

团队 AI 资产库怎么做权限分层、访问控制和安全审查
定位:团队治理 / AI 资产库 / 权限分层 / 访问控制 / 安全审查
| 这篇文章适合:正在搭团队 AI 资产库、提示词库、模板库、知识源库,且需要同时兼顾协作效率与数据安全的团队。 |
导读
很多团队把 AI 资产库理解成“把提示词、模板、知识源丢到一起”,结果越做越乱:该共享的找不到,不该开放的被误用,离岗成员权限没回收,敏感资产和通用资产混在一起,最后谁都不敢放心复用。
真正可持续的做法,不是追求一个看起来很大的总库,而是先把资产分层、访问控制和安全审查搭起来。这样团队才知道:什么内容可以全员复用,什么内容只能项目组用,什么内容必须走审批,什么内容根本不能进开放式 AI 场景。
这篇文章按“网站栏目发布风 + 团队治理实战”来写,给你一套可直接落地的框架:先分四层权限,再把查看、编辑、分享、导出、连接器、日志和复核全部接上。

图 1|团队 AI 资产库权限与安全治理闭环
一、先看结论:先分层,再开放
先把结论说清楚:团队 AI 资产库最稳的治理方式,不是“一刀切全开”或“一刀切全关”,而是做四层管理——公开可复用、团队可编辑、敏感受限、高风险隔离。
每一层都要分别定义六件事:谁能看、谁能用、谁能改、谁能分享、谁能导出、谁来审。只要这六件事没写清楚,后面无论你用 ChatGPT、Claude、Gemini、Kimi 还是自建平台,最后都会在权限上返工。
落地顺序也别反了。先登记资产、标记敏感级别、绑定责任人;再做群组和角色授权;然后补审批、日志、复核;最后再谈更复杂的自动化和评分体系。
二、为什么很多团队一接 AI 资产库就会失控
团队最常见的误区,是把“会生成内容”误当成“已经可治理”。模型确实能帮你写文档、做总结、读知识库,但它不天然等于合规。真正的风险往往来自资产边界和权限边界,而不是回答本身。
比如一个项目提示词最初只是写周报,后来被塞进客户背景、报价逻辑和内部审批口径;一个共享知识源本来只给市场团队看,结果被复制到全员可访问空间;一个连接器为了方便调试临时开了写权限,过了三个月还没人关。
这些问题有个共同点:资产没有分层、权限没有跟角色、审批没有门槛、日志没有回看、复核没有节奏。你会发现,所谓“AI 资产失控”,本质上还是组织治理问题。
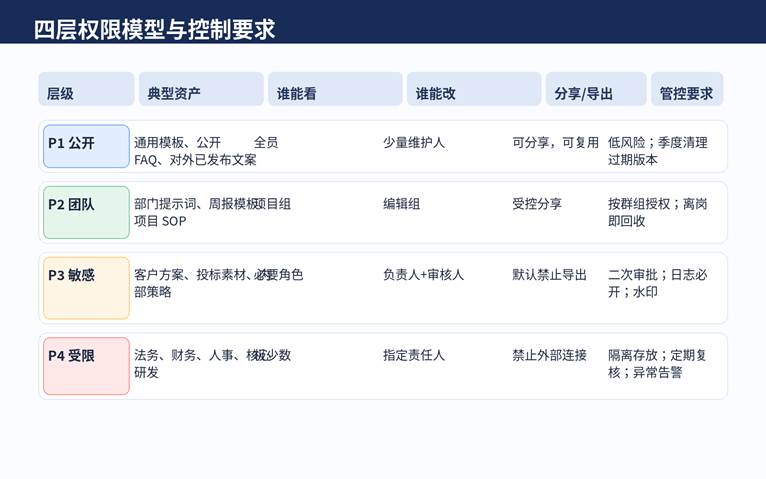
图 2|四层权限模型与控制要求
三、四层权限模型,为什么比“一把梭全开放”更稳
真正实用的 AI 资产库,一定不是一个完全扁平的目录,而是一个按风险等级分层的结构。最推荐的做法,是把资产拆成四层:P1 公开可复用、P2 团队可编辑、P3 敏感受限、P4 高风险隔离。
P1 放通用模板、通用提示词、公开 FAQ、对外已发布过的文案和标准作业示例。这层的目标不是保密,而是提高复用率,所以可以更强调搜索、标签和版本更新。
P2 放项目组、部门或专题团队共用的资产,例如行业专题模板、周报框架、会议纪要提示词、分析 SOP。它不适合全员裸开,但可以在明确群组边界后稳定复用。
P3 和 P4 才是最容易出事故的部分。前者通常是客户方案、价格口径、法务模板、内部策略、可触发外部动作的操作脚本;后者则是法务、人事、财务、核心研发等需要隔离的高风险资产。对这两层,默认禁止外部分享和自由导出,才是更稳的起点。
建议至少写清的六个权限动作
| 权限动作 | 不要只写什么 | 建议写到什么粒度 |
| 查看 | 能不能访问 | 能看哪些目录、哪些字段、哪些历史版本 |
| 使用 | 能不能调用 | 能否在聊天、项目、模板调用;能否作为知识源引用 |
| 编辑 | 能不能改 | 能否改正文、提示词、标签、版本说明 |
| 分享 | 能不能转发 | 能否分享给同组、跨组、外部协作者 |
| 导出 | 能不能下载 | 能否导出文档、复制提示词、截图、写回第三方 |
| 连接 | 能不能接外部系统 | 能否调用邮箱、网盘、工单、CRM、代码仓库 |
四、访问控制怎么落地:别只做“能不能进”,要做“进来后能做什么”
访问控制最重要的一条,是权限跟角色走,不跟个人走。不要直接把“可编辑”“可分享”“可导出”发给单个成员,而是先定义角色,例如:资产所有者、编辑者、使用者、审核人、审计人。
第二条,是把权限拆开。很多团队只区分“能不能访问”,但真正会出风险的,常常是“能访问且能复制、能查看且能导出、能使用且能改写、能调用且能外连”。所以查看、编辑、分享、导出、外部连接、写回动作必须分开控。
第三条,是给高风险权限加时间。比如项目临时协作者可以拿到 14 天访问权,投标阶段的方案组可以拿到 30 天编辑权,到期自动回收。静态长期授权,几乎一定会越积越乱。
• 按部门、项目、岗位建立授权群组,避免个人散点授权。
• 把“查看 / 使用 / 编辑 / 分享 / 导出 / 外连”拆成独立权限,不默认捆绑。
• 高风险资产默认关闭公开链接、复制下载和写回动作,需要审批后再开。
• 临时权限必须有到期时间;成员转岗、离岗、项目结束自动回收。
• 连接器或外部知识源默认只给读取最小范围,写权限单独申请。
| 平台侧也越来越强调管理员控制。例如 OpenAI 的 Projects 说明里提到,项目沿用标准聊天的加密、访问控制和审计日志,管理员还能控制项目共享;Claude 支持按角色管理组织权限,私有项目可设置 Can view / Can edit;Google Workspace 管理员可控制 Gem sharing、conversation sharing 和 Gemini 服务开关;Microsoft 则把 Copilot / AI 应用活动纳入审计与 Purview 治理。 |
五、安全审查怎么做:用“入库前 + 运行中 + 周期复核”三段式
安全审查不是在上线前做一次表格签字,而是一个持续机制。任何新资产进入库里前,都至少要回答五个问题:它来自哪里、里面有什么、谁会用、最坏会泄露什么、出了问题怎么追。
真正值得审的,不只是正文内容,还包括隐藏在资产里的上下文。例如提示词中的客户名单、样例中的真实数据、连接器默认能读到的网盘目录、模型输出是否允许写回原系统、用户是否能一键导出。
你会发现,一个成熟团队的安全审查,不是把大家都卡住,而是把高风险动作显式化。只要能把审批、留痕和责任边界设计清楚,很多协作效率并不会下降,反而会更稳。
安全审查清单(建议直接照搬进流程)
| 审查项 | 要看什么 | 通过标准 |
| 资产来源 | 是否来自可信文档、已脱敏样例、受控知识源 | 来源可追溯,禁止不明来源粘贴入库 |
| 敏感级别 | 是否含客户名、价格、合同、账号、真实个人信息 | 完成分级并绑定默认权限策略 |
| 角色边界 | 谁拥有、谁可编辑、谁可审核、谁仅可用 | 角色清楚,最小权限,不用个人散点授权 |
| 分享与导出 | 是否能复制、下载、外发、分享链接 | 默认收紧,例外通过审批开通 |
| 连接器动作 | 是否读写邮件、网盘、CRM、代码仓库 | 读写分离,写权限单独审批 |
| 日志与复核 | 是否能查谁访问、谁修改、谁导出 | 有审计记录,有月度巡检和季度复核 |
六、最容易被忽略的四个风险点
1. 分享链接比正文更危险
很多团队把正文审得很细,却忽略了“任何知道链接的人都能看”的共享方式。高风险层资产最好禁用公开链接,至少要限制组织内可见并绑定到期时间。
2. 测试数据往往没有真的脱敏
演示样例、培训样例、历史导出文件,常常是最容易被带进 AI 资产库的真实数据碎片。只要样例会被多人复用,就应该按正式数据处理。
3. 连接器默认范围过大
如果云盘、邮箱、工单或代码仓库的接入范围太宽,模型虽然未必越权,但用户能借助手头权限看到过多信息,结果就是“技术上没越权,业务上已过度暴露”。
4. 旧资产没人认领
最危险的资产不是正在高频使用的内容,而是已经过期、没人维护、但还挂着访问入口的旧模板和旧提示词。它们最容易被误用,也最容易遗忘。
七、建议的 7 / 30 / 90 天落地路线
如果你是第一次搭这套机制,别想着一次做成大而全。先用 7 天把资产台账、敏感级别和责任人拉起来;30 天内把群组授权、到期回收、分享开关和导出规则补齐;90 天内再接日志看板、异常告警和季度复核。
对大多数团队来说,最先该解决的并不是“模型选哪个”,而是“谁可以把什么东西放进库里,谁可以把什么东西拿出去”。这个顺序一旦理顺,后面的资产复用率和检索质量才有提升空间。
| 阶段 | 建议动作 |
| 7 天 | 列出全部 AI 资产;补齐责任人、用途、敏感级别;冻结没人认领的高风险内容。 |
| 30 天 | 完成群组授权、到期回收、分享开关、导出规则、连接器审批。 |
| 90 天 | 接入日志看板、异常告警、季度复核、淘汰机制和培训规则。 |
FAQ
团队 AI 资产库一定要单独建库吗?
不一定。起步阶段可以先在现有知识库、文档平台或 AI 项目空间里做一层“资产登记+权限标签+责任人”治理;当资产量、使用人数和审计要求上来后,再拆成独立资产库。关键不是先上多复杂的系统,而是先把分层、审批、留痕做起来。
为什么不建议直接按个人分配权限?
因为个人权限最容易失控。人员一多,离岗、转岗、项目切换都会造成“旧权限没回收,新权限又叠加”。更稳的办法是按角色、群组和项目来授权,权限跟角色走,不跟个人走。
AI 提示词也算敏感资产吗?
要看内容。通用写作提示词通常风险不高,但如果提示词里写入了客户信息、价格策略、法务口径、审批逻辑、内部流程或可触发外部动作的操作指令,就应该进入敏感或受限层。
连接器和外部知识源要不要单独审?
要。连接器决定 AI 能读什么、能不能写回、能不能跨系统带数据。任何能触达邮件、云盘、代码仓库、工单系统的连接器,都应该单独做权限评估、数据范围评估和异常审计设计。
安全审查最容易漏掉什么?
最常见的漏项不是模型本身,而是分享链接、导出权限、测试环境数据、外部协作者、过期成员、默认保留策略和没人维护的旧资产。很多风险都出在“方便先开着”,而不是“系统没有能力”。
更多阅读
| 一句话总结:AI 资产库真正要管的,不只是“内容”,而是内容背后的权限、动作、责任和可追溯性。只要把这四件事先定住,团队复用率和安全感都会一起上来。 |
上线前自检清单
□ 是否已经给每类资产定义了默认权限层级,而不是靠临时口头约定?
□ 是否把分享、导出、复制、写回、连接器调用拆成了不同权限?
□ 是否为敏感和受限资产绑定了责任人、审核人和复核周期?
□ 是否明确了临时协作者权限的到期时间和离岗回收机制?
□ 是否能在事后查到谁访问、谁修改、谁导出、谁审批过?
口径说明
本文适合做团队治理框架和流程设计参考,不替代你所在行业、地区或企业内部的正式安全制度。涉及监管、合同、个人信息和商业秘密时,应以本单位的法务、信息安全和管理员规则为准。
如果你所在团队已经在用带管理员控制、日志导出、连接器开关和共享权限的平台,优先把这些现成功能接进资产治理流程;没有现成平台时,也可以先用“资产台账 + 群组授权 + 审批记录 + 季度复核”起步。
