
FastGPT 搭建企业知识库教程:数据导入、问答测试和权限设置
AI Stack Nav 网站发布版|Docker 部署 · 数据导入 · RAG 问答 · 权限上线
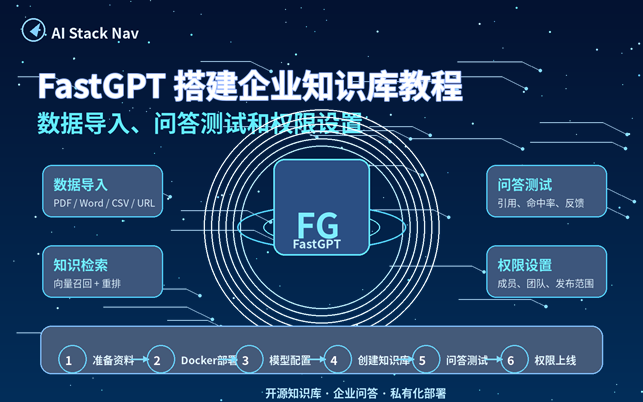
封面图:FastGPT 企业知识库搭建全流程
导读:FastGPT 适合把企业内部制度、产品文档、售后 FAQ、销售话术、项目资料整理成可检索、可引用、可权限控制的知识库问答系统。本文按“环境准备 → Docker 部署 → 模型配置 → 数据导入 → 问答测试 → 权限设置 → 上线维护”的顺序,给出一套适合普通团队照着操作的保姆级流程。
H2 一、FastGPT 是什么?适合解决哪些企业知识问题
FastGPT 是一个基于大语言模型的 AI Agent/知识库应用平台,官方介绍强调其具备数据处理、模型调用和可视化 Flow 编排能力,适合构建知识库问答、智能客服、内部助手和复杂业务工作流。
H3 1.1 它和普通聊天机器人的区别
- 普通聊天机器人主要依赖模型通用知识,容易出现“答得像但不一定准”的问题;FastGPT 的核心价值在于把回答锚定到企业自己的资料。
- FastGPT 支持知识库检索、引用反馈、知识片段编辑和多库混用,企业可以根据资料变更持续更新索引。
- 除问答外,它还支持应用编排、工作流、API 接口和嵌入式发布,适合从内部试点扩展到业务系统。
H3 1.2 适合落地的典型场景
| 场景 | 可导入资料 | 典型问题 | 落地价值 |
| 客服知识库 | 售后政策、FAQ、产品手册 | 这个故障怎么处理? | 降低重复咨询,提高回复一致性 |
| 企业制度问答 | 员工手册、报销制度、请假流程 | 试用期能请假吗? | 减少 HR/行政重复解释 |
| 销售支持助手 | 产品介绍、报价口径、案例库 | 这个客户适合哪个方案? | 统一销售话术和方案输出 |
| 项目文档助手 | 需求文档、接口文档、会议纪要 | 某接口字段含义是什么? | 加快新人理解和项目交接 |
H2 二、整体架构:从资料到可问答应用的链路
FastGPT 企业知识库不是“上传文件就完事”,而是由数据源、解析索引、模型调用、应用发布和权限治理共同构成。搭建前先理解整体架构,后续排错会更顺。
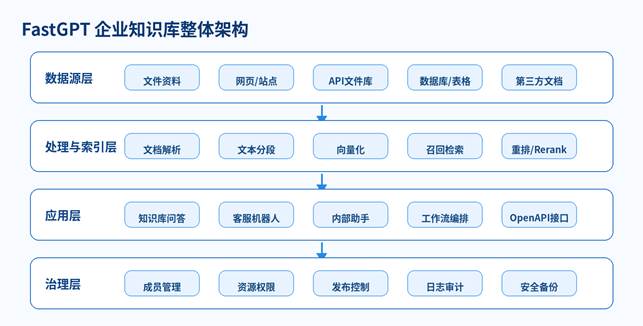
图 1:FastGPT 企业知识库整体架构
H3 2.1 核心组件说明
| 模块 | 作用 | 新手关注点 |
| FastGPT 主服务 | 提供 Web 界面、应用、知识库和对话能力 | 确认 3000 端口、登录账号和服务状态 |
| MongoDB | 存储业务数据、配置和对话等非向量数据 | 必须注意备份,避免升级或迁移时丢数据 |
| PostgreSQL / Milvus 等向量库 | 存储向量索引,支持语义检索 | 小规模可优先 PgVector,大规模再考虑 Milvus |
| AIProxy / 模型供应商 | 聚合和调用对话模型、索引模型等 | 先确保模型 Key 可用,再回到 FastGPT 配置 |
| 对象存储 / 文件服务 | 存储上传文件或附件 | 涉及导出、语音、文件预览时需关注域名与 HTTPS |
H2 三、搭建前准备:服务器、Docker、域名和资料
H3 3.1 服务器配置建议
官方 Docker Compose 文档给出了不同向量库方案的推荐配置:PgVector 版本相对轻量,适合知识库索引量低于 5000 万;Milvus 更适合 1 亿以上向量的大规模场景。新手建议先从 PgVector 版本开始,稳定后再根据数据规模升级。
| 使用规模 | 建议配置 | 适合情况 | 备注 |
| 测试/学习 | 2 核 4G 起步,建议 2 核 8G | 个人试用、功能验证 | 资料少时足够,注意关闭无关服务 |
| 小团队知识库 | 4 核 8G + 50GB 磁盘起步 | 制度、FAQ、产品资料 | 推荐 PgVector,维护成本低 |
| 中大型企业 | 8 核 32G + 200GB 起步 | 多业务线、多知识库 | 可评估 Milvus / SeekDB / 托管向量库 |
| 公网发布 | 服务器 + 域名 + HTTPS | 客服机器人、网页嵌入 | 注意安全策略和访问权限 |
H3 3.2 资料准备清单
- 优先准备结构清晰的 Word、PDF、Markdown、TXT、Excel、CSV 文件,删除旧版本、重复文件和无关图片。
- 每份资料建议带上标题、版本、生效日期、适用范围,例如“2026 员工报销制度-财务部-正式版”。
- 敏感资料要先做权限分级,不要把薪资、身份证、合同金额等高敏信息直接放入公共知识库。
- 把常见问答整理成 CSV 或 QA 对,这类资料最适合做高准确率问答。
H2 四、Docker 部署 FastGPT:一步一步跑通服务
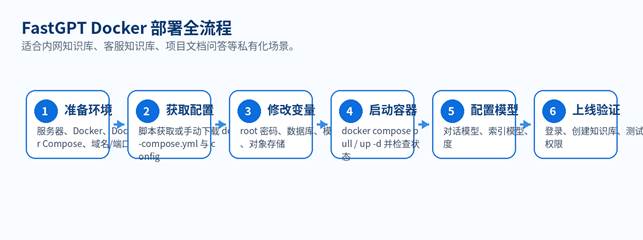
图 2:FastGPT Docker 部署全流程
H3 4.1 获取部署配置
官方 README 和 Docker Compose 文档都提供了通过脚本获取配置并启动服务的方式。Linux、macOS 或 Windows WSL 环境可优先使用交互式脚本;网络受限或需要精细控制时,可手动下载 docker-compose.yml 与 config.json。
| # 获取配置文件(Linux / macOS / Windows WSL) bash <(curl -fsSL https://doc.fastgpt.cn/deploy/install.sh) # 在 docker-compose.yml 所在目录启动 docker compose up -d # 查看容器状态 docker compose ps |
H3 4.2 首次登录与基础检查
- 浏览器访问服务器的 3000 端口或已绑定的域名。
- 使用 root 账号登录,默认密码取决于部署配置中的 DEFAULT_ROOT_PSW;官方 README 示例为 1234。
- 首次进入系统后,优先检查“模型供应商/模型配置”是否已配置语言模型和索引模型。
- 若登录网络错误,先看 docker compose logs;官方排错说明中常见原因包括配置 JSON 解析错误或向量数据库连接失败。
H3 4.3 常见端口和服务
| 项目 | 默认/常见用途 | 检查方式 |
| 3000 | FastGPT Web 主服务 | 浏览器打开 http://服务器IP:3000 |
| 9000 | S3/对象存储服务相关 | 涉及文件、导出、语音时重点排查 |
| 3005 | SSE MCP server 服务 | 需要 MCP / 工具调用时关注 |
| MongoDB / 向量库 | 数据与向量索引存储 | 查看容器日志和连接状态 |
H2 五、模型配置:对话模型、向量模型和重排模型怎么选
FastGPT 搭好后不能直接高质量问答,必须配置模型。最少要有两类:用于生成回答的语言模型,以及用于把文本转成向量的索引/Embedding 模型。需要更好检索效果时,再增加 Rerank 重排模型。
H3 5.1 对话模型配置建议
| 模型类型 | 作用 | 选择建议 |
| 对话模型 / LLM | 理解问题、组织答案、生成最终回复 | 选稳定、成本可控、上下文足够的模型 |
| Embedding 模型 | 把资料和问题转成向量,决定检索基础效果 | 尽量选择中文表现好的向量模型,并与资料语言匹配 |
| Rerank 模型 | 对召回片段重新排序,提高命中准确度 | 企业知识库建议开启,尤其资料多、问题复杂时 |
| 语音/多模态模型 | 用于语音输入输出或图像文档理解 | 按业务需要配置,不是基础问答必选项 |
H3 5.2 配置时最容易踩坑的地方
- 不要只配置 Chat 模型而忘记索引模型,否则知识库无法正常向量化。
- 模型供应商的 Base URL、API Key、模型名称要逐字核对,尤其本地模型或中转平台。
- 不同模型上下文长度不同,大文件问答时要控制分段长度和召回数量,避免把大量无关片段塞进上下文。
- 测试阶段建议先用小规模资料验证模型、索引、检索链路,再批量导入正式知识库。
H2 六、企业知识库数据导入全流程
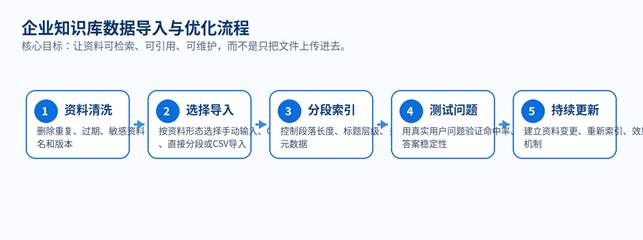
图 3:企业知识库数据导入与优化流程
H3 6.1 FastGPT 支持哪些导入方式
官方快速入门文档列出四种常见上传模式:手动输入 QA、QA 拆分、直接分段、CSV 导入。官方 README 还提到知识库支持 txt、md、html、pdf、docx、pptx、csv、xlsx 等格式,并支持 URL 读取、CSV 批量导入和 API 知识库。
| 导入方式 | 适合资料 | 优点 | 注意事项 |
| 手动输入 QA | 标准 FAQ、客服话术 | 准确率高、可控性强 | 前期整理成本高 |
| QA 拆分 | 制度、说明文档、教程 | 可自动生成问答对 | 生成后要人工抽查 |
| 直接分段 | 长文档、技术文档、产品手册 | 保留原文结构,适合引用 | 依赖分段质量和标题层级 |
| CSV 导入 | 已有问答表、知识表格 | 批量高效,结构清晰 | 列名和格式需提前规范 |
| API 文件库 | 已有企业文档系统 | 可连接现有文档库,避免重复存储 | 需要开发符合规范的接口 |
H3 6.2 文档分段建议
- 制度类资料:按“章节标题 + 条款 + 适用范围”分段,不要把整份制度切成没有上下文的小句子。
- 产品手册:按功能模块、问题场景、操作步骤拆分,每个片段尽量能独立回答一个问题。
- 销售资料:把产品卖点、适合客户、竞品差异、报价口径拆成结构化问答或表格。
- 技术文档:保留接口路径、字段、错误码、版本号,避免分段时把代码块和解释拆散。
H3 6.3 API 文件库适合什么情况
如果企业已经有现成文档系统,不想把资料重复上传到 FastGPT,可以考虑 API 文件库。官方文档说明,创建知识库时可选择 API File Library 类型,配置文件服务的 baseURL、Authorization 请求头和可选 basePath,系统会通过符合规范的接口获取文件列表并选择性导入。
H2 七、问答测试与效果评估:不要只看“能不能回答”
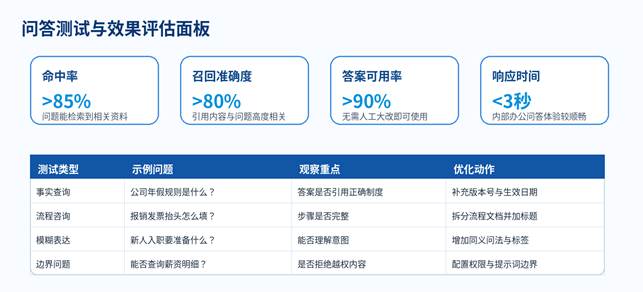
图 4:问答测试与效果评估面板
H3 7.1 测试问题怎么设计
- 真实问题:从客服记录、群聊、工单、销售对话中选高频问题,而不是只问文档标题。
- 边界问题:故意问权限外、资料没有、过期政策相关问题,测试系统是否会胡编。
- 多轮问题:先问规则,再追问例外情况,测试上下文和引用是否稳定。
- 模糊问题:用用户真实表达方式提问,例如“这个能不能报销”“新人该找谁”。
H3 7.2 三个关键指标
| 指标 | 判断标准 | 优化方向 |
| 命中率 | 能否检索到正确知识片段 | 补充同义词、标题、标签、关键词 |
| 引用准确率 | 引用内容是否支持答案 | 调整分段、开启重排、减少无关召回 |
| 答案可用率 | 回答是否能直接给用户使用 | 优化提示词、增加输出格式要求 |
| 拒答能力 | 资料没有或越权时是否拒答 | 加系统提示词和权限边界 |
H3 7.3 优化闭环
- 记录测试问题、召回片段、回答内容、人工评分和修改建议。
- 先优化资料结构,再调分段和召回参数,最后再换模型。
- 把“错误答案”转成新增 FAQ 或补充文档,而不是只在提示词里硬修。
- 每次新增资料后,抽样测试旧问题,避免新资料影响旧答案。
H2 八、权限设置与安全管理
企业知识库最怕两类问题:一是“该看的人看不到”,二是“不该看的人看到了”。FastGPT 官方团队权限文档说明,管理团队权限时先选择成员、组织或分组,再配置权限;对于应用和知识库等资源,可以直接修改成员权限。
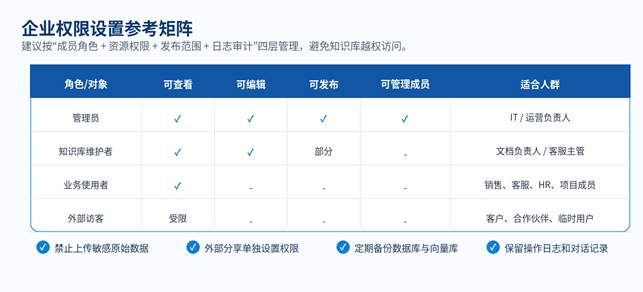
图 5:企业权限设置参考矩阵
H3 8.1 权限设置原则
- 按岗位分组:例如管理员、知识库维护者、业务使用者、外部访客。
- 按资源授权:不同知识库、不同应用分别设置权限,不要所有人都默认全可见。
- 发布前先隔离测试:内部测试链接、网页嵌入、API 调用要区分权限。
- 敏感知识库单独管理:财务、人事、合同、客户资料不要和公共 FAQ 混在一起。
H3 8.2 对外发布前检查
| 检查项 | 建议做法 |
| 访问范围 | 确认只有指定成员、指定团队或指定渠道可访问 |
| 模型输出边界 | 要求模型在资料不足时说明“不确定/未检索到依据” |
| 引用与日志 | 保留引用来源和对话记录,方便复盘 |
| 数据备份 | 定期备份 MongoDB、向量库和关键配置文件 |
| HTTPS 与域名 | 公网发布建议启用 HTTPS,避免浏览器安全限制和数据泄露风险 |
H2 九、适合企业落地的 5 个实战模板
| 模板 | 导入资料 | 推荐配置 | 输出效果 |
| 售后客服问答 | FAQ、故障处理、质保政策 | 知识库 + Chat Guide + 引用显示 | 标准化回复和处理建议 |
| HR 制度助手 | 员工手册、请假报销流程 | 知识库 + 权限控制 | 员工自助查询制度 |
| 销售方案助手 | 产品资料、案例、报价规则 | 知识库 + 工作流模板 | 生成客户方案草稿 |
| 技术文档助手 | 接口文档、部署文档、错误码 | 知识库 + 代码/格式输出约束 | 辅助开发排障 |
| 内部培训助手 | 培训课件、SOP、考试题库 | 知识库 + 问答测试集 | 新人学习与考核支持 |
H2 十、常见问题 FAQ
H3 FastGPT 适合零基础用户吗?
适合照教程部署和使用,但本地部署仍需要基本服务器、Docker、端口和域名知识。如果完全不想运维,可以先使用云版或找技术人员协助。
H3 知识库回答不准,通常是什么原因?
常见原因是资料本身混乱、分段过碎或过长、索引模型不合适、没有启用重排、问题表达与资料标题差距太大。建议先优化资料和分段,再调整模型。
H3 可以直接上传 PDF 吗?
可以。官方 README 提到支持 PDF、docx、pptx、csv、xlsx 等格式,但扫描版 PDF 可能需要先 OCR,图片多的文件也建议转成结构化文本。
H3 权限设置是不是开源版都有?
基础的团队、成员和资源权限需要以实际版本为准。企业级精细权限、SSO、外部成员同步等能力可能与商业版或部署配置有关,正式上线前要以官方版本说明为准。
H3 企业知识库是否可以对接现有文档系统?
可以考虑 API 文件库、钉钉知识库、语雀、飞书等第三方知识库接入方式。API 文件库需要提供符合 FastGPT 规范的文件列表和文件内容接口。
H3 上线后最重要的维护动作是什么?
定期更新资料、抽测高频问题、备份数据库和向量库、检查权限变更、复盘错误回答,并把错误回答沉淀为新增 FAQ。
H2 十一、总结:FastGPT 的关键不是部署,而是把知识库做“可维护”
FastGPT 本地部署只是第一步。真正决定企业知识库效果的,是资料治理、分段质量、模型配置、问答测试和权限管理。建议先用一个小场景试点,例如客服 FAQ 或员工制度问答,跑通“导入—测试—修正—上线—复盘”的闭环,再逐步扩展到销售、项目、技术文档和业务流程。
H2 参考资料
- FastGPT 官方 Docker Compose 部署文档:https://doc.fastgpt.io/en/self-host/deploy/docker
- FastGPT 官方 Quick Start 文档:https://doc.fastgpt.io/en/guide/getting-started/quick-start
- FastGPT API File Library 文档:https://doc.fastgpt.io/en/guide/dataset/third-party/api_dataset
- FastGPT GitHub README:https://github.com/labring/FastGPT/blob/main/README_en.md
- FastGPT Teams, Groups & Permissions 文档:https://doc.fastgpt.io/en/guide/workspace/team/team_roles_permissions
- Docker Compose 官方文档:https://docs.docker.com/compose/
环境配置与 Docker 工作流
适合阅读安装部署、本地配置、服务器搭建和自动化流程类文章后继续转化。
