
AI 环境配置常见报错解决:CUDA 不匹配、pip 安装失败、端口占用
从显卡驱动、Python 依赖到 Docker 端口冲突,一篇搞定 AI 项目环境排错

封面图:AI 环境配置常见报错解决(16:9 网站特色图)
| 文章类型 | 网站发布教程 / 保姆级排错指南 |
| 适合人群 | AI 工具安装者、独立开发者、自媒体站长、服务器运维新手 |
| 适用场景 | Stable Diffusion、ComfyUI、Ollama、LangChain、FastAPI、Docker AI 服务 |
| 正文标题规则 | 正文一级标题使用 H2,正文二级标题使用 H3;封面主标题使用 Title 样式,不作为正文 H1 |
本文摘要
AI 环境配置失败,最常见的不是“电脑不行”,而是 CUDA、Python 依赖、端口映射这三类问题没有分清。本文用排错流程、检查命令和可复制的修复方案,把 CUDA 不匹配、pip 安装失败、端口占用三大高频报错一次讲清楚。
| 发布建议:这篇适合放在“保姆级教程 / 环境配置教程 / 问题排查教程”栏目,标题可强调“新手照着查”“不要一上来重装系统”。 |

图 1:AI 环境报错排查总流程
目录
- 为什么 AI 环境配置总是报错
- 排错前先准备:四类环境信息一次查清
- CUDA 不匹配:显卡驱动、CUDA Toolkit、框架运行时的关系
- pip 安装失败:网络、版本、wheel、依赖冲突逐个处理
- 端口占用:本地服务、Docker、WebUI 端口冲突解决
- 一套通用环境体检脚本
- 新手避坑清单
- FAQ
- 相关阅读
- 参考资料
为什么 AI 环境配置总是报错
很多 AI 项目教程会写“复制命令安装即可”,但真实环境里通常存在三层变量:操作系统版本、Python 版本、显卡驱动与依赖包版本。只要其中一层不匹配,就可能出现红字报错。
- CUDA 类报错通常发生在调用 GPU 时,关键词包括 CUDA、cuDNN、torch.cuda、libcudart、driver version、runtime version。
- pip 类报错通常发生在安装依赖阶段,关键词包括 No matching distribution、Failed building wheel、ResolutionImpossible、ReadTimeout。
- 端口类报错通常发生在启动 WebUI、API 服务或 Docker 容器时,关键词包括 address already in use、bind failed、port is already allocated。
| 核心判断:如果程序还没启动就失败,多半是 pip / Python 依赖;如果启动后调用 GPU 才失败,多半是 CUDA;如果服务启动时报端口绑定失败,多半是端口占用。 |
排错前先准备:四类环境信息一次查清
Windows / Linux / macOS 通用检查命令
先不要急着重装。把下面信息复制保存,后面判断版本是否匹配会用到。
python -V
python -m pip –version
python -c “import sys; print(sys.executable)”
python -c “import platform; print(platform.platform())”
python -m pip list
NVIDIA GPU 与 CUDA 检查命令
nvidia-smi
nvcc –version
python – <<‘PY’
try:
import torch
print(‘torch:’, torch.__version__)
print(‘cuda available:’, torch.cuda.is_available())
print(‘torch cuda:’, getattr(torch.version, ‘cuda’, None))
except Exception as e:
print(‘torch check failed:’, repr(e))
PY
端口检查命令
| 系统 | 查看端口占用 | 结束进程示例 |
| Windows | netstat -ano | findstr :端口号 | taskkill /PID 进程ID /F |
| Linux | sudo lsof -i :端口号 或 ss -ltnp | grep 端口号 | sudo kill -9 进程ID |
| macOS | lsof -i :端口号 | kill -9 进程ID |
| Docker | docker ps –format “table {{.Names}}\t{{.Ports}}” | docker stop 容器名 |
CUDA 不匹配:显卡驱动、CUDA Toolkit、框架运行时的关系
CUDA 不匹配是 AI 绘画、本地大模型、视频生成、深度学习训练最常见的环境问题。它的麻烦之处在于:你看到的 CUDA 版本,未必是同一个东西。
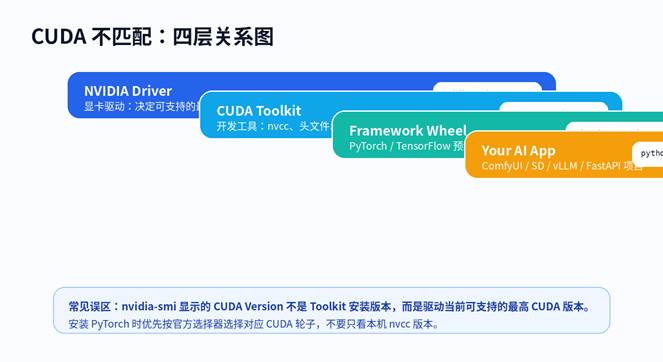
图 2:CUDA 不匹配的四层关系
先纠正一个最常见误区
nvidia-smi 显示的 “CUDA Version” 代表当前驱动可支持的最高 CUDA 版本,通常但不总是本机安装的 CUDA Toolkit 版本。真正的 Toolkit 编译工具版本要看 nvcc –version。
| 你看到的位置 | 代表什么 | 常用命令 | 排错意义 |
| Driver Version | NVIDIA 显卡驱动版本 | nvidia-smi | 判断能否支撑目标 CUDA 运行时 |
| CUDA Version in nvidia-smi | 驱动可支持的最高 CUDA 能力 | nvidia-smi | 不是 Toolkit 安装版本 |
| CUDA Toolkit | 开发工具链 / nvcc / 头文件 | nvcc –version | 源码编译、扩展编译时才关键 |
| torch.version.cuda | PyTorch 轮子绑定的 CUDA 运行时 | python -c “import torch; print(torch.version.cuda)” | 判断框架包和 GPU 是否可用 |
常见报错 1:torch.cuda.is_available() 返回 False
- 原因 A:安装的是 CPU 版 PyTorch,而不是 CUDA 版 PyTorch。
- 原因 B:NVIDIA 驱动太旧,无法支持当前 PyTorch 轮子的 CUDA 运行时。
- 原因 C:机器没有 NVIDIA GPU,或者在 Docker / WSL 中没有正确暴露 GPU。
- 原因 D:Python 环境混乱,命令装到 A 环境,运行却在 B 环境。
python -c “import torch; print(torch.__version__); print(torch.version.cuda); print(torch.cuda.is_available())”
python -c “import sys; print(sys.executable)”
python -m pip show torch
推荐修复方案:重新安装匹配的 PyTorch 版本
PyTorch 官方安装页会根据系统、安装方式、语言和计算平台生成安装命令。新手不要从随机博客复制旧命令,尤其不要混用 conda、pip 和多个 Python 环境。
# 示例:先卸载旧包,再按 PyTorch 官方选择器生成的新命令安装
python -m pip uninstall -y torch torchvision torchaudio
python -m pip cache purge
# 到 https://pytorch.org/get-started/locally/ 选择 OS / Pip / Python / CUDA 后复制命令
常见报错 2:CUDA driver version is insufficient for CUDA runtime version
这类报错的意思通常是:你安装的软件包需要更高的驱动能力,而本机 NVIDIA 驱动版本太旧。优先升级显卡驱动,而不是盲目安装多个 CUDA Toolkit。
| CUDA Toolkit 大版本 | CUDA Minor Version Compatibility 驱动范围 | 排错建议 |
| 13.x | Driver >= 580 | 使用 CUDA 13 相关软件包前,先确认驱动是否足够新 |
| 12.x | Driver >= 525 且 < 580 | 多数 2024-2026 AI 项目仍常见,升级驱动通常优先于重装 Toolkit |
| 11.x | Driver >= 450 且 < 525 | 旧项目可用,但新框架可能逐步提高 Python / CUDA 要求 |
常见报错 3:找不到 cudart / cublas / cudnn 动态库
- 如果是 PyTorch pip 预编译包,多数情况不需要单独安装完整 CUDA Toolkit;先确认是否装错了 CPU 包。
- 如果项目需要编译自定义 CUDA 扩展,才需要本机 Toolkit、编译器和系统路径都正确。
- Linux 下重点检查 LD_LIBRARY_PATH,Windows 下重点检查 PATH,避免旧 CUDA 路径排在前面。
# Linux 查看 CUDA 相关环境变量
echo $PATH
echo $LD_LIBRARY_PATH
which nvcc
# Windows PowerShell 查看 PATH 中是否有多个 CUDA 路径
$env:Path -split ‘;’ | Select-String ‘CUDA|NVIDIA’
WSL / Docker 中 GPU 不可用怎么办
- WSL:先在 Windows 宿主机安装支持 WSL 的 NVIDIA 驱动,再在 WSL 中运行 nvidia-smi 验证。
- Docker:容器需要通过 NVIDIA Container Toolkit 暴露 GPU;启动时通常需要 –gpus all。
- 容器内不要随意安装宿主机驱动;驱动属于宿主机层,容器通常使用运行时库。
docker run –rm –gpus all nvidia/cuda:12.8.0-base-ubuntu24.04 nvidia-smi
pip 安装失败:网络、版本、wheel、依赖冲突逐个处理

图 3:pip 安装失败的四类高频原因
先用虚拟环境隔离项目
每个 AI 项目都应该有自己的虚拟环境。这样一个项目的 torch、numpy、opencv 版本不会污染另一个项目。Python 官方包装指南也建议使用虚拟环境来管理第三方包。
# Linux / macOS
python3 -m venv .venv
source .venv/bin/activate
python -m pip install –upgrade pip setuptools wheel
# Windows PowerShell
py -m venv .venv
.\.venv\Scripts\Activate.ps1
python -m pip install –upgrade pip setuptools wheel
报错:ReadTimeout / Connection reset / SSL error
这是网络连接或镜像源问题。国内服务器安装大包时,torch、opencv、transformers 这类包容易超时。
# 临时使用镜像源安装
python -m pip install -i https://pypi.tuna.tsinghua.edu.cn/simple 包名
# 增加超时时间和重试次数
python -m pip install 包名 –timeout 120 –retries 5
| 注意:安装 PyTorch、TensorFlow 等带特殊轮子的框架时,优先使用官方安装命令。普通 PyPI 镜像未必包含对应 CUDA 轮子。 |
报错:No matching distribution found
- Python 版本不被当前包支持,例如项目要求 Python 3.10-3.12,你却使用 3.13 或更旧版本。
- 系统架构不匹配,例如 ARM、Windows、macOS、Linux 的 wheel 不同。
- 包名写错,或者版本号锁得太死。
- pip 太旧,识别不了新的 wheel 标签。
python -V
python -m pip –version
python -m pip index versions 包名
python -m pip install –upgrade pip
报错:Failed building wheel
这表示 pip 没有拿到可直接安装的预编译 wheel,只能尝试本地编译,但本机缺少编译工具、头文件或系统库。
| 场景 | 优先解决方案 | 不建议做法 |
| opencv / numpy / scipy 编译失败 | 升级 pip,选择支持当前 Python 的版本 | 盲目安装一堆不明来源 DLL |
| Windows 缺 C++ 编译工具 | 安装 Microsoft C++ Build Tools 或换有 wheel 的版本 | 用管理员权限反复重装 pip |
| Linux 缺系统库 | 按报错安装 python3-dev、build-essential、libxxx-dev | 只复制最后一行 ERROR 搜索 |
| AI 扩展编译失败 | 确认 CUDA Toolkit、编译器、torch CUDA 版本一致 | 同时安装多个 CUDA 目录并乱改 PATH |
报错:ResolutionImpossible / dependency conflict
这是依赖版本互相冲突。pip 官方文档建议先理解冲突链,再通过放宽或调整版本约束解决,而不是强行覆盖。
# 查看当前依赖状态
python -m pip check
# 导出当前环境,便于回滚和复现
python -m pip freeze > requirements-current.txt
# 常见做法:新建干净环境,逐步安装核心依赖
python -m venv .venv-clean
source .venv-clean/bin/activate # Windows 改为 .\.venv-clean\Scripts\Activate.ps1
python -m pip install –upgrade pip
python -m pip install torch torchvision torchaudio
python -m pip install -r requirements.txt
权限报错:Permission denied / externally-managed-environment
- 优先使用虚拟环境,不要在系统 Python 里直接 pip install。
- Linux 发行版自带 Python 可能受系统包管理器保护,强行写入会破坏系统依赖。
- 如果只是命令找不到,使用 python -m pip 而不是裸 pip,可以避免 pip 指向错误环境。
端口占用:本地服务、Docker、WebUI 端口冲突解决

图 4:Docker 端口映射中的宿主机端口与容器端口
端口占用的典型报错
- OSError: [Errno 98] Address already in use
- Error starting userland proxy: listen tcp 0.0.0.0:端口号: bind: address already in use
- Bind for 0.0.0.0:3000 failed: port is already allocated
- 端口明明改了,浏览器还是打不开:可能是防火墙、安全组或服务监听地址问题。
先查谁占用了端口
# Windows CMD
netstat -ano | findstr :7860
taskkill /PID 12345 /F
# Linux
sudo lsof -i :7860
sudo ss -ltnp | grep 7860
sudo kill -9 12345
# macOS
lsof -i :7860
kill -9 12345
Docker 端口映射不要改反
Docker 的 ports: “8080:80” 中,前面的 8080 是宿主机端口,后面的 80 是容器内部端口。Docker 官方示例也采用 HOST_PORT:CONTAINER_PORT 的解释。
services:
webui:
image: your-ai-webui:latest
ports:
– “7861:7860” # 访问宿主机 7861,转发到容器内 7860
WebUI 启动后外部访问不了
- 本机访问用 127.0.0.1 或 localhost;局域网 / 服务器访问需要服务监听 0.0.0.0。
- 云服务器需要放行安全组端口,例如 7860、3000、8000、8080。
- 不建议把未加认证的 AI WebUI 直接暴露到公网,至少加反向代理、访问密码或 VPN。
# FastAPI 示例:监听所有网卡
uvicorn app:app –host 0.0.0.0 –port 8000
# Gradio 常见写法
python app.py –listen –port 7860
开发环境避免端口冲突的办法
- 同类项目采用固定端口段,例如 AI WebUI 用 7860-7869,API 用 8000-8010,前端用 3000-3010。
- Docker Compose 中把宿主机端口写到 .env,方便一键切换。
- 测试环境可以让 Docker 自动分配临时端口,再用 docker port 查看。
# 让 Docker 自动分配宿主机端口
docker run -d -P nginx
docker port 容器ID
一套通用环境体检脚本
下面脚本适合放进项目 README 或 troubleshooting.md,让用户发报错前先运行一次。
python – <<‘PY’
import sys, platform, subprocess
print(‘Python:’, sys.version)
print(‘Executable:’, sys.executable)
print(‘Platform:’, platform.platform())
try:
import pip
print(‘pip:’, pip.__version__)
except Exception as e:
print(‘pip import failed:’, repr(e))
try:
import torch
print(‘torch:’, torch.__version__)
print(‘torch CUDA:’, getattr(torch.version, ‘cuda’, None))
print(‘cuda available:’, torch.cuda.is_available())
except Exception as e:
print(‘torch check failed:’, repr(e))
try:
out = subprocess.check_output([‘nvidia-smi’], text=True, stderr=subprocess.STDOUT, timeout=10)
print(out.split(‘
‘)[0:8])
except Exception as e:
print(‘nvidia-smi failed:’, repr(e))
PY
| 站长提示:如果你的网站有“AI 工具下载 / 本地部署教程”栏目,可以把这段脚本作为每篇教程的固定排错模块。 |
新手避坑清单
| 坑点 | 表现 | 正确做法 |
| 混用 pip 和 conda | 包显示已安装,但运行找不到 | 一个项目固定一种包管理方式 |
| 多个 Python 版本 | pip 装到旧环境,程序用新环境 | 始终使用 python -m pip |
| 只看 nvidia-smi CUDA Version | 以为 Toolkit 已安装 | 同时看 nvcc –version 和 torch.version.cuda |
| 看到红字就重装系统 | 问题反复出现 | 先记录报错关键词和环境信息 |
| Docker 端口写反 | 容器启动失败或访问错端口 | 记住 HOST_PORT:CONTAINER_PORT |
| 公网暴露 WebUI | 被扫描或滥用 | 加认证、反代、VPN 或防火墙限制 |
FAQ
nvidia-smi 显示 CUDA 12.8,为什么 PyTorch 还是不能用 GPU?
因为 nvidia-smi 显示的是驱动可支持的最高 CUDA 版本,不等于你安装了 CUDA 版 PyTorch。先检查 torch.version.cuda 和 torch.cuda.is_available()。
一定要安装 CUDA Toolkit 吗?
如果只是使用 PyTorch / TensorFlow 的预编译 GPU 包,很多情况下不需要完整 Toolkit;如果要编译 CUDA 扩展、安装源码项目或训练框架要求本地编译,才需要 Toolkit。
pip 安装失败应该先换镜像源还是先升级 pip?
建议先确认 Python 版本,再升级 pip、setuptools、wheel;网络超时再换镜像源。深度学习框架要优先使用官方安装命令。
端口被占用,直接换端口可以吗?
可以。开发环境最简单的办法是换宿主机端口;但生产环境要确认反向代理、文档、环境变量、开放端口都同步修改。
为什么同样命令别人能装,我装不上?
常见差异包括 Python 版本、系统架构、显卡驱动、代理网络、镜像源、是否在虚拟环境中。AI 环境排错的第一步就是把这些信息查出来。
Docker 容器内端口和宿主机端口有什么区别?
容器内端口是应用在容器里的监听端口;宿主机端口是你从浏览器或外部访问的端口。Docker Compose 通常写成 HOST_PORT:CONTAINER_PORT。
参考资料
- NVIDIA CUDA Compatibility Guide:https://docs.nvidia.com/deploy/cuda-compatibility/
- NVIDIA CUDA Toolkit Release Notes:https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html
- NVIDIA nvidia-smi Documentation:https://docs.nvidia.com/deploy/nvidia-smi/
- PyTorch Get Started Locally:https://pytorch.org/get-started/locally/
- Python Packaging User Guide: pip and venv:https://packaging.python.org/en/latest/guides/installing-using-pip-and-virtual-environments/
- pip Dependency Resolution:https://pip.pypa.io/en/stable/topics/dependency-resolution/
- Docker Docs: Publishing and exposing ports:https://docs.docker.com/get-started/docker-concepts/running-containers/publishing-ports/
- Docker Docs: Port publishing and mapping:https://docs.docker.com/engine/network/port-publishing/
会员充值与订阅排查资料
适合阅读会员充值、订阅购买、权益对比和支付问题类文章后继续转化。
