

不用命令行也能跑本地大模型:LM Studio安装与本地模型使用全流程
适合 Windows、macOS、Linux 用户 | 覆盖模型下载、加载、文档对话、本地 API 与排错
网站发布教程 + SEO 文档 | 更新日期:2026年5月2日
一、文章摘要
LM Studio 是面向普通用户和开发者的本地大模型桌面工具。它最大的优势是:不用手写复杂命令,也可以在个人电脑上下载、管理、运行 Qwen、Llama、DeepSeek、Gemma、Mistral 等开源/开放权重模型;同时还可以把本地模型作为 API 服务,接入 Python、Node.js、VS Code、IDEA、自动化脚本或企业内部工具。本文从下载安装到模型选择、加载参数、文档对话、OpenAI 兼容接口、性能优化和常见报错排查,完整梳理 LM Studio 的本地模型使用流程。
| 提示:本文适合谁 适合想在电脑上离线体验大模型、担心隐私数据上传云端、想给 AI 编程工具接入本地模型,或者希望用图形界面快速测试不同开源模型的新手。 |
文章目录
- LM Studio 是什么
- 安装前准备:硬件、系统与磁盘
- Windows / macOS / Linux 安装步骤
- 下载第一个本地模型
- 加载模型并开始聊天
- 本地文档问答和 RAG
- 开启本地 API 服务
- lms 命令行使用
- 模型选择与性能优化
- 常见报错排查
- FAQ、相关阅读与 SEO 文档
二、LM Studio 是什么?为什么适合新手部署本地大模型?
LM Studio 可以理解成“本地大模型的图形化控制台”:它把模型搜索、下载、加载、聊天、文档问答和 API 服务做进一个桌面应用里。相比纯命令行工具,LM Studio 对新手更友好;相比只用在线 AI,LM Studio 的优势是数据主要留在本机,适合做离线测试、私有文档问答、代码辅助和企业内网原型验证。
官方文档明确说明,LM Studio 支持在 macOS、Windows、Linux 上运行本地 LLM;支持通过 llama.cpp 运行 GGUF 模型,并在 Apple Silicon Mac 上支持 Apple MLX。它还提供本地 REST API、OpenAI 兼容接口、Anthropic 兼容接口、Python/TypeScript SDK、MCP、CLI 等开发者能力。
简单说,如果 Ollama 更像“命令行优先的本地模型引擎”,那么 LM Studio 更像“带模型商店、聊天窗口和 API 开关的本地 AI 工作台”。

图 1:LM Studio 本地模型使用流程。
三、安装前准备:先确认电脑能不能跑
本地大模型的体验主要取决于三件事:内存、显存/统一内存、磁盘空间。LM Studio 本体不难安装,真正影响体验的是模型文件大小和加载参数。
| 平台 | 官方支持口径 | 推荐配置 | 新手建议 |
| macOS | Apple Silicon(M1/M2/M3/M4);macOS 14.0+;当前不支持 Intel Mac | 16GB+ 统一内存;8GB 也可跑小模型 | M 系列 Mac 优先选 MLX 或 GGUF,小内存先跑 3B/7B Q4 |
| Windows | 支持 x64 与 ARM;x64 需要 AVX2;建议 16GB RAM;推荐 4GB+ 独立显存 | 16GB RAM 起步,NVIDIA/AMD/Intel GPU 均可尝试 | 没有独显也能跑,但速度会慢;优先选择小模型和 Q4 |
| Linux | x64 与 ARM64;以 AppImage 分发;Ubuntu 20.04+ | 16GB+ RAM,建议独显或高性能 CPU | 服务器可考虑 headless/CLI 路线 |
磁盘方面,7B/8B 量化模型通常需要数 GB 到十几 GB 空间;14B、32B 甚至 70B 模型会明显更大。建议至少预留 30GB-100GB 可用空间,用于模型文件、缓存和后续测试。
| 提示:不要一开始就追大模型 本地部署最常见的失败原因不是安装错,而是第一次就下载了过大的模型。建议先用 3B 或 7B/8B Q4 跑通流程,再逐步升级。 |
四、LM Studio 下载与安装全流程
1. Windows 安装步骤
- 进入 LM Studio 官网下载页,选择 Windows 版本。
- 双击安装包,根据安装向导完成安装。
- 首次启动后,允许应用创建必要目录。
- 进入 Settings / My Models 检查模型保存位置;如果 C 盘空间较小,建议改到容量更大的磁盘。
- 打开 Discover 页面,准备下载第一个模型。
2. macOS 安装步骤
- 确认 Mac 是 Apple Silicon(M1/M2/M3/M4),且 macOS 版本为 14.0 或更新。
- 从官网下载 macOS 安装包。
- 将 LM Studio 拖入 Applications 文件夹。
- 首次打开如遇系统安全提醒,进入“系统设置 – 隐私与安全性”允许打开。
- 进入 Runtime 管理页面检查运行时,Apple Silicon 用户可重点关注 MLX 支持。
3. Linux 安装步骤
- 下载官方 AppImage 文件。
- 给 AppImage 添加执行权限。
- 双击运行,或在终端中启动。
- 如果是服务器环境,优先考虑 lms / llmster / API Server 的无界面运行方式。
chmod +x LM-Studio*.AppImage
./LM-Studio*.AppImage
五、下载第一个本地模型:从 Discover 到 Hugging Face
LM Studio 内置模型下载器,可以直接搜索并下载 Hugging Face 上受支持的模型。官方文档说明,既可以按关键词搜索,也可以粘贴完整 Hugging Face 模型地址。
- 打开 LM Studio,进入 Discover 页面。
- 搜索模型关键词,例如 qwen、llama、deepseek、gemma、mistral。
- 选择适合硬件的量化版本。新手优先选择 Q4 或官方推荐项。
- 点击 Download 等待下载完成。
- 下载结束后进入 Chat 页,打开模型加载器,选择刚下载的模型。
常见模型方向:
| 需求 | 可搜索关键词 | 推荐规模 | 说明 |
| 中文写作/办公 | Qwen、DeepSeek | 7B/8B/14B | 中文理解、摘要、写作体验通常更友好 |
| 代码辅助 | Qwen Coder、DeepSeek Coder、CodeLlama | 7B/14B/32B | 适合解释代码、补全思路、生成脚本 |
| 英文通用问答 | Llama、Mistral、Gemma | 7B/8B/12B | 英文资料处理和通用问答表现稳定 |
| 轻量设备 | Phi、Qwen 3B、Llama 3B | 1B-4B | 速度快,适合入门与低配置电脑 |
| 推理任务 | DeepSeek R1、Qwen Reasoning 类模型 | 7B/14B/32B+ | 更吃硬件,适合逐步升级测试 |
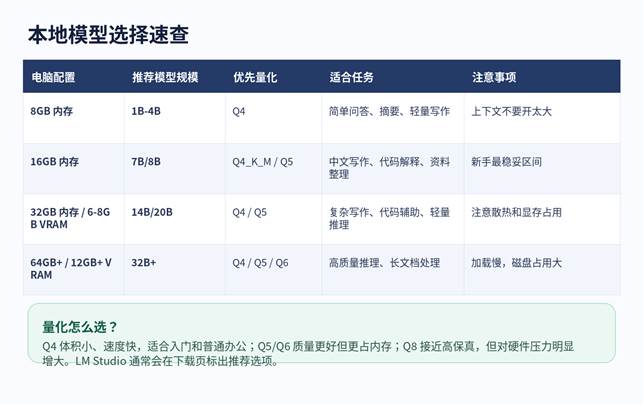
图 2:本地模型选择速查。
六、加载模型并开始聊天
下载模型只是把模型文件保存到本机,真正使用前还需要“加载到内存”。加载模型时,LM Studio 会根据硬件给出默认参数,但你仍然可以调整上下文长度、GPU Offload、运行时等设置。
- 进入 Chat 页面。
- 点击模型选择器,选择已下载模型。
- 保持默认加载参数先试跑一次。
- 输入一句测试提示词,例如“请用三句话介绍 LM Studio 的作用”。
- 观察加载耗时、生成速度、内存占用和输出质量。
测试提示词:
你是一个本地大模型助手。请用三句话说明 LM Studio 能做什么,并给出一个新手使用建议。
关键参数怎么理解?
| 参数 | 作用 | 建议 |
| Context Length | 模型一次能“记住”的上下文长度 | 越大越占内存;新手先用默认值 |
| GPU Offload | 把计算尽量交给 GPU | 有显卡/Apple Silicon 可开 auto/max;出错就降低 |
| Temperature | 控制输出随机性 | 写作 0.7 左右,严谨问答 0.2-0.5 |
| Top P / Top K | 控制候选词范围 | 新手不必改,遇到发散再调 |
| System Prompt | 给模型设定角色和行为规则 | 适合做固定写作助手、代码助手或客服助手 |
七、本地文档问答:用 LM Studio 做离线 RAG
LM Studio 支持在聊天中附加 .docx、.pdf、.txt 等文档。官方文档说明,如果文档内容较短,会尽量直接放入上下文;如果文档较长,则会采用检索增强生成(RAG)方式,从文档中找出相关片段提供给模型参考。
- 进入 Chat 页面并加载模型。
- 点击附件/文档入口,上传 PDF、Word 或 TXT 文件。
- 提问时尽量带上文档关键词,例如“请根据合同中的付款条款总结风险”。
- 如果回答不准确,把问题问得更具体,例如指定章节、时间、主体或术语。
- 重要场景要回看原文,不要只依赖模型总结。
| 提示:文档问答的可靠性 RAG 不是“全文保证阅读器”。越具体的问题越容易命中正确片段;越模糊的问题越容易漏掉关键信息。正式材料应保留人工复核。 |
八、开启本地 API:让 Python、JS、插件调用 LM Studio
LM Studio 的 Developer 页面可以启动本地 API Server。官方文档说明,本地模型可通过 REST API、lmstudio-js、lmstudio-python、OpenAI 兼容接口和 Anthropic 兼容接口调用。OpenAI 兼容接口默认示例端口为 1234,常见 base URL 为 http://localhost:1234/v1。
- 打开 LM Studio 的 Developer 页面。
- 加载一个模型。
- 打开 Start Server 开关,确认端口为 1234 或你自定义的端口。
- 在终端、Python、Node.js 或 AI 插件中把 API 地址改为 http://localhost:1234/v1。
- 使用 LM Studio 中显示的模型 ID 发起请求。
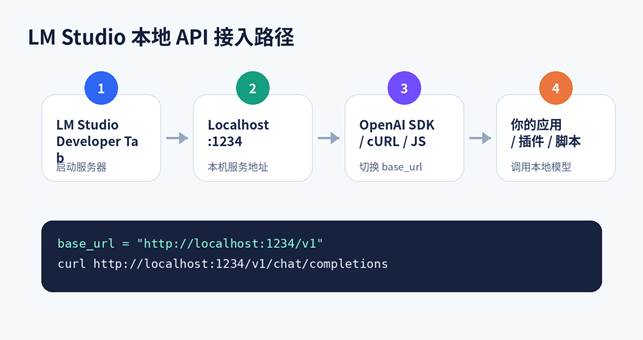
图 3:LM Studio 本地 API 接入路径。
Python 调用示例
from openai import OpenAI
client = OpenAI(
base_url=”http://localhost:1234/v1″,
api_key=”lm-studio” # 本地服务通常可填写任意占位值
)
response = client.chat.completions.create(
model=”这里填 LM Studio 中显示的模型 ID”,
messages=[{“role”: “user”, “content”: “用三点总结本地部署大模型的好处”}],
temperature=0.7,
)
print(response.choices[0].message.content)
cURL 测试示例
curl http://localhost:1234/v1/chat/completions \
-H “Content-Type: application/json” \
-d ‘{
“model”: “这里填模型 ID”,
“messages”: [{“role”: “user”, “content”: “Say this is a test!”}],
“temperature”: 0.7
}’
九、lms 命令行:适合进阶用户和自动化脚本
LM Studio 自带 lms 命令行工具,不需要额外安装;但官方文档提示,需要至少运行过一次 LM Studio 后才能使用 lms。它可以用于模型下载、模型列表、加载模型、启动/停止服务器等场景。
| 命令 | 作用 | 使用场景 |
| lms –help | 查看命令帮助 | 确认 CLI 可用 |
| lms get qwen | 搜索/下载模型 | 终端工作流 |
| lms ls | 列出本地模型 | 检查模型是否下载成功 |
| lms load –gpu=auto | 加载模型 | 脚本化启动模型 |
| lms ps | 查看已加载模型 | 排查内存占用 |
| lms server start | 启动本地服务器 | API 场景 |
| lms server stop | 停止本地服务器 | 释放资源 |
十、把 LM Studio 接入 VS Code、IDEA 或自己的工具
只要某个工具支持 OpenAI-Compatible Provider、自定义 Base URL 或本地 OpenAI 接口,通常就可以尝试接入 LM Studio。核心配置不是“API Key”,而是 Base URL、模型 ID 和接口格式。
- 在 LM Studio 中启动本地 API Server。
- 复制 base_url:通常是 http://localhost:1234/v1。
- 复制当前加载模型的模型 ID。
- 在插件里选择 OpenAI Compatible / Custom Provider / Local Provider。
- 填入 Base URL、模型 ID 和占位 API Key。
- 先用短提示词测试,再用于代码解释、文档总结或自动化脚本。
| 提示:插件兼容不是百分百 不同插件对工具调用、结构化输出、流式响应和上下文管理的支持不同。能对话不代表所有高级功能都兼容,正式接入前要做功能测试。 |
十一、性能优化:让本地模型跑得更稳
| 问题 | 优先调整项 | 说明 |
| 加载很慢 | 换小模型或低量化 | 模型越大,加载越慢,磁盘和内存压力越高 |
| 生成很慢 | 提高 GPU Offload 或换更小模型 | 无独显设备不要追求大模型 |
| 内存爆掉 | 降低 Context Length | 上下文越长越吃内存 |
| 回答质量差 | 换更适合任务的模型 | 中文、代码、推理分别选择专门模型 |
| 电脑发热 | 减少并发、关闭其他大程序 | 长时间推理会持续占用 CPU/GPU |
| API 不稳定 | 固定模型 ID 和端口 | 避免插件找不到模型或端口冲突 |
十二、常见报错与解决办法
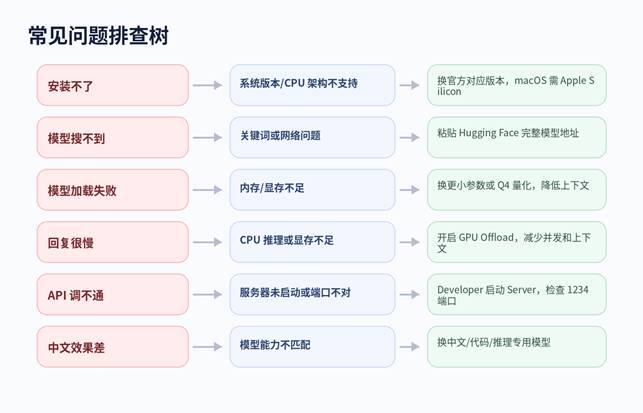
图 4:常见问题排查树。
| 现象 | 可能原因 | 解决办法 | 优先级 |
| Mac 安装后打不开 | Intel Mac 或 macOS 版本过低 | 确认 Apple Silicon + macOS 14.0+ | 高 |
| Windows 无法启动 | CPU 不支持 AVX2 或系统架构不匹配 | 检查 CPU 指令集,下载对应架构版本 | 高 |
| 模型下载失败 | 网络、空间或 Hugging Face 地址问题 | 换网络、改模型目录、粘贴完整模型 URL | 中 |
| 模型加载失败 | 内存/显存不足 | 降低模型规模、换 Q4、降低上下文长度 | 高 |
| API 404/连接失败 | 服务器未启动、端口不对、模型 ID 错误 | Developer 开启 Server,确认 /v1 与模型 ID | 高 |
| 回答胡说 | 模型能力不足或提示词太泛 | 换模型,提供更多上下文,降低随机性 | 中 |
| 文档问答漏信息 | RAG 没检索到相关片段 | 提问中加入章节名、关键词、时间、人名 | 中 |
FAQ:LM Studio 安装与本地模型使用常见问题
1. LM Studio 是免费的吗?
LM Studio 面向个人本地模型体验提供桌面应用,具体授权、企业使用和高级能力应以官网最新条款为准。下载前建议查看官方 Terms 和 Enterprise 页面。
2. LM Studio 和 Ollama 有什么区别?
Ollama 更偏命令行和服务化;LM Studio 更偏图形界面和模型管理。新手想用聊天窗口快速体验,LM Studio 更直观;开发者想用脚本自动化,两者都可以。
3. 没有显卡能用 LM Studio 吗?
可以尝试,但速度通常较慢。建议从 1B-4B 或 7B Q4 模型开始,不要直接运行大模型。
4. 8GB 内存电脑能跑吗?
可以跑小模型,但不适合大上下文和大参数模型。推荐 3B/4B 或更小模型,并关闭其他占内存程序。
5. Mac Intel 能安装 LM Studio 吗?
截至本文核对时间,官方系统要求说明 Intel-based Macs currently not supported。Intel Mac 用户建议改用其他支持 Intel 的方案或网页版 AI 工具。
6. 下载模型时 Q4、Q5、Q8 是什么意思?
这是量化等级。Q4 更省空间和内存,适合新手;Q5/Q6 质量更高但更占资源;Q8 更接近高保真,但硬件压力更大。
7. LM Studio 可以完全离线使用吗?
可以离线运行已下载模型,但首次下载模型、更新运行时和获取新模型时通常需要联网。
8. 可以用 LM Studio 做文档问答吗?
可以。LM Studio 支持添加 .docx、.pdf、.txt 文件做上下文或 RAG,但重要文件仍需人工核对。
9. LM Studio 的本地 API 地址是什么?
常见默认地址是 http://localhost:1234/v1,但端口可以改。以 Developer 页面显示为准。
10. 能不能接入 VS Code、IDEA、Cline、Continue?
只要插件支持 OpenAI Compatible 或自定义 Base URL,就可以尝试接入。需填对 Base URL、模型 ID 和接口格式。
官方参考来源
- LM Studio Docs – App: https://lmstudio.ai/docs/app
- LM Studio System Requirements: https://lmstudio.ai/docs/app/system-requirements
- LM Studio Get Started: https://lmstudio.ai/docs/app/basics
- LM Studio Download an LLM: https://lmstudio.ai/docs/app/basics/download-model
- LM Studio Chat with Documents: https://lmstudio.ai/docs/app/basics/rag
- LM Studio Local API Server: https://lmstudio.ai/docs/developer/core/server
- LM Studio OpenAI Compatibility Endpoints: https://lmstudio.ai/docs/developer/openai-compat
- LM Studio CLI lms: https://lmstudio.ai/docs/cli
- Hugging Face – GGUF usage with LM Studio: https://huggingface.co/docs/hub/lmstudio
环境配置与 Docker 工作流
适合阅读安装部署、本地配置、服务器搭建和自动化流程类文章后继续转化。
