,并通过本地 API 调用。它特别适合想把本地大模型接入工作流、脚本、网页聊天界面或知识库问答的新手开发者。
- 适合本地运行 DeepSeek、Qwen、Llama、Gemma、Mistral 等模型。
- 适合接 Open WebUI、AnythingLLM、Dify、LangChain、LlamaIndex。
- 适合把本地模型变成一个简单的 HTTP 服务。
- 适合 Windows、macOS、Linux 多平台轻量使用。
Ollama 基础安装与运行命令
# Linux 一键安装
curl -fsSL https://ollama.com/install.sh | sh
# 下载模型
ollama pull qwen3:8b
# 运行模型
ollama run qwen3:8b
# 查看已安装模型
ollama list
Ollama API 怎么用
Ollama 安装后默认会在本机提供 API 服务,常见地址是 http://localhost:11434。开发者可以用 curl、Python、JavaScript 或 OpenAI 兼容客户端进行调用。
curl http://localhost:11434/api/generate -d ‘{
“model”: “qwen3:8b”,
“prompt”: “请用三句话解释什么是本地大模型”,
“stream”: false
}’
Ollama 的优缺点
| 优点 | 不足 |
| 安装简单,命令少,模型管理统一 | 图形化能力弱,模型选择主要靠命令或第三方 WebUI |
| 默认提供本地 API,适合做自动化和 RAG | 并发和生产级性能不如 vLLM |
| Windows / macOS / Linux 都相对友好 | 大型模型仍然受内存、显存和磁盘限制 |
LM Studio:最适合新手的图形化本地模型工具
LM Studio 适合什么场景
LM Studio 最大优点是“不用先学命令”。它提供模型搜索、下载、加载、聊天、参数调整和本地 API 服务,适合刚开始接触本地大模型的人。对于内容创作者、运营人员、产品经理、非专业开发者来说,LM Studio 是最容易理解的一条路线。
- 适合图形化下载和管理 GGUF 模型。
- 适合测试不同模型的回答质量、速度和上下文表现。
- 适合开启 Developer Server,把桌面模型变成 OpenAI 兼容接口。
- 适合在 Apple Silicon Mac 或 Windows 电脑上做本地实验。
LM Studio 的基础使用流程
- 第一步:安装 LM Studio 桌面端。
- 第二步:在搜索页选择模型,优先选 3B、7B、8B、14B 的量化版本。
- 第三步:下载后加载模型,进入 Chat 界面测试提示词。
- 第四步:需要 API 时打开 Developer 页面,点击 Start Server。
LM Studio API 接入示例
LM Studio 支持 OpenAI-compatible endpoints,很多代码只需要把 base_url 指向本地服务即可。常见示例端口是 1234,实际以 LM Studio Developer 页面显示为准。
from openai import OpenAI
client = OpenAI(
base_url=’http://localhost:1234/v1′,
api_key=’lm-studio’
)
response = client.chat.completions.create(
model=’local-model’,
messages=[{‘role’: ‘user’, ‘content’: ‘用表格对比 Ollama 和 LM Studio’}]
)
print(response.choices[0].message.content)
LM Studio 的优缺点
| 优点 | 不足 |
| 图形化体验好,新手容易上手 | 服务器化和高并发能力有限 |
| 模型下载、聊天、参数调整集中在一个界面 | 更适合个人电脑,不适合复杂运维 |
| 可启动 OpenAI 兼容 API,方便原型验证 | Intel Mac 等部分设备支持有限,需要看官方系统要求 |
vLLM:最适合服务器高性能推理服务
vLLM 适合什么场景
vLLM 的定位不是“新手桌面聊天工具”,而是“高性能推理服务框架”。如果你准备把开源模型部署成团队或业务系统可调用的 API,并且需要更好的吞吐、并发、GPU 利用率和 OpenAI 兼容接口,就应该考虑 vLLM。
- 适合 Linux GPU 服务器部署。
- 适合 OpenAI-compatible API 服务。
- 适合多用户访问、队列请求、批处理、吞吐优化。
- 适合中大型模型、生产推理、企业内网服务。
vLLM Docker 快速启动示例
docker run –runtime nvidia –gpus all \
-v ~/.cache/huggingface:/root/.cache/huggingface \
–env “HF_TOKEN=$HF_TOKEN” \
-p 8000:8000 \
–ipc=host \
vllm/vllm-openai:latest \
–model Qwen/Qwen3-0.6B
vLLM OpenAI 兼容调用示例
from openai import OpenAI
client = OpenAI(
base_url=’http://localhost:8000/v1′,
api_key=’token-abc123′
)
completion = client.chat.completions.create(
model=’Qwen/Qwen3-0.6B’,
messages=[{‘role’: ‘user’, ‘content’: ‘请解释 vLLM 适合什么场景’}]
)
print(completion.choices[0].message.content)
vLLM 的优缺点
| 优点 | 不足 |
| 高吞吐、适合并发,API 服务能力强 | 安装和调参门槛高,不适合纯小白 |
| OpenAI 兼容服务,方便替换云端 API | 对 GPU、驱动、Docker、Linux 经验要求更高 |
| 适合生产部署、监控、反向代理、团队共享 | 个人电脑试模型通常没必要用 vLLM |
三者怎么选:按设备、场景和预算判断
按设备选择
| 你的设备 | 优先选择 | 理由 |
| 普通 Windows 笔记本,16GB 内存以内 | LM Studio / Ollama 小模型 | 优先 3B/7B 量化模型,避免大型模型卡死 |
| Apple Silicon Mac,16GB+ 统一内存 | LM Studio / Ollama | Mac 本地试模型体验较好,适合图形化和 API 原型 |
| Windows 台式机 + NVIDIA 显卡 | Ollama / LM Studio | 适合本地模型、代码助手、Open WebUI |
| Linux GPU 服务器 | vLLM / Ollama | 单人测试可 Ollama,团队 API 优先 vLLM |
| 多卡服务器或企业内网服务 | vLLM | 更适合高并发、批处理和服务化部署 |
按使用场景选择
| 使用场景 | 推荐方案 | 说明 |
| 本地聊天、写作、测试模型 | LM Studio | 最少命令,最适合新手 |
| 本地知识库问答 / RAG 原型 | Ollama + Open WebUI / Dify | API 简单,生态适配多 |
| AI 编程助手接本地模型 | Ollama / LM Studio API | 看插件是否支持 OpenAI-compatible 或 Ollama |
| 把本地模型给多人调用 | vLLM | 需要并发控制、鉴权、日志、监控 |
| 企业内网私有化 API | vLLM + Nginx + 鉴权 | 更接近生产环境 |
按学习成本选择
- 完全新手:先 LM Studio,理解模型文件、量化、上下文和显存。
- 半技术用户:用 Ollama,学会命令行、API、模型目录和环境变量。
- 开发/运维用户:学习 vLLM、Docker、GPU 驱动、反向代理、日志监控。
从零配置推荐路线
路线一:新手桌面体验路线
- 安装 LM Studio。
- 下载 3B/7B/8B 的 GGUF 量化模型。
- 在 Chat 界面测试中文、代码、总结、写作能力。
- 打开 Developer Server,尝试用 Python 调用本地模型。
路线二:开发者本地 API 路线
- 安装 Ollama。
- 用 ollama pull 下载模型。
- 用 curl 测试 /api/generate 或 /api/chat。
- 接入 Open WebUI、LangChain、Dify、n8n 或自己的脚本。
路线三:服务器生产服务路线
- 准备 Linux + NVIDIA/ROCm/支持硬件环境。
- 安装 Docker、NVIDIA Container Toolkit 或对应 GPU 运行时。
- 用 vllm/vllm-openai 镜像启动 OpenAI 兼容服务。
- 配置 Nginx、HTTPS、API Key、访问控制、日志、监控。
API 接入示例
统一用 OpenAI SDK 调本地服务
如果工具支持 OpenAI 兼容接口,那么最推荐的做法是保留 OpenAI SDK 代码结构,只替换 base_url、api_key 和 model 名称。
from openai import OpenAI
client = OpenAI(
base_url=’http://localhost:8000/v1′, # LM Studio 可换成 http://localhost:1234/v1
api_key=’local-key’
)
res = client.chat.completions.create(
model=’your-local-model’,
messages=[{‘role’:’user’,’content’:’写一段本地大模型环境配置建议’}]
)
print(res.choices[0].message.content)
Ollama 原生 API 调用
Ollama 也可以直接使用自己的 REST API。如果只是本地脚本调用,原生 API 更直观。
import requests
r = requests.post(‘http://localhost:11434/api/chat’, json={
‘model’: ‘qwen3:8b’,
‘messages’: [{‘role’: ‘user’, ‘content’: ‘给我一个本地模型选型建议’}],
‘stream’: False
})
print(r.json()[‘message’][‘content’])
常见问题排查

模型下载太慢怎么办
- 优先选择体积较小的量化模型,例如 3B/7B/8B 的 Q4 或 Q5。
- 检查是否需要 Hugging Face Token,尤其是 gated model。
- 服务器部署时建议把模型缓存目录挂载到数据盘,避免系统盘爆满。
显存不足怎么办
- 降低模型参数规模,例如从 14B 换到 7B 或 3B。
- 降低量化精度,例如 Q8 换 Q5 或 Q4。
- 降低上下文长度,关闭无关程序。
- 生产服务场景可考虑多 GPU、tensor parallel、KV cache 优化等方案。
本地 API 调不通怎么办
- 确认服务已启动:Ollama 看 ollama list/ps,LM Studio 看 Developer Server,vLLM 看容器日志。
- 确认端口:Ollama 常见 11434,LM Studio 常见 1234,vLLM 常见 8000。
- 容器内访问宿主机服务时,不要直接写 localhost,需要使用 host.docker.internal 或 Docker 网络服务名。
- 开放局域网访问前务必加鉴权、反向代理和防火墙限制。
FAQ
本地大模型运行环境第一款应该装哪个?
完全新手建议先装 LM Studio;想接 API 或自动化工作流建议先装 Ollama;准备做服务器服务再学习 vLLM。
Ollama 和 LM Studio 可以同时安装吗?
可以。很多人用 LM Studio 做图形化模型测试,用 Ollama 给 Open WebUI、RAG、脚本提供轻量 API。注意端口不要冲突。
vLLM 能不能装在普通 Windows 电脑上?
普通新手不建议这样做。vLLM 更适合 Linux 服务器或 WSL2/容器环境,尤其是需要 GPU 推理和高并发服务时。
没有独立显卡能不能跑本地大模型?
可以跑小模型或量化模型,但速度会慢。建议先尝试 1.5B、3B、7B 的量化版本,并控制上下文长度。
本地模型一定比云端模型安全吗?
本地运行可以减少数据发往第三方服务的风险,但仍要注意模型来源、API 暴露、日志保存、内网访问权限和敏感数据脱敏。
Ollama、LM Studio、vLLM 都支持 OpenAI 兼容接口吗?
LM Studio 和 vLLM 明确提供 OpenAI-compatible endpoints;Ollama 有原生 REST API,也有很多框架支持 Ollama 或 OpenAI 兼容适配。
做知识库问答推荐哪个?
新手推荐 Ollama + Open WebUI 或 Dify;需要多人并发和稳定服务时,可以把推理后端换成 vLLM。
官方参考来源
| 来源 | 链接 |
| Ollama Windows 官方文档 | https://docs.ollama.com/windows |
| Ollama API 官方文档 | https://docs.ollama.com/api/introduction |
| LM Studio 系统要求 | https://lmstudio.ai/docs/app/system-requirements |
| LM Studio 本地 API Server 文档 | https://lmstudio.ai/docs/developer/core/server |
| LM Studio OpenAI Compatibility 文档 | https://lmstudio.ai/docs/developer/openai-compat |
| vLLM 安装文档 | https://docs.vllm.ai/en/latest/getting_started/installation/ |
| vLLM Docker 部署文档 | https://docs.vllm.ai/en/stable/deployment/docker/ |
| vLLM OpenAI-Compatible Server 文档 | https://docs.vllm.ai/en/stable/serving/openai_compatible_server/ |
环境配置与 Docker 工作流
适合阅读安装部署、本地配置、服务器搭建和自动化流程类文章后继续转化。
