

团队知识库接入 AI 之后,怎么做权限、检索和沉淀
一篇讲清接入边界、检索策略与知识沉淀机制的团队落地指南
AI工具库 / 保姆级教程 / 实战工作流
先看结论
团队知识库一旦接入 AI,真正难的从来不是“能不能连上”,而是三件事:谁能看、搜出来靠不靠谱、好答案能不能沉淀成组织资产。很多团队把 AI 当成一个更聪明的搜索框,结果一上线就遇到权限穿透、旧文档误导、答案说得像真但找不到出处。
• 第一步不是全库接入,而是先分层:制度库、项目库、会议纪要、FAQ、敏感资料要分别处理。
• 权限不要另起一套,优先继承原有文档系统的授权,再用群组和空间做二次控制。
• 检索不要只追求“搜得全”,还要做时间衰减、空间过滤、来源引用和失败回退。
• 沉淀不要靠人工自觉,最好把高频问答、会议结论、项目复盘直接回写成 FAQ、SOP 和模板。
• 上线顺序建议是:先制度和 FAQ,再项目协作,再跨库深度研究;敏感库永远最后进场。
| 一句话判断这篇适不适合你 如果你的团队已经在用 ChatGPT、Claude、Gemini、Copilot 或类似工具去查 Drive、SharePoint、Slack、邮件和会议纪要,但对权限、检索质量和知识沉淀还没有一套明确规则,这篇就是给你写的。 |
为什么团队把知识库接入 AI 后,反而更容易出问题
因为“会回答”不等于“回答正确”,更不等于“回答合规”。传统知识库的问题通常是不好找;接入 AI 之后,问题会升级成:找到了不该看到的内容、引用了过期材料、把草稿当定稿、把单次问答变成不可追溯的黑箱。
| 常见问题 | 表面症状 | 根本原因 |
| 权限穿透 | AI 能看到本不该开放的库或附件 | 把“接入能力”误当成“访问授权”,缺少管理员边界与群组控制 |
| 答案失真 | 回答像是真的,但引用的是旧版本文档 | 没有时间权重、版本标记和过期清理 |
| 知识黑洞 | 每次都重新问,答案没办法复用 | 没有把高频问答回写成 FAQ / SOP / 模板 |
| 责任模糊 | 团队不知道谁该维护知识质量 | 没有设库负责人、栏目负责人和失效规则 |
四层框架:先治理源和权限,再谈检索与沉淀
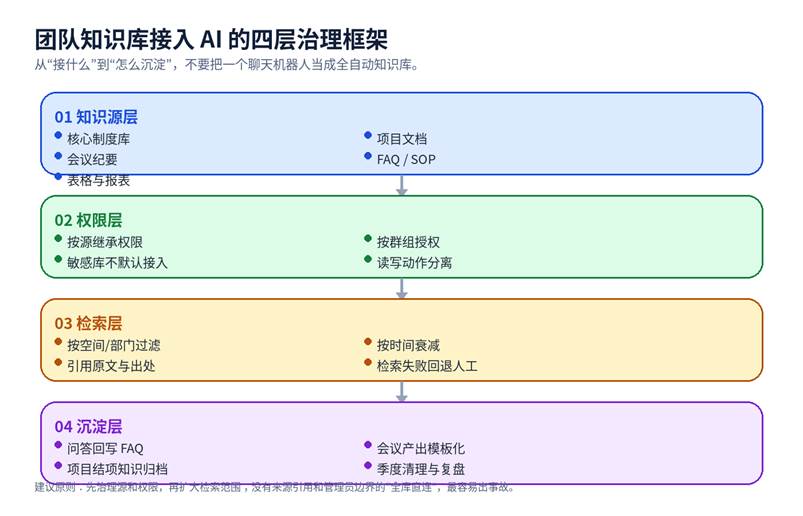
更稳妥的落地方式,是把团队知识库看成四层系统:知识源层、权限层、检索层、沉淀层。每一层都要有明确的边界,而不是把所有文件一股脑接进来,然后期待 AI 自动解决历史积累的问题。
第一层:知识源怎么接
建议先按“内容成熟度”和“敏感度”做接入分批,而不是按工具品牌来分。能稳定提供答案的,应优先接入;频繁变动、审批未完成或涉及敏感信息的,要么晚接,要么只做限定范围访问。
| 知识类型 | 建议接入节奏 | 适合回答的问题 | 注意事项 |
| 制度 / 规范 / 员工手册 | 第一批 | 标准流程、权限说明、入职培训 | 必须标明版本与发布日期 |
| FAQ / SOP / 模板库 | 第一批 | 高频操作、常见问答、交付模板 | 优先做标准问法与标准答案 |
| 项目文档 / PRD / 周报 | 第二批 | 项目背景、里程碑、历史决策 | 按项目空间过滤,避免跨组串读 |
| 会议纪要 / 访谈记录 | 第二批 | 待办、结论、责任人 | 要区分“讨论意见”和“最终决议” |
| 财务 / 法务 / 人事敏感文件 | 最后一批或不直连 | 仅限授权场景 | 建议最小化暴露,必要时只开放摘要层 |
| 接入顺序建议 多数团队最安全的顺序是:制度库 → FAQ / SOP → 项目库 → 会议纪要 → 跨库研究 → 敏感库。这样一来,AI 先学会回答“标准题”,再逐步处理复杂问题。 |
第二层:权限怎么做,才不会一连就漏
权限治理的原则很简单:AI 不能比原系统看得更多;能搜索,不代表能写回;默认能用,不代表默认能跨部门。实际操作时,可以用“继承原权限 + 群组二次控制 + 敏感库白名单 + 读写分离”这四步来定边界。
• 继承原权限:优先沿用 Drive、SharePoint、Confluence、Notion 等现有文档系统的授权,不另外造一套影子权限。
• 群组二次控制:按部门、项目组、职能组来划定可检索范围,避免“默认全员全库可搜”。
• 敏感库白名单:法务、人事、财务、客户合同、未披露经营数据,最好由管理员单独放行。
• 读写分离:先开放读取和引用,再决定是否允许写回、创建文档、修改表格或发起外部动作。
这类做法与当前主流产品的企业能力方向是一致的:ChatGPT 的企业级 apps / company knowledge 支持管理员控制 app 可用性、RBAC,以及对 connector 动作做管理;Claude 的团队与企业方案提供角色权限和连接器;Gemini 的工作/学校账号功能与数据处理取决于 Workspace 许可与管理员设置;微软体系则强调沿用 OneDrive / SharePoint 的原有共享权限与库级权限管理。
第三层:检索怎么做,答案才更稳
很多团队一开始只在意“能不能搜到”,结果回答看起来顺,实际却不稳。要提高可靠性,至少要加四个约束:范围过滤、时间权重、出处引用、失败回退。
• 范围过滤:先限定部门、项目、空间、站点,再检索全文,能明显减少无关内容干扰。
• 时间权重:制度类文档看最新版本,项目类文档更看近期纪要和最近一次决策。
• 出处引用:答案里要尽量带原文链接、文档名、时间戳、段落或附件来源。
• 失败回退:当检索结果冲突、证据不足或命中为空时,应该明确提示“不确定”,而不是编一个像样答案。
| 检索提示词模板 请只基于已授权资料回答;先检索本项目空间,再看制度库;优先使用最近 90 天更新的资料;如果证据不足,请直接说明并给出需要补充的资料名称。 |
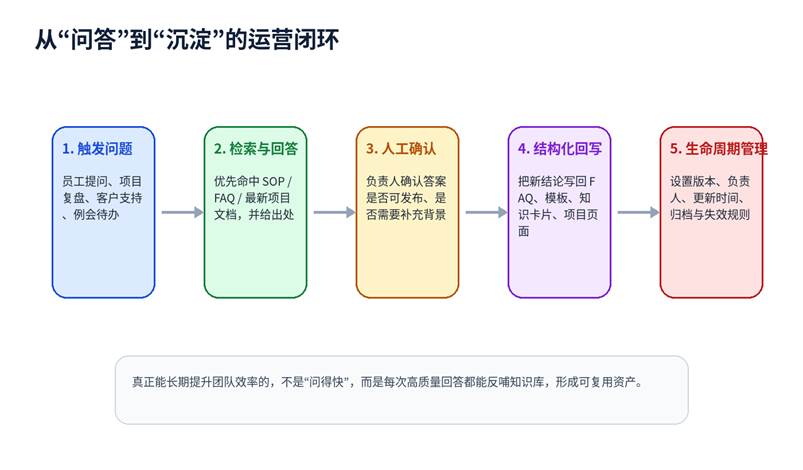
第四层:沉淀怎么做,团队才不会一直重复问
很多团队接入 AI 后的最大浪费,是把大量高价值问答留在聊天框里,既不能复用,也没人维护。更好的办法是:把“问答”视为知识生产入口,把“回写”作为默认动作。
| 来源场景 | 建议沉淀物 | 责任角色 |
| 高频提问 | FAQ 卡片 / 内部答疑页 | 知识库管理员 / 业务 owner |
| 会议结论 | 决策记录 / 待办模板 / 复盘页 | 会议 owner |
| 项目执行经验 | SOP / 清单 / 项目模板 | 项目经理 / 交付负责人 |
| 错误案例 | 踩坑库 / 风险清单 / 审核规则 | 职能负责人 |
真正成熟的做法,不是让每个人都更会提问,而是让每次高质量回答都能回写成团队资产:FAQ 可以解决高频问题,SOP 可以降低执行偏差,模板可以减少重复劳动,项目结项页可以防止经验散失。
三套可直接照搬的落地方案
• 小团队版(10–30 人):先接制度、FAQ、项目文档;用一个统一空间做知识入口;每周人工回写一次 FAQ。
• 协作团队版(30–200 人):按部门和项目组分空间;统一模板;引入引用规则、更新时间字段和季度清理机制。
• 合规敏感版(金融、法务、医疗、B2B 交付等):敏感库白名单、审计日志、读写分离、审批后回写;不建议默认开放跨库深搜。
| 落地顺序 先做“能回答标准题”,再做“能回答项目题”,最后做“跨库综合研究”。一开始就追求全能,会把权限、质量和维护成本一起拉满。 |
FAQ
Q:团队知识库接入 AI,第一步应该做什么?
A:先盘点知识源,把内容按成熟度和敏感度分层,再决定第一批接入哪些库,而不是先选一个最强模型。
Q:要不要把 Slack、邮件、会议纪要都接进来?
A:可以,但不建议一开始全开。聊天和纪要信息噪音更高,最好先让制度库和 FAQ 稳定,再逐步接入。
Q:权限应该在 AI 里重新做一套吗?
A:一般不建议。更稳妥的是沿用原系统权限,再结合群组、项目空间和白名单做二次控制。
Q:检索答得不准,是模型问题还是知识库问题?
A:通常两者都有,但多数时候先要排查知识源质量、版本标记、更新时间和检索范围,而不是一味换模型。
Q:如何让团队真的把知识沉淀下来?
A:把回写动作嵌进流程里:高频问答回写 FAQ,会议结论回写决策页,项目复盘回写 SOP 和模板。
更多阅读
办公场景下的大模型怎么搭配
团队协作里,AI 怎么分工才不内耗
国内外主流大模型对比指南
AI 写作工具对比:谁更适合写公众号和小红书
参考口径说明
本文口径参考截至 2026-04-01 可公开查看的 OpenAI、Anthropic、Google 与 Microsoft 官方帮助中心资料。不同套餐、地区和管理员设置会影响实际可用功能。
