

PandaProbe Cloud 和传统日志平台的区别,不只是“一个给 AI 用,一个给普通后端用”。真正的差异在于:传统日志平台主要回答“系统发生了什么”,Agent 可观测性还要回答“模型为什么这样做、调用了哪些工具、在哪一步偏离目标、输出质量是否下降、下一次会不会复现”。
截至 2026 年 6 月 16 日核对 PandaProbe 官方站、GitHub 和 Product Hunt 页面,PandaProbe Cloud 被定位为面向 AI Agent 和 LLM 工作流的托管可观测平台,提供 trace ingestion、storage、dashboard、eval LLM、调度监控、SSO 和权限管理;PandaProbe Tracing 强调可以追踪 LLM calls、tool calls、agent decisions、custom spans、nested spans 和 session;Evaluation 则覆盖 trace/session eval、uncertainty、loop、regression monitoring 等质量信号。
如果你正在做 AI Agent、RAG、Claude Code、工作流自动化或生产级 AI 应用,可以继续阅读站内 AI Agent 教程、RAG 工作流、Claude Code 实战 和 AI 工作流教程。
摘要:Agent 可观测性比日志多了“过程、意图和质量”
传统日志平台擅长收集服务日志、错误堆栈、请求 ID、延迟、状态码和基础指标。它适合排查普通 Web 服务:哪个接口慢、哪个服务报错、哪条 SQL 超时、哪个 pod 重启。但 AI Agent 的问题往往不止是系统异常,而是“正常运行但结果不对”。
Agent 可能没有抛异常,却在错误的上下文里调用了搜索工具;可能 API 返回 200,却把用户意图理解错;可能每一步都看似合理,但整体陷入循环;可能回答格式正确,却引用了错误资料;也可能今天表现正常,明天因为模型、提示词或知识库变化出现质量漂移。
PandaProbe Cloud 这类 Agent 可观测平台的价值,就在于把一次 Agent 运行拆成可追踪的 trace、span、LLM call、tool call、decision、session 和 eval result。它让开发者不只看到结果,还能看到路径、判断、工具、证据和质量评分。
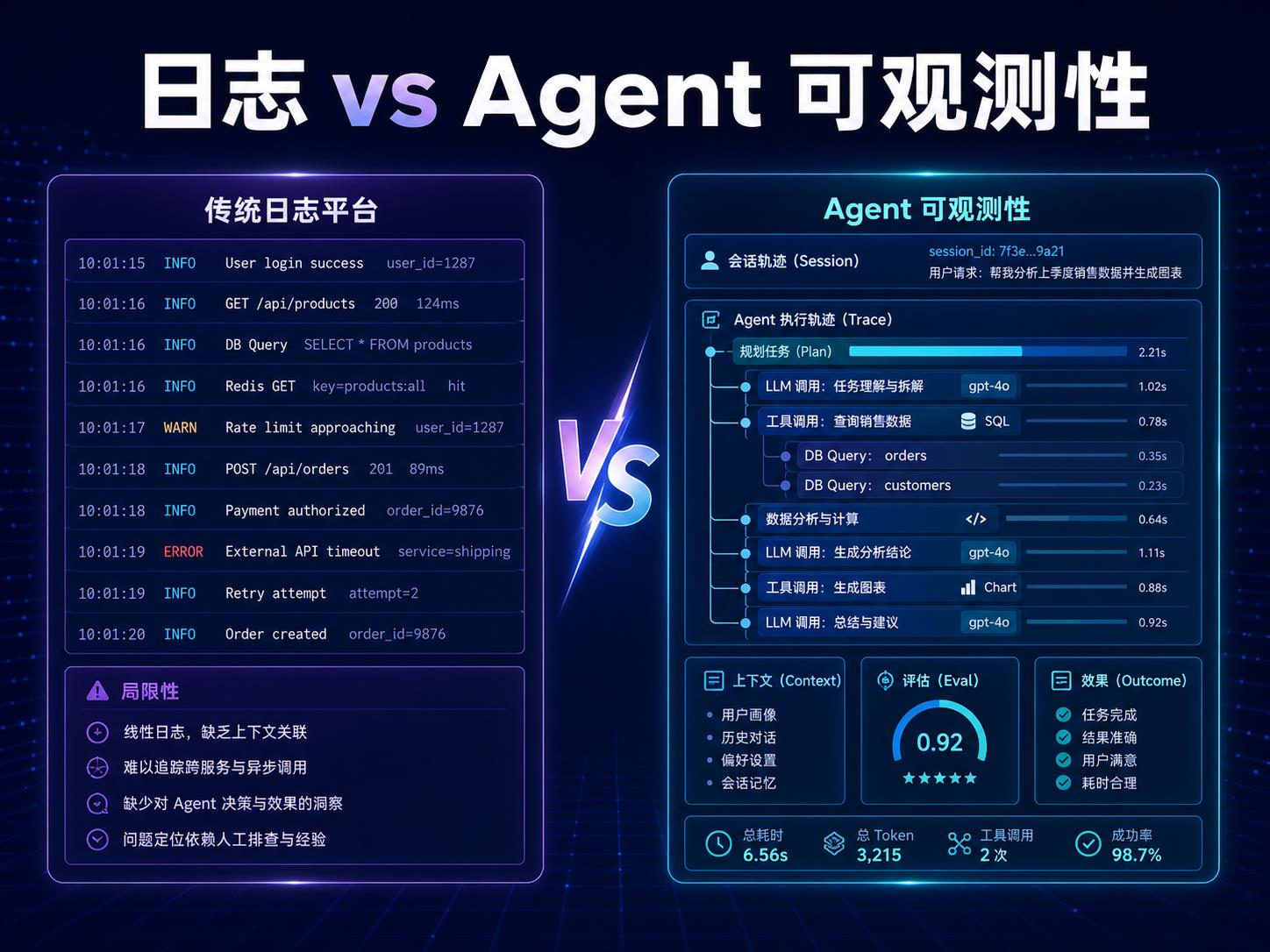
传统日志平台能解决什么
它擅长系统层故障定位
传统日志平台的核心能力是集中收集和检索日志。开发者可以根据时间、服务、请求 ID、错误码、用户 ID 或关键词定位问题。对于后端服务、队列任务、数据库访问和基础设施故障,这仍然是必要能力。
例如接口 500、鉴权失败、第三方 API 超时、数据库连接池耗尽、CPU 飙升、任务重试过多,这些问题通常可以通过日志、指标和链路追踪定位。传统平台在稳定性工程里仍然不可替代。
它的视角偏事件和文本
日志本质上是事件文本。它可以记录“调用了模型”“返回了结果”“工具调用失败”,但默认不会理解这些事件之间的 Agent 语义关系。一次 Agent 任务可能包含规划、检索、工具调用、代码执行、反思、重试和最终回答。只看日志,开发者要在大量文本里手工拼出执行路径。
当 Agent 变复杂,日志会迅速变得难读:同一个用户会话里有多轮模型调用,多个工具交错执行,子 Agent 并行工作,异步任务跨服务流转。传统日志能保存这些信息,但不一定能把它们组织成开发者需要的“Agent 运行故事”。
它通常不直接回答质量问题
传统日志可以告诉你请求是否成功、耗时多久、返回了多少 token,但它通常不能直接告诉你回答是否正确、工具是否选对、是否发生幻觉、是否陷入循环、是否偏离任务目标、是否出现质量回归。
这就是 Agent 可观测性要补上的部分:AI 应用不只需要 uptime,还需要 answer quality、tool correctness、task completion、uncertainty、policy compliance 和 regression signal。
PandaProbe Cloud 多了什么
托管的 Trace Ingestion、Storage 和 Dashboard
PandaProbe Cloud 的公开介绍强调 managed trace ingestion、storage 和 dashboard。这意味着团队不需要先自建一套 trace 存储和可视化系统,就能把 Agent 运行轨迹上报到云端,再在 dashboard 中查看会话、trace、span 和关键质量信号。
对早期团队来说,这一点很实际。Agent 可观测性需要保存大量结构化上下文:用户输入、模型输出、工具参数、工具结果、检索片段、错误、token、成本、延迟和评估结果。如果只靠日志平台,数据结构和展示方式往往要自己拼。
LLM Call、Tool Call 和 Agent Decision 都能成为可观察对象
PandaProbe Tracing 页面把 LLM calls、tool calls、agent decisions、custom spans、nested spans 和 sessions 作为可追踪对象。这个粒度比普通日志更适合 Agent,因为 Agent 的问题经常发生在“模型选择工具”和“工具结果进入下一轮推理”的边界。
例如一个客服 Agent 给错答案,日志可能只显示“最终回答已生成”。Trace 视角则能看到:它先检索了哪篇知识库,模型为什么选择某个工具,工具返回了什么,模型有没有忽略关键证据,最终回答是在哪个 span 里生成的。
Nested Span 能还原复杂工作流
传统链路追踪也有 span,但 Agent 需要更语义化的 nested span:一次 session 下面可能有一个 task trace,trace 里包含 plan、search、retrieve、rank、tool call、sub-agent handoff、final answer、eval 等层级。嵌套结构让开发者能从整体任务一路钻到具体模型调用。
这对多步骤 Agent 特别关键。没有 nested span,调试人员只能看到一串平铺日志;有了层级结构,才能知道哪个子步骤拖慢了任务、哪个工具贡献最大、哪个推理节点导致偏差。
Evaluation 把质量变成可监控指标
PandaProbe Evaluation 页面强调 trace/session eval、uncertainty、loop 和 regression monitoring。也就是说,平台不仅记录 Agent 做了什么,还试图评价它做得好不好。对生产级 AI 应用来说,这比单纯日志更接近业务需求。
例如自动生成客服回复时,开发者可能关心事实正确性、引用充分性、语气合规、是否泄露敏感信息;代码 Agent 可能关心是否通过测试、是否修改无关文件、是否遵守权限边界;RAG Agent 可能关心是否使用了正确来源。Eval 能把这些质量判断结构化,持续监控才有基础。

Agent 可观测性为什么不能只靠日志
因为 Agent 的失败经常是软失败
传统后端失败通常很硬:异常、超时、状态码错误、进程崩溃。Agent 失败经常很软:回答看起来流畅但事实错了,任务完成了一半却声称完成,工具调用成功但选错对象,推理过程绕了一圈回到原点,输出符合格式但业务不可用。
这些问题不会自然出现在 error log 里。你必须主动设计评估、采样、人工反馈和回归监控,才能看到质量下降。
因为一次输出背后有多层上下文
一个 Agent 的最终回答可能依赖系统提示词、用户历史、检索结果、工具返回、模型版本、缓存、权限、计划步骤和中间反思。只保存最终输入输出,很难解释为什么它会这样回答。
Agent 可观测性要求把上下文链条保存下来,同时避免泄露敏感信息。理想状态是既能复盘任务路径,又能做脱敏、权限控制和数据保留策略。
因为模型行为会随时间变化
传统服务只要代码不变,行为通常比较稳定;AI 应用还受到模型版本、提示词、知识库、工具接口、检索索引和用户分布影响。即使代码没变,质量也可能变化。
这就需要 regression monitoring:用固定评测集和线上采样持续比较表现,发现某类任务变差、某个工具调用异常增加、某个模型版本导致成本上升或延迟变长。
PandaProbe Cloud vs 传统日志平台:核心差异表
数据模型不同
传统日志平台以 log event 为核心,通常是时间戳、服务名、级别、消息和若干字段。Agent 可观测性以 session、trace、span、model call、tool call、eval result 为核心,强调层级关系和任务语义。
调试路径不同
传统调试往往从错误日志开始:找到异常,再追请求。Agent 调试往往从失败案例开始:找到一条差评、错误回答或异常成本,再展开完整 trace,看模型在哪一步做错了判断。
监控指标不同
传统平台关注错误率、延迟、吞吐、资源和状态码。Agent 可观测性还要关注任务完成率、工具选择正确率、引用命中率、幻觉率、循环率、人工接管率、评估分数、token 成本和模型版本差异。
使用对象不同
日志平台主要服务后端、SRE 和平台工程团队。Agent 可观测性还会服务 AI 产品经理、提示词工程师、数据标注人员、模型评测人员、客服运营和业务负责人,因为质量问题不一定是纯技术问题。
什么团队最需要 Agent 可观测性
生产环境已经有 AI Agent 的团队
如果 Agent 已经在处理客户问题、代码任务、数据分析、销售线索、运营自动化或内部 IT 支持,单靠日志通常不够。你需要知道它为什么给出某个答复、是否用了正确工具、失败后是否能安全降级。
正在把 RAG 系统接入业务的团队
RAG 不只是检索加回答。开发者需要观察检索命中、文档引用、上下文拼接、模型回答和最终质量。如果回答错了,要判断是没检索到、检索到但没用、文档本身错,还是模型推理错。
做多工具、多步骤工作流的团队
工具越多,日志越难读。一个 Agent 可能调用浏览器、数据库、CRM、代码执行器、搜索、邮件、日历和内部 API。可观测性平台要把这些调用组织成清晰轨迹,而不是让开发者在几十个服务日志里手工拼图。
需要评估和合规审计的团队
金融、医疗、法律、企业 SaaS 和客户支持场景通常需要审计链路。Agent 可观测性可以帮助保存决策过程、证据来源、人工接管和评估结果,但团队仍然要设计脱敏、访问控制和数据保留策略。
落地工作流:从日志到 Agent 可观测性
第一步:保留现有日志,不要替换掉
Agent 可观测性不是让你删除日志平台。系统错误、基础设施状态、网络异常和资源指标仍然需要传统日志与监控。正确做法是把 PandaProbe Cloud 这类平台作为 Agent 层可观测能力,与现有日志系统并行。
第二步:从关键 Agent 路径接入 Tracing
不要一开始全量接入所有流程。先选一个高价值 Agent,例如客服问答、RAG 搜索、代码修复或数据分析,把 session、trace、LLM call、tool call、retriever、final answer 都纳入 trace。
第三步:定义业务质量评估项
不同 Agent 的评估项不同。客服 Agent 可能看事实正确性、语气、引用、是否升级人工;代码 Agent 可能看测试通过率、最小修改、权限边界;RAG Agent 可能看证据覆盖、拒答策略和引用一致性。不要只用一个通用分数概括所有质量。
第四步:把线上样本和固定评测集结合
固定评测集适合做回归监控,线上样本适合发现真实用户分布下的新问题。两者都需要。只看固定集会漏掉新场景,只看线上反馈又缺少可重复对比。
第五步:让告警指向可复盘的 Trace
告警不要只说“Agent 质量下降”。更好的告警应能直接链接到相关 session、trace、eval result 和失败样本。这样开发者可以从告警进入具体轨迹,快速判断是提示词、工具、模型、检索还是业务数据问题。

选型建议:什么时候用 PandaProbe Cloud,什么时候继续用传统平台
只做普通后端服务,传统日志仍然够用
如果你的系统没有 LLM、没有 Agent、没有工具调用、没有 RAG,也不需要评估生成质量,传统日志、指标和链路追踪已经能覆盖大部分可观测需求。
AI 功能进入生产,应该补 Agent 层观测
一旦 AI 功能开始影响真实用户、真实业务动作或真实成本,就应该引入 Agent 层观测。特别是当你开始问“为什么它这样回答”“为什么这次贵了很多”“为什么工具选错了”“为什么同样问题今天变差了”时,日志平台就不够了。
云托管适合快速启动和团队协作
PandaProbe Cloud 提供托管 ingestion、storage、dashboard 以及团队协作相关能力,适合不想先自建平台的团队。对于严格数据隔离或内网部署需求强的组织,则需要进一步评估自托管、脱敏和权限策略。
不要忽视数据安全和成本
Agent trace 里可能包含用户输入、内部知识库、工具返回、客户数据和模型输出。接入任何可观测平台前,都要明确哪些字段上报、哪些字段脱敏、保留多久、谁能访问、如何删除。还要监控 trace 存储和 eval 调用带来的额外成本。
结论:Agent 可观测性是 AI 应用进入生产后的必修课
PandaProbe Cloud vs 传统日志平台的核心差异,不在于 UI 是否更像 AI 产品,而在于它关注的对象不同。传统日志平台关注系统事件;Agent 可观测性关注一次智能任务的完整轨迹、决策过程和质量结果。
当 AI Agent 只是 demo 时,打印几行日志就够了;当它开始处理客户、调用工具、影响业务和消耗预算时,你需要 session、trace、span、LLM call、tool call、eval、monitoring 和 regression analysis。否则很多问题不会以错误码出现,只会以“用户觉得不对”“成本突然升高”“Agent 又绕圈了”的方式出现。
对开发团队来说,PandaProbe Cloud 代表的方向很清楚:AI 应用的可观测性正在从基础设施监控,升级为行为、质量和过程的持续观察。日志仍然重要,但它已经不是 Agent 调试的全部答案。
FAQ
PandaProbe Cloud 是什么?
PandaProbe Cloud 是面向 AI Agent 和 LLM 工作流的可观测平台,公开资料显示它提供托管 trace ingestion、storage、dashboard、evaluation、调度监控以及团队权限相关能力。
它和传统日志平台最大的区别是什么?
传统日志平台主要记录事件和错误;Agent 可观测性会把一次 Agent 任务拆成 session、trace、span、LLM call、tool call、decision 和 eval result,用来分析过程和质量。
有了日志平台还需要 Agent tracing 吗?
如果 AI Agent 已经进入生产,通常需要。日志可以保留系统事件,但很难直接回答模型为什么这样决策、工具是否选对、回答质量是否下降、是否发生循环或回归。
Agent 可观测性会替代 SRE 监控吗?
不会。它更像是在传统日志、指标和链路追踪之上,补充 AI Agent 层的行为轨迹和质量评估。基础设施监控仍然需要保留。
哪些指标最值得监控?
除了错误率、延迟和成本,还应监控任务完成率、工具调用成功率、工具选择正确率、引用质量、幻觉率、循环率、人工接管率、评估分数和回归趋势。
接入 Agent 可观测性要注意隐私吗?
要特别注意。Trace 可能包含用户输入、内部知识库、工具返回和模型输出。上线前应设计字段脱敏、访问控制、数据保留和删除策略。
PandaProbe Cloud 适合什么团队?
适合已经把 AI Agent、RAG、工具调用或 LLM 工作流接入真实业务,并希望快速获得 trace、dashboard、eval 和监控能力的团队。
传统日志平台还有价值吗?
有。系统错误、基础设施状态、资源指标、普通服务链路仍然需要传统日志平台。Agent 可观测性解决的是 AI 行为和质量层面的额外问题。
参考来源
本文事实信息参考 PandaProbe 官方 About、PandaProbe Cloud、PandaProbe Tracing、PandaProbe Evaluation、Product Hunt 页面 和 PandaProbe GitHub。产品能力可能变化,正式选型前请以官方最新页面为准。
会员充值与订阅排查资料
适合阅读会员充值、订阅购买、权益对比和支付问题类文章后继续转化。
