

分类:实战工作流 / 自动化工作流
适用场景:财务、销售、采购、运营、质检、数据治理
利用 Python + AI 接口,自动化处理 1000 份 Excel 报表的避坑指南
把“读表 + 调接口”的脚本升级为可复跑、可追踪、可复核的自动化流水线
| 内容定位 | 推荐分类 | 核心结论 |
| 实战型长文教程 | 实战工作流 > 自动化工作流 | 规则先行,AI 补位;结构化输出;断点续跑;人工复核 |
| 文章摘要 本文围绕“利用 Python + AI 接口自动化处理 1000 份 Excel 报表”这一主题,系统拆解大批量 Excel 自动化中的常见问题与应对方案,覆盖读取策略、字段清洗、AI 结构化输出、异常重试、断点续跑、结果回写与人工复核,适合需要搭建 Excel 自动化工作流的团队参考。 |
很多人第一次做 Excel 自动化,会把问题理解成“写个脚本把 1000 份报表全部跑完”。真正落地之后才发现,项目最容易翻车的地方,往往不在 Python 能不能读表,也不在 AI 能不能回答,而在于链路是否稳定:文件格式乱不乱、字段是否统一、结果能不能校验、任务中断后能不能继续、低置信度结果有没有人兜底。
因此,更靠谱的思路不是追求一个“万能脚本”,而是把整个任务拆成多个职责明确的层:读取、清洗、判断、校验、回写和复核。只有把这条流水线设计清楚,1000 份 Excel 的批处理项目才会从“演示可跑”变成“长期敢用”。

图 1 推荐流水线:把读取、清洗、AI 判断和写出结果拆成稳定的七步。
一、为什么 1000 份 Excel 不是“再多跑几次”那么简单
在 10 份 Excel 的规模下,很多问题不会暴露:字段乱一点还能手动改,AI 多说两句也能人工看懂,任务中断后重跑一遍就行。可一旦数量提升到 1000 份,原本被忽略的小问题会被无限放大。读取速度慢、内存占用高、sheet 命名不规范、金额列混入字符、表头别名不统一,这些都会在批量场景里叠加成系统性风险。
更重要的是,Excel 并不是标准数据库。它可能包含合并单元格、隐藏列、公式、手工注释、临时统计列,甚至有人把扫描图塞进表格里。也就是说,真正的难点不是“把文件打开”,而是把这些非标准输入收束成机器可处理的干净结构。
| 一句话判断项目成熟度 如果你的方案只能在干净样本上跑通,而一遇到异常表格就需要人工全程救火,那么它还不算一个成熟的自动化工作流。 |
二、推荐的系统拆法:先分层,再自动化
更稳妥的做法,是先把任务拆成五层:文件读取层、清洗标准化层、AI 判断层、校验复核层、结果写出层。这样做的好处是,每一层都只做自己最擅长的事情,出问题时也能快速定位。
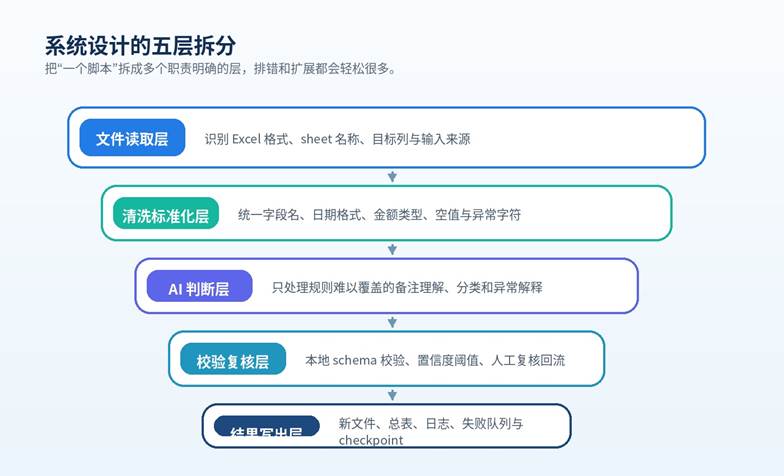
图 2 五层拆分:职责越清晰,系统越容易排错、替换和扩展。
- 文件读取层:只负责识别格式、sheet 与目标列,不掺杂业务判断。
- 清洗标准化层:统一表头别名、日期格式、金额字段与空值表达。
- AI 判断层:仅处理规则难覆盖的备注理解、分类和异常说明。
- 校验复核层:对 AI 结果做 schema、枚举和置信度检查。
- 结果写出层:输出新文件、汇总表、日志、失败队列与人工复核池。
三、最常见的 6 个大坑与应对方案
| 常见坑点 | 典型风险 | 推荐对策 |
| 整本 Excel 一次性读入 | 读取慢、占内存、无关数据太多 | 先看 sheet,再按需读取;只取必要列和必要 sheet |
| 把脏活全丢给 AI | 成本高、输出不稳、解释不可控 | 规则明确的清洗与格式统一放在 Python 侧完成 |
| AI 自由文本输出 | 字段漏失、枚举乱写、后处理崩溃 | 采用结构化输出,并在本地再次校验 |
| 失败任务无记录 | 不知道哪份失败、为何失败、如何补跑 | 建立 logs、failed、review_pool 与 summary 表 |
| 直接覆盖原文件 | 难回滚、难审计、失败后状态混乱 | 保留原始文件,输出新文件或结果总表 |
| 没有人工复核 | 低置信度结果直接入库,风险外溢 | 将低置信度、冲突判断、结构异常进入复核池 |
尤其要注意,AI 并不适合作为“万能清洗器”。日期统一、金额转数值、表头映射、重复项检测等任务,本质上是数据工程问题,应该优先交给 Python 处理;AI 更适合做备注理解、模糊分类、异常原因解释等规则难以穷举的工作。
换句话说,规则能覆盖的就不要浪费 token;只有当业务语义复杂、备注描述含糊、需要归纳判断时,再把数据以精简、结构化的形式交给 AI。
四、成本与稳定性的关键:缩短 AI 输入,而不是增加提示词长度
很多团队在成本失控时,第一反应是更换模型或压缩提示词。其实更大的浪费通常来自输入本身:把几十列、几百行的整张报表转成文本,连同空白列和临时统计列一起发给模型,token 自然会迅速膨胀。
更高效的做法,是先用 Python 进行字段提炼,只把与判断直接相关的列送给 AI。例如:客户名称、日期、金额、备注、所属部门、历史均值、同日重复次数。这些字段足以支持大多数异常识别任务,却远比原表精简。
| 推荐原则 Python 负责“清洗与约束”,AI 负责“理解与解释”。在大批量场景下,少而准的输入,比长而杂的上下文更稳定。 |
五、结构化输出是生产环境的分水岭
测试阶段,模型偶尔多返回一句解释,看起来无伤大雅;但批量任务一跑起来,字段缺失、类型混乱、枚举拼写不一致,就会让后处理逻辑接连报错。
因此,生产环境不应依赖“看起来像 JSON”的自由文本,而应该强制使用结构化输出,并在接收结果后继续做本地校验:字段是否齐全,数值是否在合理范围,枚举是否合法,confidence 是否落在 0 到 1 之间。
| 建议输出字段 | 作用说明 |
| customer_name / report_date / amount | 保留最基本的业务主键,便于回查原始记录 |
| risk_level / issue_type | 控制分类口径,便于筛选与统计 |
| reason | 给人工复核提供可读解释 |
| confidence | 作为自动通过与人工复核的分流依据 |
六、一定要有失败队列、日志和断点续跑
1000 份 Excel 的任务不可能保证零失败。文件损坏、接口超时、格式异常、sheet 为空、返回结构不合法,都可能让任务在中途停住。与其幻想不失败,不如提前设计好失败之后如何定位、如何补跑。
建议至少保留四类输出:一份总状态表记录每个文件的处理状态;一个 logs 目录记录异常详情;一个 failed 清单用于后续重试;一个 checkpoint 文件记录已完成进度。这样即便任务中途被打断,也可以从上次成功的位置继续,而不是全部重头再跑。
七、上线前的检查清单

图 3 在全量运行前,至少完成这 10 项基础检查。
真正的上线门槛,并不在于代码是否“能动起来”,而在于系统是否具备基本的稳定性与可追踪性。下面这 10 项检查,足以帮你在正式跑批前拦下大多数问题:
- 是否只读取了必要的 sheet 与必要列;
- 是否完成了表头别名映射;
- 是否统一了日期、金额、空值格式;
- 是否将规则逻辑优先放到 Python 侧完成;
- 是否限制了 AI 输出字段;
- 是否对 AI 返回值进行了本地 schema 校验;
- 是否设置了重试与退避;
- 是否准备了 checkpoint;
- 是否避免覆盖原始文件;
- 是否为低置信度结果准备了人工复核池。
八、推荐的落地方式:80% 自动通过,20% 进入复核闭环
很多团队会把“全自动”当作目标,但在财务、采购、销售和质检这类场景中,真正成熟的方案通常不是 100% 无人处理,而是让系统自动通过大部分规则明确的记录,再把有争议的部分交给人工。
一个常见且可靠的比例是:80% 的常规记录自动通过,15% 的低置信度结果进入人工复核,5% 的结构异常或严重错误进入失败队列。这样既能显著节省人工时间,又能把真正需要人判断的部分集中出来,避免让 AI 在高风险决策上“单独拍板”。
| 适合这类工作流的场景 财务报销审核、采购明细分析、销售报表归类、运营日报整理、质检记录抽取、合同台账核查等,都很适合采用“Python 规则 + AI 语义判断 + 人工复核兜底”的组合方案。 |
FAQ
1. Python 处理 Excel 报表一定要配合 AI 吗?
不一定。字段统一、规则清晰的场景,单用 Python 就能完成大量工作。AI 更适合处理备注理解、模糊分类和异常解释这类规则难覆盖的部分。
2. 为什么不建议直接覆盖原 Excel 文件?
因为一旦写错或任务中断,原始数据会变得难以回滚与审计。更稳妥的方式是保留 input 原件,输出 processed 文件、summary 总表或审计结果表。
3. 1000 份 Excel 应该直接全量跑吗?
不建议。更推荐先做 10 份样本测试,再做 100 份压测,确认字段映射、读取逻辑、AI 输出和错误处理都稳定后,再进行全量处理。
4. AI 输出不稳定怎么办?
固定提示词、缩小输入范围、采用结构化输出、增加本地校验,并设置 confidence 阈值把低置信度结果送入人工复核池。
5. 哪些团队最适合搭建这种流水线?
经常处理财务、采购、销售、运营、质检、客服工单和台账类 Excel 的团队,都会从这类自动化中显著受益。
结语
用 Python + AI 接口处理 1000 份 Excel 报表,真正的门槛从来不是“怎么把接口接上”,而是怎么把不稳定的表格、复杂的业务规则和可变的模型输出,收束成一条稳定、可控、可追踪的处理链路。
当你先把规则做好、把输入缩短、把输出约束住、把失败记录清楚、把人工复核嵌进去,这条流水线才会真正有业务价值。它不只是帮你省下一次处理时间,而是把重复劳动变成可以持续复用的能力。
