
团队 AI 资产库怎么做检索质量评估与持续优化
| 先看结论 • 测试集不要按关键词拍脑袋编,而要从真实任务、真实提问和真实失败案例里抽样。只有这样,评估结果才接近团队日常使用场景。 • 持续优化不能每次乱改一堆参数。更稳的做法是:先回放基线,再只改一个主要变量,最后复测确认,形成周跟踪、月复盘、季清理的节奏。 |
一、为什么“能搜到”不等于“搜得准”
很多团队觉得,资产库里已经有提示词、模板、知识卡片和 FAQ,搜索框也能返回结果,所以“检索”这件事已经完成。真正上线后才发现,成员还是会反复问同样的问题,或者绕回临时聊天窗口重来。
原因通常不在“有没有内容”,而在“首屏结果是不是刚好能用”。用户在办公场景里容忍度很低:如果前两三次都找不到正确资产,系统再完整也会被判定为难用。
因此,检索质量评估的目标,不是证明库里有很多条目,而是持续回答三个问题:第一,用户常见查询是否能命中正确资产;第二,命中后生成结果是否可信、可引用、可交付;第三,系统有没有随着内容增长而变得更难搜。
二、先把检索质量指标定清楚
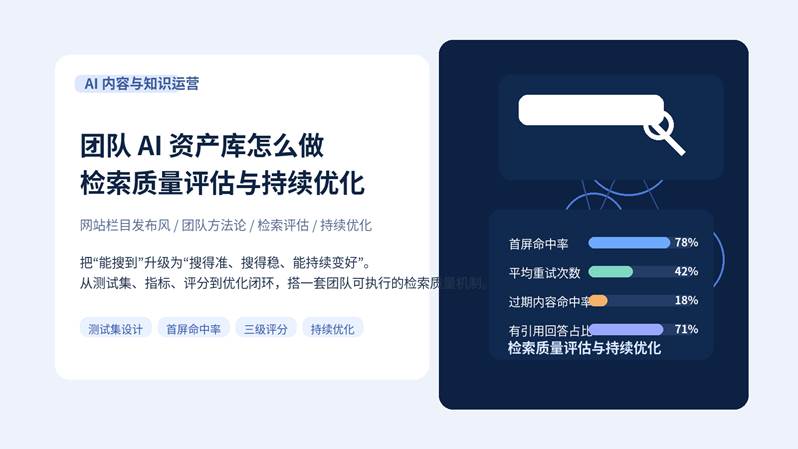
建议至少保留 5 个核心指标:
• 首屏命中率:用户第一次搜索时,Top1 或 Top3 是否出现正确资产。
• 任务完成率:用户是否在本轮检索后完成周报、纪要、回复、答疑等实际任务。
• 平均重试次数:一次任务平均要改写几次查询,才能找到可用结果。
• 有引用回答占比:系统生成内容里,是否明确带出来源条目、版本或引用片段。
• 过期内容命中率:结果里是否经常冒出旧模板、失效制度或已淘汰资产。
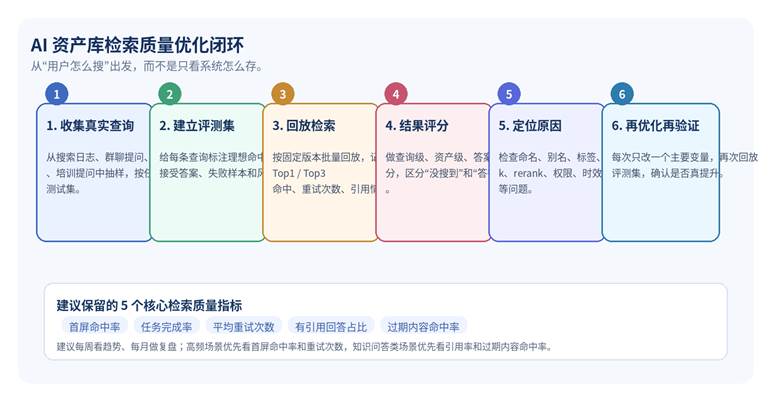
图 1 团队 AI 资产库的检索质量优化闭环
三、测试集怎么建,评估结果才接近真实使用
测试集设计最容易犯的错,是由平台 owner 凭经验随手列几十个关键词。这样做出来的评测,很容易高估系统表现,因为它更像“系统视角”的搜索,而不是“业务视角”的真实提问。
更稳妥的方法,是从真实使用链路抽样:搜索日志、群聊里反复出现的问题、工单标题、培训现场提问、会议纪要里的行动项,都是很好的来源。抽样时尽量覆盖高频、长尾、模糊表述、跨部门术语、权限受限和失败重试场景。
每条测试样本至少要补齐四项信息:用户原始提问、理想命中资产、可接受答案边界、失败风险点。这样一来,后续就能区分“完全没搜到”“搜到了但排序不对”“答案能写出来但引用不稳”这几类问题。
| 样本类型 | 示例查询 | 主要检验点 |
| 高频刚需 | “周报怎么写”“会议纪要模板” | 检验首屏命中率与模板导航 |
| 模糊问法 | “帮我写个活动总结”“售后回复怎么更稳” | 检验别名、标签与 query rewrite |
| 复杂问题 | “远程员工 2024 年后 PTO 政策怎么执行” | 检验多条件检索与引用质量 |
| 权限场景 | “财务预算审批口径” | 检验权限裁剪和结果可信度 |
| 失败回放 | 历史上用户重试 2 次以上的查询 | 检验优化是否真正解决老问题 |
表 1 建议按真实任务组织测试集,而不是只按关键词组织。
四、评分最好拆成三级:查询级、资产级、答案级
要让评估结果真正能指导优化,建议把评分拆成三级:查询级、资产级、答案级。这样才能知道问题到底出在“搜的逻辑”“资产本身”还是“生成答案”。
查询级关注搜得准不准,常用指标是 Top1 / Top3 命中、平均重试次数、召回缺口。资产级关注条目好不好用,常看采用率、编辑成本、更新时间、是否有清晰别名和元数据。答案级关注生成是否可信,重点看引用率、事实错误率、任务完成率、格式可交付性。
如果这三层不拆开看,团队很容易把所有问题都归咎于模型能力,结果反而错过真正更容易改的地方,例如标题命名、标签补齐、chunk 拆分、排序权重和过期清理。
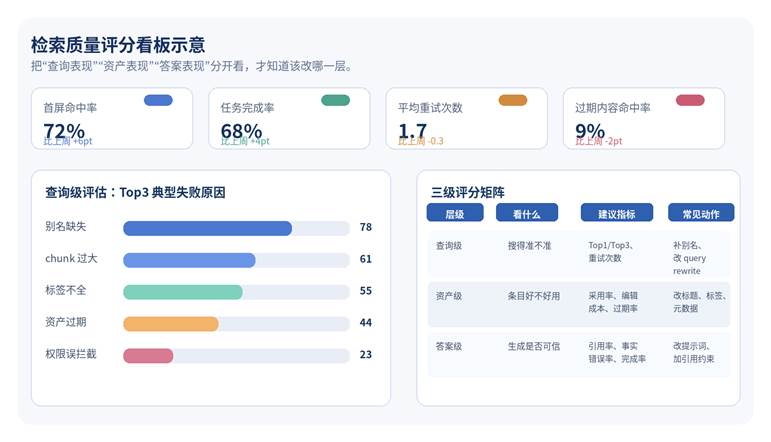
图 2 检索质量评分看板示意
| 层级 | 核心指标 | 高优先级动作 |
| 查询级 | Top1/Top3、平均重试次数 | 补别名、改 query rewrite、加同义词 |
| 资产级 | 采用率、编辑成本、过期率 | 重写标题、补标签、补场景说明 |
| 答案级 | 引用率、事实错误率、完成率 | 改提示词、加引用约束、收紧输出格式 |
五、持续优化要优先改哪些地方
持续优化不要每次同时改 5 件事。建议遵循“一个主要变量 + 一轮回放”的节奏,这样才能判断提升到底来自哪里。
第一类高杠杆动作,是改资产元数据。包括:标题是否贴近任务语言、是否补了常见别名、是否声明适用部门与输入材料、是否写清输出格式和责任边界。这类修改成本低,但往往能显著提高命中率。
第二类动作,是改内容切分与排序逻辑。长文档要避免 chunk 过大;核心段落要允许被独立命中;高频模板与制度类内容可以适当加权;结果页尽量优先展示最新版本和带明确责任人的条目。
第三类动作,是把用户反馈回流进资产库。比如记录“本次答案是否可直接发送”“是否还需要人工重写”“用户最终点开了哪个条目”“哪类查询重试次数最高”。这些都是下一轮优化最有价值的线索。
六、一套可直接执行的复盘节奏
• 周节奏:看核心指标趋势,尤其是首屏命中率、平均重试次数和过期内容命中率;挑出波动最大的 10 条查询做回放。
• 月节奏:做一次专题复盘,把失败样本按“命名问题、元数据问题、排序问题、权限问题、答案问题”归类,确定下月只攻一到两类问题。
• 季节奏:清理长期低采用、长期无人维护或已被新版替代的资产,同时刷新测试集,确保评测样本跟着业务变化走。
FAQ
Q1:检索质量一定要做到很复杂的算法评估吗?
不一定。团队起步阶段先把真实测试集、首屏命中率、平均重试次数和引用情况跑起来,就已经比“凭感觉说好用”强很多。
Q2:为什么我明明搜到了正确文档,用户还是说不好用?
因为“搜到”不等于“能交付”。很多时候问题出在排序靠后、引用不清、输出格式不适合直接发,或者结果命中了过期版本。
Q3:每次优化后,指标短期波动正常吗?
正常。关键是要保留基线版本,并一次只改一个主要变量。这样即使指标波动,也能快速定位原因。
Q4:测试集多久更新一次比较合适?
高频业务建议每月补样本,至少每季度刷新一次。只用老样本做评测,很容易把系统优化到“考试题”上,而不是优化到真实业务里。
Q5:内链要怎么放,才更像网站栏目文章?
优先在正文相关段落和文末相关阅读中使用自然锚文本,不要把内链孤零零塞进表格。链接要让读者知道点进去会看到什么。
相关阅读
• 《团队用 AI 写周报、纪要、方案时,怎么做模板、版本和责任边界》
结语
团队 AI 资产库的成熟度,不取决于条目数量,而取决于它能否持续帮助成员“少试错、快命中、能交付”。当你把真实查询、明确指标、三级评分和月度复盘串成一个闭环,资产库才会从静态仓库变成真正会变好的工作系统。
资料口径参考
以下链接用于整理方法论口径,适合作为编辑或复盘参考。
• OpenAI Prompt engineering best practices
• OpenAI Prompt management in Playground
• Anthropic Define success criteria and build evaluations
• Vertex AI Gen AI evaluation service overview
• Azure AI Search RAG overview
• Azure AI Search hybrid search scoring
