

告别广告:Perplexity 与搜索引擎的差异化使用场景
从“搜链接”到“拿结论”,一篇讲清 Perplexity 与 Google / Bing 的最佳分工方式
图文指南 | 适用对象:内容创作者、研究型用户、知识工作者、AI 工具重度用户
| 导读 这不是一篇“Perplexity 吊打搜索”的情绪文,而是一篇偏实战的分工指南。 • 核心结论只有一句:Perplexity 负责先帮你理解,搜索引擎负责带你抵达原网页、官网与执行入口。 • 真正高效的用户,往往不是二选一,而是建立一套“先综述、再搜索、再核验、再沉淀”的协同流程。 |
| 你最常见的目标 | 优先工具 | 原因 |
| 快速看懂一个复杂问题 | Perplexity | 先给摘要与引用,适合建立全景认知 |
| 找官网 / 下载页 / 商家入口 | 搜索引擎 | 导航与网页发现效率更高 |
| 比价格 / 看地图 / 找本地服务 | 搜索引擎 | 结构化结果、本地信息与交易入口更成熟 |
| 写方案前的资料整理 | Perplexity | 适合多轮追问、比较与资料归纳 |
| 高风险事实核验 | 搜索引擎 + 原网页 | 必须回源核验,不能只看 AI 摘要 |
开篇:为什么越来越多人开始“绕开搜索结果页”
过去十多年,搜索引擎的核心价值是“把网页找出来”。你输入关键词,系统根据相关性、权威性、商业规则和个性化信号,给你一页页链接;你再自己打开、筛选、比对、归纳,最后拼出一个答案。
但在 2026 年,越来越多用户的第一反应不再是“搜十个链接”,而是“先问一句,让系统直接告诉我大概怎么回事”。这正是 Perplexity 这类 AI 搜索产品快速出圈的原因:它不把网页列表当终点,而是把“带引用的答案”当成第一层交付物。
很多人喜欢用一句更直白的话来概括这种变化:搜索引擎负责带你到信息面前,Perplexity 负责先帮你把信息读一遍。前者像检索器,后者更像一位会边查边整理的研究助理。
Perplexity 到底是什么,它和传统搜索引擎本质上差在哪
从产品形态上看,Perplexity 并不是简单地把聊天框套在搜索引擎外面,而是把“搜索 + 阅读 + 归纳 + 连续追问”融合成一个单一界面。用户给出的不是纯关键词,而更像一个问题、一个任务,甚至一个正在不断缩小范围的研究主题。
传统搜索引擎更擅长做“网页发现”和“网页导航”:找官网、找商品、找门店、找地图、找下载页、找某个明确页面。Perplexity 更擅长做“答案组织”和“线索收敛”:比如你要快速理解某个行业、比较多个产品路线、看懂一个复杂概念、拉出一份综述初稿,它通常能更快给你一个可读的起点。
所以两者的差异,不是有没有搜索能力,而是谁把认知负担扛在前面。搜索引擎把负担留给用户;Perplexity 先替你消化一遍,再把结果和来源一起端上来。
为什么很多用户会觉得 Perplexity “更清爽”
第一,是广告感更弱。很多传统搜索场景里,商业页面、SEO 页面、导购聚合页会大量占据视野,用户必须练出一双“去噪眼”。而在 Perplexity 的体验中,首页和回答页更像问答界面,用户先看到的是解释、总结和引用,而不是一串高度竞争过的结果位。
第二,是连续追问更顺。搜索引擎里,你往往需要不断重写关键词:从“AI 搜索工具”改成“带引用的 AI 搜索工具”,再改成“适合做论文资料整理的 AI 搜索工具”。Perplexity 则允许你沿着同一个线程继续追问,让上下文自然延续,认知摩擦更低。
第三,是它更适合复杂问题。很多现实任务并不是一个静态关键词能解决的,比如“给我比较三类知识库方案的优缺点,并告诉我个人用户怎么选”。这类问题本身就需要拆解、整合、归纳,而这恰恰是 Perplexity 的强项。
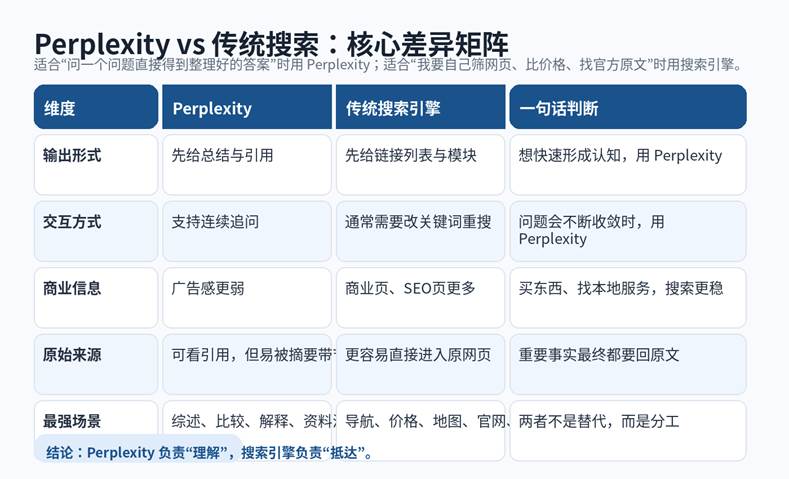
图 1:Perplexity 与传统搜索的核心差异,不在于“谁更先进”,而在于“谁先替你承担理解成本”。
六个常见问题,直接给你工具选择建议
| 用户问题 | 第一选择 | 建议动作 |
| “帮我先理解一下 AI 浏览器到底是什么” | Perplexity | 先看综述,再顺着引用去读原文 |
| “我要下载某软件的 Windows 安装包” | 搜索引擎 | 直接找官网或官方文档页 |
| “帮我比较三款 AI 工具的优缺点” | Perplexity | 先拉对比框架,再回官网查价格和限制 |
| “附近哪家店今天还营业?” | 搜索引擎 / 地图 | 本地实时信息更适合传统搜索与地图 |
| “这条新闻到底谁最早发布的?” | 搜索引擎 | 优先回原始媒体或官方公告 |
| “我想整理一份调研提纲” | Perplexity | 更适合多轮追问与结构化收敛 |
但别急着“抛弃搜索引擎”:哪些场景仍然是搜索更强
如果你的目标是进入某个明确入口,传统搜索往往更高效。例如找某品牌官网、找某软件官方下载、找本地门店、查路线、看商家评价、比价格、看库存、找政府公告原文,这些都依赖丰富的垂类结果、地图、卡片、结构化信息和成熟的网页索引体系。
再比如,当你要判断信息是否可靠时,最稳的方式仍然是回到原网页,核对作者、发布时间、上下文、图表、条款和原始数据。Perplexity 可以帮你快速找到候选来源,但不能替代你完成最终的原文核验。
还有一类场景是交易和执行。买机票、订酒店、下单、注册、提交表单、下载文档、访问某个具体页面,这些任务的终点不是“知道答案”,而是“抵达入口”。在这件事上,搜索引擎依旧非常强。
最实用的判断方式:什么时候先问 Perplexity,什么时候先去搜
一个很好记的判断法则是:当问题的目标是“理解”,先问 Perplexity;当问题的目标是“抵达”,先用搜索引擎。
所谓“理解”,包括做综述、做解释、做比较、做拆解、做调研初稿、找思路、收敛关键词、拉出候选框架。所谓“抵达”,包括找官网、找价格、找地图、找下载页、找商家、找活动入口、找本地服务、找实时公告与原始文档。
如果你把两者协同起来,效率通常会更高:先让 Perplexity 帮你建立全景和关键词,再回到搜索引擎精准抵达原网页、官方站点或交易入口,最后再把确认过的信息收回到笔记系统里。

图 2:真正高效的做法不是“只用一个工具”,而是把 AI 搜索与传统搜索接成一条完整链路。
五类最典型的差异化使用场景
第一类:概念入门与行业综述。比如你刚接触“AI 浏览器”“RAG”“知识库自动化”等概念,Perplexity 通常比传统搜索更省时间,因为它能直接给你定义、背景、代表产品和延伸线索。
第二类:产品横向比较。比如比较多个模型、多个 AI 工具、多个 SaaS 方案时,Perplexity 很适合先拉出对比框架;但涉及真实价格、促销、套餐细则时,仍应回到官网或搜索结果核验。
第三类:本地化与交易型需求。找餐厅、找维修、找门店营业时间、找票务和价格、看地图路线,这类任务传统搜索与地图产品优势明显,Perplexity 并不是最佳第一入口。
第四类:原文核验与事实确认。新闻、政策、医疗、法律、平台规则、版权条款等需要高准确性的内容,Perplexity 只能作为导航与摘要工具,不能替代原文阅读。
第五类:持续追问式研究。写方案、写文章、做学习规划、整理市场资料时,Perplexity 的线程化追问和带引用回答非常顺手,更适合当“研究助理”。
一套真正高效的协同工作流
高效用户通常不会只站队某一个产品,而是建立一套协同链路。第一步,用 Perplexity 生成全景认知:把你要研究的问题说完整,让它先给出关键概念、候选方向、常见争议与来源列表。
第二步,把 Perplexity 给出的关键词、机构名、产品名、政策名拿去搜索引擎做二次精准搜索。这样你不是盲搜,而是带着更清楚的意图进入搜索。
第三步,打开原网页做回源核验。重点检查发布日期、作者、条款、是否为官网、是否存在二手转述,以及数据是否已经过时。
第四步,把确认过的信息沉淀到自己的知识库里,比如 Notion、Obsidian 或飞书文档。这样你下次就不必从零开始,AI 也更容易在你的上下文中给出高质量答案。
使用 Perplexity 时最容易踩的四个坑
第一,把“带引用”误认为“绝对正确”。引用只能说明它引用了来源,不能自动证明结论百分之百可靠。摘要过程本身仍然可能遗漏细节、误读上下文或引用过时页面。
第二,把“综述”当成“原文”。Perplexity 的最大价值是帮你缩短进入主题的时间,而不是替你承担最终的事实责任。越重要的决策,越要看原文。
第三,把所有问题都交给 AI 搜索。不是每个任务都适合聊天式入口。找下载、找商家、找地图、找客服电话、找官方提交入口时,传统搜索常常更直接。
第四,忽视信息时效与地域差异。对本地服务、区域政策、实时价格、限时活动这类内容,搜索引擎和官方页面通常更可靠,AI 摘要只能当作辅助。
结语:Perplexity 不是搜索引擎的终结者,而是搜索方式的一次重排
真正的变化,不是“搜索被替代”,而是“搜索链路被重构”。过去用户先看到链接,再自己组织答案;现在用户先看到一个答案,再决定要不要继续打开链接。
因此,Perplexity 适合做认知前置和研究提速,传统搜索依旧掌管网页发现、入口抵达、商业信息、本地服务和原文核验。两者并不是谁替代谁,而是谁在你的工作流里先出场。
如果你想真正提升效率,最值得练的不是只会用某一个工具,而是建立判断力:什么问题该直接问 AI,什么问题必须回到网页,什么内容一定要核对原始来源。会分工的人,才会真正从 AI 搜索里获益。
FAQ:关于 Perplexity 与搜索引擎,最容易问的 8 个问题
1. Perplexity 会不会彻底替代 Google?
不会。Perplexity 更像对搜索前半段的一次重构:它把“阅读和归纳”前置了,但网页发现、导航、地图、本地服务、交易入口和官方原文查找,依旧是传统搜索的强项。
2. Perplexity 没有广告,是不是就一定更客观?
不一定。广告少并不等于没有偏差。AI 摘要仍然可能受模型理解方式、来源选择、上下文遗漏和内容可访问性影响,所以关键结论仍需回源核验。
3. 我做内容创作,最适合怎么用 Perplexity?
最适合把它当成选题研究和资料综述工具:先让它拉出背景、观点、争议和来源,再自己读原文、做判断、写成自己的结构。
4. 购物、比价、找店铺,Perplexity 值得当第一入口吗?
通常不建议。涉及价格、库存、商家、时效、本地门店、优惠活动时,传统搜索、地图和电商平台的入口更直接。
5. Perplexity 适合做学术或专业研究吗?
适合作为前期摸底与资料线索收集工具,但不适合作为最终证据。学术与专业领域尤其要看原始论文、官方文件、法规原文与数据来源。
6. 搜索引擎现在也有 AI 摘要了,为什么还要单独看 Perplexity?
两者体验相似但主导逻辑不同。很多搜索引擎仍以结果页和网页生态为中心,Perplexity 则更彻底地把“回答线程”作为核心交互。
7. 我应该站队 Perplexity 还是 Google/Bing?
都不用。最好的策略是建立分工:复杂理解先问 Perplexity,入口、价格、实时信息和原文核验回到搜索引擎。
8. 有没有一句话的终极判断法?
有:当你的目标是“理解”,优先 Perplexity;当你的目标是“抵达”,优先搜索引擎。
相关阅读
- 《AI 浏览器会不会成为下一个超级入口?从搜索到执行的产品演进》
- 《OpenClaw 是什么?为什么 2026 年大家都在聊 AI Agent“龙虾”生态》
- 《Notion AI 深度集成:打造你的个人智能知识库》
- 《从 0 到 1 搭建你的个人 AI 第二大脑:Obsidian + AI 深度整合指南》
信息说明
本文为策略型、场景型使用指南。涉及产品能力与行业趋势的部分,依据公开产品页、帮助中心与官方博客整理,并结合实际使用逻辑进行归纳。请在涉及价格、政策、版权、医疗、法律、投资等高风险事务时,务必回到原始来源核验。
