

进阶:如何将 ChatGPT 接入飞书/钉钉,打造企业专属知识库
面向企业 FAQ、SOP、制度文档、项目知识的实战落地指南
更新日期:2026-04-08 · 适用对象:产品负责人 / IT 管理员 / 中小企业老板 / 内部工具开发者
| 先说结论: 如果你只是想把 ChatGPT 的能力“丢进群里”,自定义机器人 + Webhook 就够了;如果你想做真正可用的企业知识库,必须再补上检索层、权限标签、知识同步和答案引用。 |
一、为什么很多“企业 AI 机器人”上线后很快被弃用?
因为很多项目只做了“消息接入”,没有做“知识治理”。机器人能收到问题,不代表它知道该从哪里找答案;模型能写得像样,不代表它引用的是你们公司当前、正确、可授权访问的知识。真正可用的企业知识库,至少要同时满足四件事:
- 它知道去哪里找答案:飞书知识库、飞书文档、多维表格、钉钉文档、知识库、FAQ、SOP、会议纪要等。
- 它知道什么该被谁看到:同一份资料对不同部门和角色可见范围不同。
- 它知道答案必须可追溯:最好返回来源标题、更新时间和引用片段。
- 它知道自己不知道:检索不到或权限不足时,要明确拒答或转人工。
二、这篇文章会帮你搭出什么?
本文不是教你做一个“会聊天的机器人”,而是教你搭一个能在飞书或钉钉里稳定工作的企业知识问答系统。推荐落地结构如下:
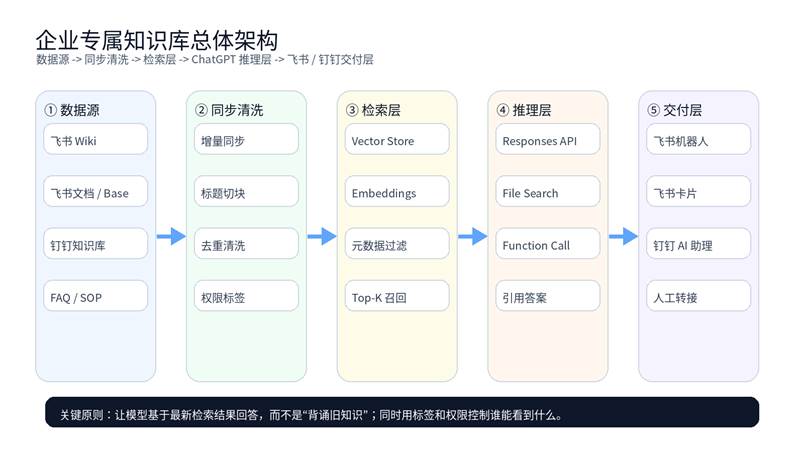
图 1:企业专属知识库的推荐架构
- 入口层:飞书应用机器人 / 消息卡片 / 钉钉机器人 / 钉钉 AI 助理。
- 知识层:飞书 Wiki、飞书云文档、多维表格、钉钉文档、钉钉知识库,以及企业内部 FAQ / SOP / PDF / Markdown。
- 检索层:OpenAI Vector Store + File Search,或自建 embeddings 检索层。
- 治理层:同步策略、权限标签、来源标记、人工兜底和日志审计。
三、先选路线:轻量版接入,还是知识库版接入?
| 方案 | 适用场景 | 开发难度 | 上线速度 | 答案可靠性 | 推荐阶段 |
| 轻量版 | 群消息问答、通知播报 | 低 | 快 | 弱 | MVP / 简单 FAQ |
| 知识库版 | 企业制度问答、SOP 检索、项目资料查询 | 中 | 中 | 强 | 部门工具 / 生产环境 |
| 建议: 中小企业最稳妥的做法,是先做一个“单场景知识库版”,例如 HR 制度问答或售前 FAQ。先把一个场景跑通,再逐步扩展。 |
四、OpenAI 这一侧怎么接?
到 2026 年,OpenAI 推荐的主接口已经是 Responses API。它可以接收文本与图像输入,也支持会话状态、函数调用,以及 file search 这类内置工具。对于企业知识库机器人,最常见的两条路线如下:
| 路线 | 核心能力 | 适合谁 | 优点 | 注意点 |
| 内置 File Search | 文件上传 -> Vector Store -> 检索 -> 回答 | 先求快上线的团队 | 少写很多检索基础设施 | 仍要做好元数据与更新策略 |
| 自建 Embeddings/RAG | 自己切块、向量化、召回、过滤、重排 | 有工程团队或隔离要求更高的团队 | 控制力更强,可统一多数据源 | 开发与运维成本更高 |
- Responses API 适合做“推理大脑”,负责把用户问题、检索结果和业务函数调用拼起来。
- Vector Store / File Search 适合做“知识底座”,用于存放企业文档并返回相关片段。
- Function Calling 适合连接审批、工单、CRM、组织架构、权限校验等外部系统。
五、飞书接入:推荐做法与关键节点
飞书这边,不建议只停留在“自定义机器人发消息”这一步。真正可用的企业知识库机器人,更推荐用“自建应用 + 机器人能力 + 事件订阅 + 云文档 / Wiki / 多维表格 API”来做。
- 消息入口:飞书应用机器人接收用户提问,群里可配合消息卡片完成追问、查看来源、转人工。
- 事件接入:通过事件订阅接收消息事件,后端再把问题转给 ChatGPT。
- 知识来源:优先接飞书知识库(Wiki)、云文档和多维表格,尤其适合制度、流程、FAQ、项目周报等。
| 飞书平台提醒: 截至 2026 年 4 月,基础免费版企业自建应用 API 调用总量已有较明确上限提醒。做企业知识库时,建议从少量高频场景起步,避免一上来就把所有同步与问答都压在免费额度上。 |
六、钉钉接入:机器人与 AI 助理怎么选?
| 形态 | 适合场景 | 优点 | 限制 / 注意点 |
| Webhook 机器人 | 单向推送、提醒、播报 | 接入简单 | 更适合通知,不够像完整问答入口 |
| 企业内部机器人 | 群聊问答、单聊问答 | 可收消息、可回消息 | 要处理回调、鉴权和消息协议 |
| AI 助理 | 知识问答、主动推送、智能交互 | 更贴近原生智能入口 | 需按官方 AI 助理能力设计 |
- 钉钉机器人可以接收消息、回复消息;如果你要做完整会话体验,AI 助理往往比纯 Webhook 更自然。
- 钉钉文档、表格和知识库都提供了官方开放能力,适合作为高质量知识源。
- 做企业知识库时,建议优先把答案引用、权限边界和人工兜底做好,再考虑更复杂的 Agent。
七、最关键的一层:知识库不是“文件堆”,而是“可检索、可授权、可更新”的数据层
| 治理维度 | 推荐做法 | 为什么重要 |
| 文档准入 | 只同步当前仍有效、有人维护的文档 | 减少过时答案 |
| 分段切块 | 按标题层级、段落或问答对切块 | 提升检索命中率 |
| 元数据 | 给每段内容打上部门、来源、更新时间、权限级别 | 支持过滤与权限控制 |
| 增量同步 | 记录上次同步时间,只更新变更文档 | 降低成本并保持新鲜度 |
| 答案引用 | 要求模型返回来源标题、更新时间、片段 | 让用户更敢用 |
| 兜底逻辑 | 无结果 / 低置信度 / 权限不足时明确说明或转人工 | 避免一本正经地胡说 |
八、推荐给中小企业的 5 步上线法
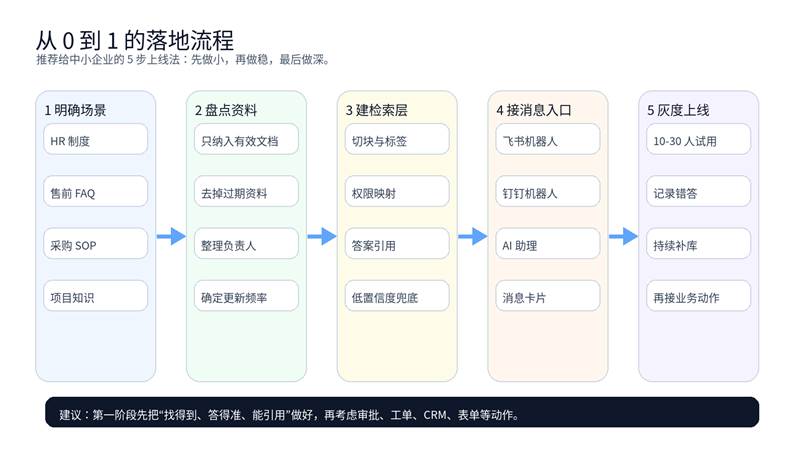
图 2:企业知识库项目的推荐上线节奏
- 先选一个价值高、答案边界清晰的场景,例如 HR 制度问答或售前 FAQ。
- 只纳入少量高质量资料,通常 10-30 篇文档就够做第一版。
- 先把“检索 + 引用”做好,暂时不要追求复杂工作流和自动执行。
- 让 10-30 个真实用户灰度测试,收集错答、漏答和越权问题。
- 稳定后再接审批、工单、CRM 或通知推送,让机器人从“会答”进化到“会办事”。
九、一个最小可用实现:消息回调 -> 检索 -> 回答 -> 回传
下面这段伪代码展示的是最小可用思路。具体用飞书还是钉钉,只会影响消息接收与回传部分;ChatGPT 检索问答的主流程其实是类似的。
| # 1) 接收飞书/钉钉回调消息 user_question = incoming_message.text user_id = incoming_message.user_id channel = incoming_message.channel # 2) 做权限映射:根据用户所属部门/角色生成过滤条件 filters = { “department”: query_user_department(user_id), “access_level”: query_user_clearance(user_id) } # 3) 调用 OpenAI Responses API,并挂上 file_search response = client.responses.create( model=”gpt-4.1″, input=user_question, tools=[{ “type”: “file_search”, “vector_store_ids”: [“vs_enterprise_kb”], “filters”: filters }] ) # 4) 提取答案与来源 answer = response.output_text citations = extract_sources(response) # 5) 回传到飞书或钉钉 send_message(channel, format_answer(answer, citations)) |
十、系统提示词怎么写,才更像企业知识助手?
企业知识库机器人最怕两件事:一是乱编;二是越权。因此系统提示词建议直接把行为边界写清楚。下面是一版可直接改造的模板:
| 你是企业内部知识助手。你的职责是: 1. 优先根据检索到的企业知识回答问题,不要凭空补全; 2. 如果检索结果不足,请明确说明“当前知识库未找到足够依据”; 3. 回答时优先给出结论,再给出处(文档标题/更新时间/片段); 4. 严格遵守权限边界,若用户无权访问相关内容,直接提示无法提供; 5. 对制度、财务、人事、法务类问题,禁止给出超出文档依据的确定性判断; 6. 当问题需要执行动作时,只能通过已授权的函数调用执行。 |
十一、最常见的 8 个坑
- 把历史所有文档一次性导入,导致过时信息和重复资料挤满检索结果。
- 只做了全文搜索,没有做元数据过滤,结果不同部门互相看见不该看的内容。
- 只返回“答案”,不返回“来源”,最后用户根本不敢信。
- 知识库长期不更新,结果机器人回答的是 3 个月前的制度。
- 没有灰度测试,直接全员开放,第一周就被错误答案劝退。
- 没有人工兜底,检索不到时机器人依然努力胡说。
- 只看模型效果,不看平台限额、消息频控、API 配额和权限申请周期。
- 把聊天工具本身直接当知识库,没有建立同步、过滤和版本机制。
十二、给不同团队的选型建议
- 没有开发团队:优先尝试飞书 / 钉钉原生 AI 能力,或者先找轻量集成服务,先验证需求再决定是否自建。
- 有 1-2 名前后端:自建机器人 + OpenAI Responses API + Vector Store 往往是投入最可控、落地也最快的方案。
- 已有内部数据平台:更推荐自建检索层,把 OpenAI 放在模型层,把飞书 / 钉钉作为机器人入口与交付层。
- 对安全和合规要求高:优先把权限边界、保留策略和日志审计设计清楚,再决定是 API 方案还是更完整的企业级方案。
十三、FAQ
1. 直接把 ChatGPT 接进飞书/钉钉,就等于企业知识库了吗?
不等于。那只是消息入口。真正的企业知识库还需要知识同步、检索、权限和引用机制。
2. 飞书和钉钉,哪个更适合先做?
先做文档与知识资产沉淀更多的一侧,不要为了“技术统一”违背内容沉淀的位置。
3. 一上来就要做复杂 Agent 吗?
不建议。第一阶段先把“找得到、答得准、能引用”做好,比堆复杂工作流更重要。
十四、相关阅读
工具选型与提示词资料
适合阅读工具评测、工具推荐、对比测评类文章后继续转化。
