

《Linux 服务器 AI 环境配置入门指南》
适用场景:云服务器、GPU 工作站、AI 推理服务器、自动化工作流服务器、本地大模型部署服务器。
文章摘要
这是一篇面向新手的 Linux 服务器 AI 环境配置教程,围绕“服务器能登录、Python 能跑、Git 能拉代码、GPU 能识别、Docker 能部署、模型服务能访问”这条主线展开。文章从系统选择、SSH 安全、基础依赖、Python 虚拟环境、CUDA/NVIDIA 驱动、Docker 与 GPU 容器、PyTorch/TensorFlow 验证、Ollama/vLLM/Open WebUI 等本地 AI 工具部署,到常见报错排查与 SEO 发布信息,提供一套可直接照做的入门方案。
| 一句话结论:Linux AI 环境搭建不要从“装模型”开始,而要按“系统安全 → Python/Git → GPU 驱动 → Docker → AI 框架验证 → 模型服务部署”的顺序推进。 |
目录
- 一、为什么 AI 工具更适合部署在 Linux 服务器上
- 二、安装前准备:服务器、系统、账号和网络
- 三、第一步:登录服务器并做好基础安全配置
- 四、第二步:安装 Python、Git 与基础编译环境
- 五、第三步:配置虚拟环境:venv、Conda 与 uv 怎么选
- 六、第四步:配置 VS Code Remote SSH 远程开发
- 七、第五步:NVIDIA 驱动、CUDA 与 GPU 验证
- 八、第六步:安装 Docker 与 GPU 容器环境
- 九、第七步:安装 PyTorch / TensorFlow / JupyterLab 并验证
- 十、第八步:部署 Ollama、Open WebUI、vLLM 等本地 AI 服务
- 十一、常见问题排查
- 十二、FAQ、相关阅读与 SEO 文档
封面图

图示说明:Linux 服务器 AI 环境配置的核心路径是从 SSH 登录开始,逐步完成 Python、GPU、Docker 与模型服务部署。
一、为什么 AI 工具更适合部署在 Linux 服务器上
如果只是写提示词、调用网页 AI 工具,普通电脑已经够用;但一旦进入本地大模型、批量任务、自动化工作流、API 服务、GPU 推理、RAG 知识库、图片生成或长期后台运行,Linux 服务器就会明显更适合。
- 稳定性更好:Linux 适合长时间运行 API、队列任务、Webhook、自动发布脚本。
- 生态更完整:Docker、CUDA、PyTorch、vLLM、Ollama、ComfyUI、Dify、n8n 等在 Linux 上资料最多。
- 远程协作方便:一台服务器可以多人 SSH、多人部署服务,也方便接入 Git。
- 更接近生产环境:如果后续要把 AI 应用上线,Linux + Docker 是最常见的部署组合。
- GPU 支持更成熟:NVIDIA 驱动、CUDA、容器运行时、深度学习框架在 Linux 上更适合生产使用。
| 新手建议先用 Ubuntu LTS 练手。Ubuntu 软件包、NVIDIA 驱动、Docker 文档和社区教程都更完整;等熟悉后,再迁移到 Debian、Rocky Linux 或企业发行版。 |
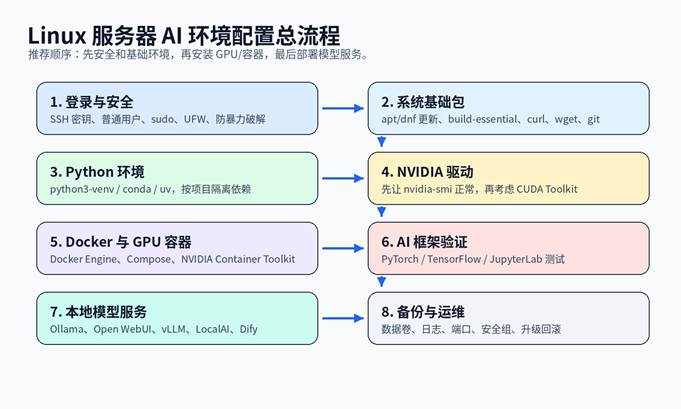
二、安装前准备:服务器、系统、账号和网络
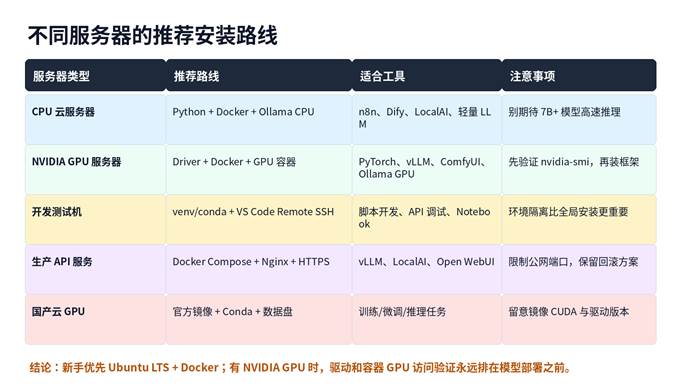
1. 推荐系统怎么选
| 系统 | 适合人群 | 优点 | 建议 |
| Ubuntu 24.04 LTS | 新手、云服务器、GPU 服务器 | 资料最多,AI 工具兼容性好 | 当前最稳妥的入门选择 |
| Ubuntu 26.04 LTS | 新装服务器、愿意使用较新系统的人 | 新 LTS,生命周期长 | 等云厂商镜像和驱动生态稳定后再大规模使用 |
| Debian 12/13 | 追求简洁稳定的人 | 系统干净,适合 Docker 服务 | 部分 AI 工具需要手动补依赖 |
| Rocky Linux 9/10 | 企业服务器、RHEL 生态 | 适合企业运维规范 | NVIDIA/EPEL/SELinux 配置要更谨慎 |
| 国产云镜像 | 阿里云、腾讯云、华为云等 GPU 实例 | 有预装驱动/框架镜像 | 优先选择官方 AI 镜像,少折腾驱动 |
2. 服务器配置建议
| 用途 | CPU | 内存 | GPU/显存 | 磁盘 |
| 基础脚本/自动化 | 2 核以上 | 2GB-4GB | 不需要 | 30GB+ |
| n8n/Dify/轻量 API | 2-4 核 | 4GB-8GB | 可选 | 50GB-100GB |
| Ollama 7B CPU 测试 | 4 核以上 | 16GB+ | 可选 | 100GB+ |
| 7B/14B GPU 推理 | 8 核以上 | 32GB+ | 8GB-24GB 显存 | 200GB+ SSD |
| vLLM/多并发服务 | 16 核以上 | 64GB+ | 24GB+ 显存,越多越好 | 500GB+ SSD |
| 显存不是越“能启动”越好。生产推理还要考虑上下文长度、并发数、KV Cache、量化格式和吞吐量。新手部署 7B 模型,8GB-16GB 显存更容易成功;部署 14B/32B 或多并发,建议 24GB 以上。 |
三、第一步:登录服务器并做好基础安全配置
服务器环境搭建的第一步不是安装 Python,而是确认你能稳定、安全地登录。尤其是公网云服务器,22 端口暴露后会被持续扫描,建议尽快改用 SSH 密钥、普通用户、最小开放端口。
1. 首次登录与系统信息检查
# 用你的服务器 IP、用户名替换下面内容
ssh root@服务器公网IP
# 查看系统版本、内核、CPU、内存、磁盘
cat /etc/os-release
uname -a
lscpu
free -h
df -h
2. 更新系统并安装常用工具
# Ubuntu / Debian
sudo apt update && sudo apt upgrade -y
sudo apt install -y curl wget git vim htop tmux unzip zip ca-certificates gnupg lsb-release software-properties-common build-essential pkg-config
# Rocky / RHEL / CentOS Stream
sudo dnf update -y
sudo dnf install -y curl wget git vim htop tmux unzip zip ca-certificates gnupg gcc gcc-c++ make pkgconfig
3. 创建普通用户并配置 sudo
# Ubuntu / Debian
adduser aiuser
usermod -aG sudo aiuser
# Rocky / RHEL
adduser aiuser
usermod -aG wheel aiuser
# 切换用户测试
su – aiuser
sudo whoami
| 不要长期用 root 直接跑 AI 服务。建议创建普通用户,再给必要 sudo 权限。Docker、模型目录、项目目录都应放在普通用户或专门服务用户下,方便权限管理和迁移。 |
4. 防火墙与端口规划
# Ubuntu UFW 示例:先放行 SSH,再启用防火墙
sudo ufw allow OpenSSH
sudo ufw allow 22/tcp
sudo ufw enable
sudo ufw status verbose
# 如果你需要临时访问服务,可按需放行。例如:
sudo ufw allow 8000/tcp # vLLM / FastAPI
sudo ufw allow 8080/tcp # Open WebUI / LocalAI 等
sudo ufw allow 11434/tcp # Ollama,公网慎开
| 公网服务器不要随便开放 Ollama 的 11434、vLLM 的 8000、Open WebUI 的 8080。生产环境建议放在 Nginx/Caddy 反向代理后面,并加 HTTPS、账号认证、防火墙白名单。 |
四、第二步:安装 Python、Git 与基础编译环境
AI 工具部署离不开 Python,但 Linux 服务器上一定要区分“系统 Python”和“项目 Python”。系统 Python 用来支持系统工具,不建议乱升级;项目依赖放进 venv、conda 或 uv 创建的环境。
1. 安装 Python 基础组件
# Ubuntu / Debian
sudo apt install -y python3 python3-pip python3-venv python3-dev
python3 –version
pip3 –version
# Rocky / RHEL
sudo dnf install -y python3 python3-pip python3-devel
python3 –version
pip3 –version
2. 安装 Git 并配置身份
git –version
git config –global user.name “Your Name”
git config –global user.email “[email protected]”
git config –global init.defaultBranch main
git config –global –list
3. 创建项目目录
mkdir -p ~/ai-projects ~/models ~/datasets ~/docker-data
cd ~/ai-projects
五、第三步:配置虚拟环境:venv、Conda 与 uv 怎么选
| 方案 | 适合场景 | 优点 | 命令示例 |
| venv | 通用 Python 项目、轻量脚本 | 标准库自带,简单稳定 | python3 -m venv .venv |
| Conda / Miniconda | 数据科学、复杂依赖、多 Python 版本 | 环境隔离强,适合科学计算 | conda create -n ai python=3.12 |
| uv | 新项目、追求安装速度 | 依赖解析快,可管理项目 | uv init / uv add |
| Docker | 生产部署、服务交付 | 环境可复制,方便迁移 | docker compose up -d |
1. venv:最推荐的新手入门方式
cd ~/ai-projects
mkdir demo && cd demo
python3 -m venv .venv
source .venv/bin/activate
python -m pip install –upgrade pip setuptools wheel
python -m pip install requests rich
python – <<‘PY’
import sys, requests
print(sys.executable)
print(requests.__version__)
PY
2. Miniconda:适合数据科学和多环境
# 下载并安装时,请以官网最新安装脚本为准;这里是常见 x86_64 示例
mkdir -p ~/miniconda3
# bash Miniconda3-latest-Linux-x86_64.sh -b -u -p ~/miniconda3
# ~/miniconda3/bin/conda init bash
conda create -n ai python=3.12 -y
conda activate ai
python –version
3. uv:更快的现代 Python 工具链
curl -LsSf https://astral.sh/uv/install.sh | sh
source ~/.bashrc
uv –version
uv init ai-demo
cd ai-demo
uv add requests rich
uv run python -c “import requests; print(requests.__version__)”
六、第四步:配置 VS Code Remote SSH 远程开发
Linux 服务器一般没有桌面环境,也不建议为了写代码去安装图形化 VS Code。正确姿势是:在本地电脑安装 VS Code,再通过 Remote SSH 插件连接服务器。代码、终端、插件运行在服务器上,界面显示在你的本地电脑上。
- 本地电脑安装 VS Code。
- 在 VS Code 扩展市场安装 Remote – SSH。
- 本地终端先测试:ssh aiuser@服务器公网IP。
- VS Code 中按 Ctrl+Shift+P,输入 Remote-SSH: Connect to Host。
- 连接成功后打开服务器上的 ~/ai-projects 目录。
- 在远程环境安装 Python、Jupyter、Docker、GitHub Copilot、Cline、Continue 等插件。
# 本地电脑生成 SSH key,Windows/macOS/Linux 都可以使用 OpenSSH
ssh-keygen -t ed25519 -C “ai-server”
# 把公钥复制到服务器,Linux/macOS 可用 ssh-copy-id
ssh-copy-id aiuser@服务器公网IP
# Windows 可手动把 id_ed25519.pub 内容追加到服务器:
# ~/.ssh/authorized_keys
| 如果 Remote SSH 卡在 Installing VS Code Server,通常是服务器网络、磁盘空间、权限或旧版 VS Code Server 残留问题。先执行 df -h、free -h,再清理 ~/.vscode-server 后重连。 |
七、第五步:NVIDIA 驱动、CUDA 与 GPU 验证
这是 Linux AI 环境里最容易装乱的一步。记住一个原则:先让 NVIDIA 驱动和 nvidia-smi 正常,再安装 PyTorch、TensorFlow、vLLM 等框架。很多时候,跑 PyTorch 并不要求你手动安装完整 CUDA Toolkit,因为 PyTorch wheel 会自带所需 CUDA runtime;但你仍然需要正确的 NVIDIA 驱动。
1. 检查是否有 NVIDIA GPU
lspci | grep -i nvidia || true
ubuntu-drivers devices || true
nvidia-smi || true
2. Ubuntu 安装 NVIDIA 驱动的常见路线
# Ubuntu:推荐先查看系统建议的驱动
sudo apt update
ubuntu-drivers devices
# 方式一:自动安装推荐驱动
sudo ubuntu-drivers autoinstall
sudo reboot
# 重启后验证
nvidia-smi
| 如果服务器开启了 Secure Boot,NVIDIA 内核模块可能无法加载,需要签名或关闭 Secure Boot。云服务器一般不涉及本地 BIOS 设置,但物理服务器和工作站要重点检查。 |
3. CUDA Toolkit 要不要装?
| 场景 | 是否需要 CUDA Toolkit | 建议 |
| 只跑 PyTorch / vLLM / Ollama 推理 | 通常不必先装完整 Toolkit | 先装驱动,再按框架官方命令安装 |
| 需要编译 CUDA 扩展 | 需要 | 按 NVIDIA 官方 CUDA 下载页选择系统版本 |
| Docker GPU 容器 | 主机需驱动 + NVIDIA Container Toolkit | 容器镜像内带 CUDA runtime 或 devel 环境 |
| 训练/自定义算子开发 | 通常需要 | 固定驱动、CUDA、cuDNN、PyTorch 版本组合 |
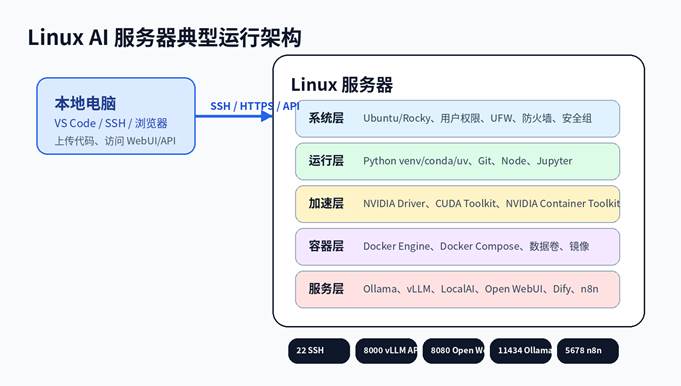
八、第六步:安装 Docker 与 GPU 容器环境
Docker 是把 AI 工具部署到 Linux 服务器上的核心工具。对于 n8n、Dify、Open WebUI、LocalAI、ComfyUI、vLLM 等服务,Docker Compose 可以显著降低部署复杂度。
1. Ubuntu 安装 Docker Engine
# 卸载可能冲突的旧包
for pkg in docker.io docker-doc docker-compose docker-compose-v2 podman-docker containerd runc; do
sudo apt-get remove -y $pkg || true
done
sudo apt-get update
sudo apt-get install -y ca-certificates curl
sudo install -m 0755 -d /etc/apt/keyrings
sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc
sudo chmod a+r /etc/apt/keyrings/docker.asc
echo \
“deb [arch=$(dpkg –print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/ubuntu \
$(. /etc/os-release && echo ${UBUNTU_CODENAME:-$VERSION_CODENAME}) stable” | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt-get update
sudo apt-get install -y docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
sudo docker run hello-world
2. 允许普通用户运行 Docker
sudo usermod -aG docker $USER
# 退出 SSH 后重新登录,再测试:
docker version
docker compose version
| docker 用户组权限很高,接近 root。个人测试可以加入 docker 组;生产服务器要控制成员,避免把 docker socket 暴露给不可信用户或公网容器。 |
3. 安装 NVIDIA Container Toolkit
# Ubuntu / Debian 常见步骤,以 NVIDIA 官方文档为准
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | \
sudo gpg –dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed ‘s#deb https://#deb
[signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg]
https://#g’ | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt-get update
sudo apt-get install -y nvidia-container-toolkit
sudo nvidia-ctk runtime configure –runtime=docker
sudo systemctl restart docker
# 验证容器内能看到 GPU
sudo docker run –rm –gpus all nvidia/cuda:12.8.0-base-ubuntu24.04 nvidia-smi
九、第七步:安装 PyTorch / TensorFlow / JupyterLab 并验证
1. PyTorch 验证 GPU
cd ~/ai-projects
mkdir torch-test && cd torch-test
python3 -m venv .venv
source .venv/bin/activate
python -m pip install –upgrade pip
# 请以 PyTorch 官网选择器生成的命令为准;示例为 Linux + pip + CUDA 12.8
pip install torch torchvision torchaudio –index-url https://download.pytorch.org/whl/cu128
python – <<‘PY’
import torch
print(‘torch:’, torch.__version__)
print(‘cuda available:’, torch.cuda.is_available())
if torch.cuda.is_available():
print(‘gpu:’, torch.cuda.get_device_name(0))
x = torch.randn(1024, 1024, device=’cuda’)
print(‘ok:’, x @ x)
PY
2. TensorFlow 验证 GPU
python3 -m venv ~/ai-projects/tf
source ~/ai-projects/tf/bin/activate
python -m pip install –upgrade pip
pip install ‘tensorflow[and-cuda]’
python3 -c “import tensorflow as tf; print(tf.config.list_physical_devices(‘GPU’))”
3. JupyterLab 远程访问
python3 -m venv ~/ai-projects/jupyter
source ~/ai-projects/jupyter/bin/activate
pip install jupyterlab ipykernel
jupyter lab –ip=0.0.0.0 –port=8888 –no-browser
# 更安全的方式:本地建立 SSH 隧道
# ssh -L 8888:127.0.0.1:8888 aiuser@服务器公网IP
| JupyterLab 不建议裸奔公网。优先使用 SSH 隧道、VPN、反向代理认证或仅监听 127.0.0.1。 |
十、第八步:部署 Ollama、Open WebUI、vLLM 等本地 AI 服务
1. Ollama:最快跑起来的本地模型服务
curl -fsSL https://ollama.com/install.sh | sh
sudo systemctl start ollama
sudo systemctl status ollama
ollama run deepseek-r1:8b
# 查看本地模型
ollama list
# API 测试
curl http://127.0.0.1:11434/api/generate -d ‘{“model”:”deepseek-r1:8b”,”prompt”:”用三句话介绍 Linux AI 环境”}’
2. Open WebUI:给 Ollama 加一个网页界面
docker run -d \
–name open-webui \
–restart always \
-p 8080:8080 \
-v open-webui:/app/backend/data \
ghcr.io/open-webui/open-webui:main
# 浏览器访问:http://服务器IP:8080
3. vLLM:高并发 OpenAI 兼容 API 服务
# 示例:Docker 方式运行 OpenAI 兼容服务,请根据模型和显存调整参数
docker run –runtime nvidia –gpus all \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-p 8000:8000 \
–ipc=host \
vllm/vllm-openai:latest \
–model Qwen/Qwen2.5-7B-Instruct
# API 测试
curl http://127.0.0.1:8000/v1/chat/completions \
-H “Content-Type: application/json” \
-d ‘{“model”:”Qwen/Qwen2.5-7B-Instruct”,”messages”:[{“role”:”user”,”content”:”你好”}]}’
4. 服务端口速查
| 服务 | 默认端口 | 用途 | 公网建议 |
| SSH | 22 | 远程登录 | 只对白名单开放,使用密钥 |
| Ollama | 11434 | 本地模型 API | 不要直接公网开放 |
| vLLM | 8000 | OpenAI 兼容 API | 加认证和反向代理 |
| Open WebUI | 8080 | 网页聊天界面 | 加 HTTPS 和账号 |
| JupyterLab | 8888 | Notebook | 优先 SSH 隧道 |
| n8n | 5678 | 自动化工作流 | 必须设置账号/HTTPS |

十一、常见问题排查
SSH 能 ping 通但连接不上怎么办?
先看云服务器安全组是否放行 22 端口,再检查服务器防火墙和 sshd 服务:sudo systemctl status ssh 或 sudo systemctl status sshd。密钥登录失败时,重点检查 ~/.ssh 权限、authorized_keys 内容、用户名是否正确。
pip 报 externally-managed-environment 怎么办?
这是新版本 Debian/Ubuntu 常见保护机制,表示不建议往系统 Python 里全局装包。正确做法是创建 venv、conda 或 uv 项目环境,再在环境内 pip install。
nvidia-smi 能看到 GPU,但 torch.cuda.is_available() 是 False 怎么办?
通常是 PyTorch 安装成 CPU 版,或 CUDA wheel 与环境不匹配。删除 torch 后,去 PyTorch 官网按 Linux + pip + CUDA 版本生成安装命令,重新安装。容器里还要确认 –gpus all 和 NVIDIA Container Toolkit。
Docker 容器内看不到 GPU 怎么办?
先在宿主机运行 nvidia-smi,确认驱动正常;再安装 NVIDIA Container Toolkit;最后运行 nvidia/cuda 镜像测试。不要一上来就怀疑模型或 PyTorch。
Ollama 在服务器上能跑,但本地浏览器打不开怎么办?
如果是 WebUI,检查端口映射、防火墙、安全组;如果是 Ollama API,默认更适合本机访问,不建议直接公网开放。可用 Nginx 反代并加认证,或通过 SSH 隧道访问。
模型下载到系统盘导致磁盘满了怎么办?
把模型缓存、Docker 数据卷、Hugging Face 缓存迁移到数据盘。例如配置 HF_HOME、OLLAMA_MODELS、Docker data-root,或者直接把 /var/lib/docker 放到大容量数据盘。
十二、FAQ
Q:Linux 新手应该选择 Ubuntu 还是 Rocky Linux?
A:建议先选 Ubuntu LTS。Ubuntu 在 AI 工具、NVIDIA 驱动、Docker、深度学习框架方面资料更多,适合入门;Rocky Linux 更适合企业运维标准化场景。
Q:没有 GPU 能不能部署 AI 工具?
A:可以。n8n、Dify、简单 RAG、轻量模型、Embedding、自动化脚本都能跑。只是大模型推理速度会慢,建议用较小模型或调用云端 API。
Q:CUDA Toolkit、cuDNN、PyTorch 的关系是什么?
A:NVIDIA 驱动负责让系统识别 GPU;CUDA Toolkit 提供开发和编译工具;cuDNN 是深度学习加速库;PyTorch/TensorFlow 是 AI 框架。多数普通推理场景先装驱动和框架即可。
Q:服务器上要不要安装桌面环境?
A:不建议。服务器优先用 SSH、VS Code Remote SSH、Docker 和 WebUI。桌面环境会占用资源,也增加维护复杂度。
Q:Docker 部署和源码部署选哪个?
A:新手和生产服务优先 Docker;需要开发插件、改源码、调试底层依赖时再考虑源码部署。
Q:Linux AI 环境搭好后如何备份?
A:至少备份项目代码、.env 配置、Docker Compose 文件、数据卷、模型目录、数据库数据。不要只备份容器镜像。
官方参考来源
- Python 官方下载页:https://www.python.org/downloads/
- Git 官方网站:https://git-scm.com/
- Visual Studio Code on Linux:https://code.visualstudio.com/docs/setup/linux
- VS Code Remote SSH 官方文档:https://code.visualstudio.com/docs/remote/ssh
- Ubuntu 26.04 LTS Release Notes:https://documentation.ubuntu.com/release-notes/26.04/
- Ubuntu 24.04 LTS Release Notes:https://documentation.ubuntu.com/release-notes/24.04/
- Ubuntu Server UFW 防火墙文档:https://ubuntu.com/server/docs/how-to/security/firewalls/
- Docker Engine on Ubuntu:https://docs.docker.com/engine/install/ubuntu/
- NVIDIA CUDA Toolkit Downloads:https://developer.nvidia.com/cuda-downloads
- NVIDIA Driver Installation Guide:https://docs.nvidia.com/datacenter/tesla/driver-installation-guide/index.html
- NVIDIA Container Toolkit Installation:https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html
- PyTorch Get Started Locally:https://pytorch.org/get-started/locally/
- TensorFlow pip installation:https://www.tensorflow.org/install/pip
- Miniconda Linux installer:https://www.anaconda.com/docs/getting-started/miniconda/install/linux-install
- uv 安装文档:https://docs.astral.sh/uv/getting-started/installation/
- JupyterLab 安装文档:https://jupyterlab.readthedocs.io/en/stable/getting_started/installation.html
- Ollama Linux 安装文档:https://docs.ollama.com/linux
- vLLM 安装文档:https://docs.vllm.ai/en/stable/getting_started/installation.html
环境配置与 Docker 工作流
适合阅读安装部署、本地配置、服务器搭建和自动化流程类文章后继续转化。
