
Dify 知识库检索不准、回答胡编、文档解析失败怎么办?
检索召回 · RAG 防幻觉 · 文档解析 · 参数优化 · 企业知识库排障指南

AI Stack Nav|让 AI 技术更好地办公与创新
导读:为什么 Dify 知识库会“看起来接入了,但回答并不可靠”?
Dify 的知识库问答本质上是一个 RAG(Retrieval-Augmented Generation,检索增强生成)链路:先把企业文档解析成文本,再分段、向量化、检索、重排,最后把检索结果交给大模型生成答案。任何一个环节出现问题,都会表现为“检索不准、回答胡编、文档解析失败”。
| 提示:本文适合已经搭建 Dify 知识库,但遇到召回不准、答案乱编、PDF 解析失败、表格丢失、扫描件识别不了、上传后问答效果差等问题的用户。 |
| 问题现象 | 常见表现 | 优先排查位置 | 修复优先级 |
| 检索不准 | 搜不到正确片段、召回内容与问题无关、关键词命中但语义不对 | 分段设置、Embedding 模型、TopK、Score 阈值、Rerank、元数据过滤 | 最高 |
| 回答胡编 | 引用不存在、把多段内容拼错、没有资料也强行回答 | LLM 提示词、上下文变量、温度参数、答案约束、引用输出 | 最高 |
| 解析失败 | 上传失败、PDF 无文字、表格乱、图片文字识别不到、段落顺序错 | 原始文件质量、OCR、解析器、文件格式、知识管道 | 高 |
| 更新不生效 | 文档已替换但答案仍旧、旧版本内容混入 | 文档状态、索引重建、缓存、元数据版本、应用引用知识库 | 中 |
一、先理解 Dify 知识库问答链路
Dify 官方文档将 Knowledge 能力分为创建知识库、管理与优化知识库、检索测试、元数据增强和应用集成等环节。官方也说明,检索测试可以模拟用户问题,观察知识库是否能检索到相关内容;Knowledge Retrieval 节点则会把检索结果作为上下文传递给后续 LLM 节点。
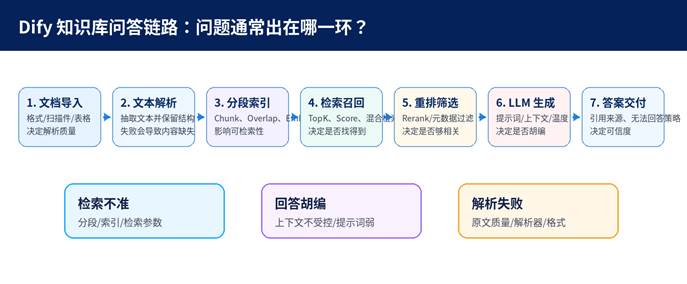
图示:Dify 知识库问答链路与三类常见故障定位。
1.1 三类故障不是同一种问题
- 检索不准:知识库里有答案,但检索阶段没有找到、找偏了,或者正确片段排在后面没有进入上下文。
- 回答胡编:检索结果可能已经命中,但 LLM 没有被严格约束,或者上下文噪声过多,导致模型自由发挥。
- 文档解析失败:源文件没有被正确转成可检索文本,后面的分段、向量化、问答都会受到影响。
1.2 排障时不要只盯着“大模型是不是不行”
很多知识库问答效果差,不是模型能力不够,而是文档解析、分段、检索和提示词链路没有优化。正确做法是先用检索测试验证“能不能召回证据”,再看 LLM 是否按证据回答。
二、Dify 知识库检索不准怎么办?
检索不准通常是最核心的问题。只要正确内容没有进入上下文,即使用更强模型也很难稳定回答。Dify 官方检索设置中涉及 Top K、Score Threshold、检索方式、Rerank 模型、混合检索、元数据过滤等参数。
2.1 常见原因
- 文档分段不合理:段落被切得太碎,答案所需信息分散在多个片段;或分段太大,噪声过多。
- 分隔符选择错误:使用了正文中频繁出现的字符作为 delimiter,导致上下文被意外切断。
- Embedding 模型不匹配:中文知识库使用弱中文向量模型,跨语言、专业术语、长句检索效果差。
- Top K 太小:只返回 1-3 个片段时,正确答案可能没有进入上下文。
- Score 阈值太高或太低:太高会召回为空,太低会引入大量低相关片段。
- 没有元数据过滤:多个部门、版本、产品线混在一个知识库时,检索范围过大。
2.2 修复步骤
1. 进入知识库的「Retrieval Testing / 检索测试」页面,输入真实用户问题,查看命中的片段是否包含答案。
2. 如果完全没有命中,先检查文档是否已成功解析、是否已完成索引、是否被归档或禁用。
3. 如果命中内容不完整,重新评估 Chunk 长度、Overlap、分隔符,并优先保证一个片段包含完整定义、条款或结论。
4. 如果命中了但排序靠后,开启 Hybrid Search 或 Rerank,提升排序精度。
5. 如果知识库很大,按文档类型、部门、年份、产品、版本增加 metadata,并在应用中启用元数据过滤。
| 提示:Dify 官方文档说明,Top K 用于控制返回的相似文本块数量,Score Threshold 用于过滤低相似度片段;Top K 默认值为 3,Score Threshold 默认值为 0.5。实际项目中应先测试召回,再决定是否提高 Top K 或调整阈值。 |
三、Dify 回答胡编怎么办?
“回答胡编”并不一定说明知识库没用。它常发生在检索结果进入了 LLM,但提示词没有明确要求“只基于资料回答”,或者上下文中包含相互矛盾的信息。
3.1 典型表现
- 回答里出现知识库没有的政策、数字、时间、联系人或链接。
- 把 A 文档的条款和 B 文档的结论混在一起。
- 用户问“有没有规定”,模型却直接编造一个结论。
- 检索结果为空时仍然给出看似专业的答案。
- 回答没有引用来源,无法追溯到原始片段。
3.2 推荐系统提示词模板
你是企业知识库问答助手。请严格根据 <context> 中的内容回答。
规则:
1. 如果 <context> 中没有足够依据,请回答“根据当前知识库无法确定”,不要自行补充。
2. 涉及数字、日期、金额、制度条款时,必须引用原文依据。
3. 如果检索片段之间存在矛盾,请指出冲突点,并建议用户核对最新文件。
4. 输出结构:结论 → 依据 → 注意事项 → 建议下一步。
3.3 让答案更可靠的配置建议
| 配置项 | 建议 | 原因 |
| 系统提示词 | 明确“只能根据知识库回答,无证据则拒答” | 降低模型自由发挥概率 |
| Temperature | 问答型场景建议偏低,如 0.1-0.4 | 减少随机性,提升稳定性 |
| 上下文变量 | 确保 LLM 节点引用 Knowledge Retrieval 的 result / context | 避免模型没有真正收到检索内容 |
| 答案结构 | 要求输出来源、依据、无法判断说明 | 方便用户核对,降低误信风险 |
| 测试集 | 准备 20-50 个真实问题持续回归测试 | 防止调参后只优化了单个问题 |
四、Dify 文档解析失败怎么办?
文档解析失败是知识库效果差的源头。Dify 的 Document Extractor 节点会把上传文件抽取为文本;官方文档说明其输出变量为 text,并会尽量保留文本结构和格式。对于复杂企业文档、扫描件、图片型 PDF、PPT、旧 DOC 等,需要额外处理或配置解析服务。
4.1 常见原因
- 扫描版 PDF 没有可选中文字,普通文本解析器无法抽取内容。
- PDF 内部是图片、表格、双栏排版、页眉页脚、水印,解析后语义顺序混乱。
- 文件过大、页数过多、包含大量图片,导致上传或解析超时。
- 旧版 DOC、PPT、EPUB 等格式需要外部解析依赖。
- CSV / Excel 表格字段名不清晰,转成 Markdown 表后缺少语义。
- 中文 OCR 识别不准确,专业词、数字、单位被识别错。
4.2 修复步骤
1. 先打开原文件,确认是否能复制正文。如果不能复制,优先做 OCR。
2. 把超大 PDF 按章节拆分,删除封面、目录、广告页、空白页和重复页眉页脚。
3. 表格类资料建议转成结构化 CSV / Excel,并把字段名写清楚,例如“产品名称、适用场景、价格、限制”。
4. 扫描件或复杂排版可使用 Dify Knowledge Pipeline 中的 Unstructured、OCR-only 或 hi_res 等解析策略。
5. 重新上传后,检查抽取文本是否完整,再做检索测试,不要直接进入应用问答。
| 提示:Dify 官方 Knowledge Pipeline 文档提到 Unstructured 可提供 auto、hi_res、fast、OCR-only 等提取策略,并可按标题、页面或相似度进行分块,适合混合文件类型和需要精细控制的企业文档流程。 |
五、参数配置参考:Chunk、Overlap、TopK、Score、Rerank 怎么调?
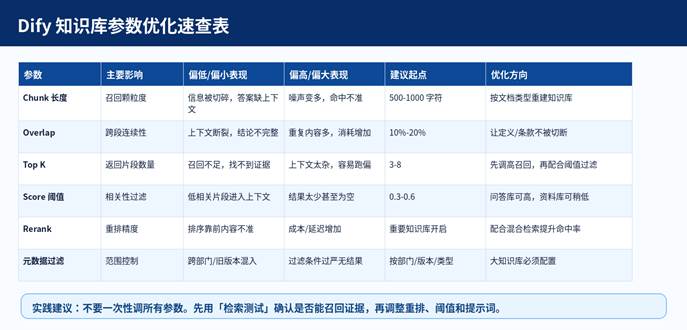
图示:Dify 知识库参数优化速查表。
5.1 按文档类型给出起步参数
| 文档类型 | 建议分段方式 | 检索策略 | 特别注意 |
| 制度/合同/政策 | 按条款或标题分段,保留上下条文 | 混合检索 + Rerank,TopK 5-8 | 必须要求引用原文,避免编造条款 |
| 产品手册/FAQ | 按问题、模块、功能点分段 | 关键词权重可稍高,Score 适中 | 添加产品版本和适用范围元数据 |
| 技术文档/API | 按函数、接口、错误码分段 | 关键词 + 语义结合 | 代码块不要被切断,保留示例 |
| 会议纪要/调研报告 | 按章节、议题、结论分段 | 语义检索权重高,TopK 6-10 | 结论和依据要在同一父级上下文中 |
| 表格数据 | 优先结构化字段,不建议整表截图 | 字段检索 + 元数据过滤 | 表头必须清晰,避免合并单元格 |
5.2 调参原则
- 先保证“能召回”:如果没有正确片段,先调分段、TopK、Embedding。
- 再保证“召回准”:如果正确片段和大量无关内容混在一起,再调 Score、Rerank、元数据过滤。
- 最后保证“回答稳”:如果检索结果正确但答案乱编,再调提示词、温度和输出格式。
- 不要只看单个问题:使用一组真实问题测试,覆盖简单问答、对比问题、边界问题和无答案问题。
六、完整排障流程:从现象到上线复测
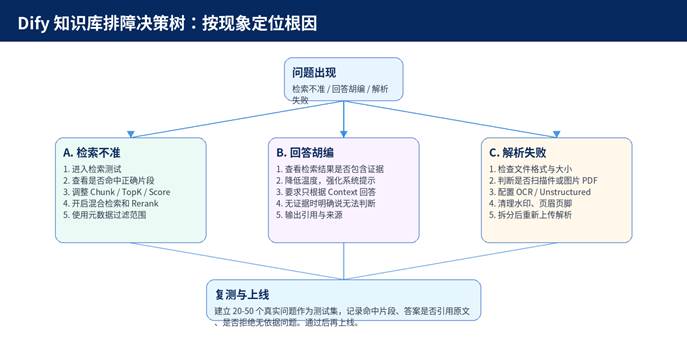
图示:Dify 知识库排障决策树。
6.1 建议保存的排障记录
| 记录项 | 示例 | 用途 |
| 用户原问题 | “2026 年报销标准是什么?” | 还原真实提问方式 |
| 检索命中片段 | 片段标题、内容、相似度、来源文件 | 判断召回是否正确 |
| 模型回答 | 原始回答全文 | 判断是否胡编或遗漏 |
| 修改动作 | TopK 从 3 调到 6,开启 Rerank | 保留优化依据 |
| 复测结果 | 是否命中、是否引用、是否拒答 | 形成可复用经验库 |
6.2 上线前检查清单
- 至少准备 20 个真实用户问题,其中包含 3-5 个知识库没有答案的问题。
- 确认每个核心问题都能检索到正确片段,并能输出可追溯来源。
- 确认无答案问题不会被模型强行编造。
- 确认旧版文档、归档文档、跨部门文档不会错误参与检索。
- 确认更新文档后会重新索引,并能在应用端生效。
七、企业知识库的安全与维护建议
- 不要把临时草稿、未审批制度、过期报价单直接加入生产知识库。
- 敏感文档应按部门、角色、项目配置访问范围,不要让所有应用共用一个大知识库。
- 建立版本字段,例如 2025 版、2026 版、已废止、试运行,避免新旧内容混答。
- 对外客服类知识库要增加“无法确认时转人工”规则。
- 定期清理重复、过期、低质量文档,避免知识库越用越乱。
八、常见问题 FAQ
Q1:Dify 知识库检索不准,第一步应该看哪里?
先看检索测试结果,而不是直接看最终回答。只有确认正确片段是否被召回,才能判断问题在检索、重排还是生成环节。
Q2:为什么我上传了 PDF,但 Dify 还是答不上来?
可能是 PDF 是扫描件、文本不可复制、解析后缺失、分段不合理或索引未完成。建议先检查抽取文本,再做 OCR 或拆分重传。
Q3:TopK 是不是越大越好?
不是。TopK 越大召回越多,但上下文噪声也会变多。通常先从 3-8 测试,配合 Score 阈值和 Rerank 使用。
Q4:回答胡编时,换更强模型能解决吗?
有帮助,但不是根本方案。更重要的是让模型只基于检索上下文回答,并在资料不足时明确拒答。
Q5:企业知识库适合使用 Parent-child 模式吗?
长文档、制度类、报告类资料通常适合,因为小片段用于匹配,大父级片段提供上下文。但知识库创建后 Chunk mode 通常不能随意切换,需提前规划。
Q6:文档解析失败是否一定要自建 OCR?
不一定。普通可复制 PDF/Word 通常不需要 OCR;扫描件、图片型 PDF、复杂版式资料才需要 OCR 或更强解析管道。
Q7:如何减少“旧资料混入新答案”?
给文档加版本、年份、状态、部门等元数据,在检索节点启用过滤,并及时归档过期文档。
Q8:为什么检索测试正常,但应用里回答仍不准?
可能是应用端的 Knowledge Retrieval 节点设置和测试页面不同,或 LLM 节点没有正确引用检索结果变量。需要检查节点级检索设置和上下文变量。
九、总结:把 Dify 知识库做准,关键是“证据链”
Dify 知识库排障不要停留在“换模型、重试、重新上传”三个动作上。更有效的做法是建立一条可验证的证据链:原始文档能解析、分段能保留语义、检索能命中证据、重排能排到前面、LLM 只基于上下文回答、最终答案能引用来源。只要沿着这条链路逐步排查,大部分检索不准、回答胡编和文档解析失败问题都能被定位并优化。
参考资料
Dify Knowledge 文档:https://docs.dify.ai/en/use-dify/knowledge/readme
Dify 索引方式与检索设置:https://docs.dify.ai/en/use-dify/knowledge/create-knowledge/setting-indexing-methods
Dify 分段与清洗设置:https://docs.dify.ai/en/use-dify/knowledge/create-knowledge/chunking-and-cleaning-text
Dify 检索测试:https://docs.dify.ai/en/use-dify/knowledge/test-retrieval
Dify Knowledge Retrieval 节点:https://docs.dify.ai/en/use-dify/nodes/knowledge-retrieval
Dify Document Extractor 节点:https://docs.dify.ai/en/use-dify/nodes/doc-extractor
Dify Knowledge Pipeline Orchestration:https://docs.dify.ai/en/use-dify/knowledge/knowledge-pipeline/knowledge-pipeline-orchestration
Dify Manage Knowledge Content:https://docs.dify.ai/en/use-dify/knowledge/manage-knowledge/maintain-knowledge-documents
会员充值与订阅排查资料
适合阅读会员充值、订阅购买、权益对比和支付问题类文章后继续转化。
