
Perplexity 最新动态:AI 搜索工具如何改变资料整理方式
从实时搜索、引用来源到 Computer / Comet:一篇适合网站发布的图文教程

封面图:Perplexity 正在把 AI 搜索从“找资料”推进到“可复核、可交付、可复用”的研究工作流。
适用栏目:AI工具库 / AI 最新动态 / 保姆级教程 / 实战工作流
文章摘要
Perplexity 最初被很多用户理解为“带引用的 AI 搜索引擎”,但它正在快速向“研究工作台”和“个人/企业级 AI 执行助手”演进。最新更新显示,Perplexity 的重点已经不只是给出答案,而是把网页搜索、文件读取、引用溯源、深度研究、浏览器辅助、文档/表格/PPT/网页生成和企业连接器放到同一条工作流里。
这意味着资料整理方式也在变化:过去是先搜索关键词、打开多个网页、复制重点、手动整理文档;现在更像是先提出研究问题,让 AI 建立资料底稿,再围绕引用和原文进行人工复核,最后把结果转成文章、报告、表格、PPT 或可分享网页。
更新速览:Perplexity 正从“答案引擎”变成“研究工作台”
从 Perplexity 近期 changelog 看,产品重心非常清晰:一边增强 Computer / Personal Computer 的多步骤任务能力,一边把 Comet 浏览器扩展到主流平台,同时让 Deep Research 与资产生成能力更接近“从资料到交付物”的完整链路。
| 更新方向 | 代表功能 | 对资料整理的影响 |
| AI 搜索与引用 | Search / Pro Search / Research / Deep Research | 从“找到链接”变成“快速形成可追溯的资料底稿”。 |
| 浏览器内研究 | Comet Browser / Comet Assistant | 在浏览网页、阅读邮件、查看资料时直接总结、提问和执行操作。 |
| 多步骤执行 | Computer / Personal Computer | 把整理资料、生成报告、做表格、建网页等任务串成一个执行流程。 |
| 文件与多模态 | 文件上传、音视频转写、图片/代码/PDF 读取 | 让本地材料、会议记录、研究报告和网页资料可以一起进入上下文。 |
| 企业与开发者 | Spaces、Skills、Teams、Slack、API Platform | 把个人研究流程扩展到团队知识库、企业数据和自有产品。 |

图 1:Perplexity 的最新能力矩阵。
Perplexity 的核心更新有哪些?
Computer / Personal Computer:把搜索变成可执行任务
Perplexity Computer 的定位已经超过“高级搜索”。它可以在单个对话中调用多模型、连接器和技能,处理研究、写作、分析、文件编辑、网站生成等多步骤任务。2026 年 5 月 11 日,Perplexity 宣布 Personal Computer 在 Mac 上面向所有用户开放,可以连接本地文件、应用和 Comet 浏览器上下文,让 Computer 基于用户桌面里的资料继续工作。
对资料整理来说,这个变化很关键:资料不再只是网页结果,还可以包括你电脑里的本地文档、日历、浏览器标签页和正在处理的文件。更像是把“资料收集员 + 初稿编辑 + 文件整理员”合并到同一个操作入口。
Comet 浏览器:在浏览过程中直接研究、总结、操作
Comet 是 Perplexity 的 AI 原生浏览器。官方页面强调它可以理解网页内容、帮助用户研究不同媒体如何报道同一事件、起草邮件、创建学习计划、辅助购物或处理浏览器内任务。2026 年 3 月 27 日的更新中,Perplexity 表示 Comet 已面向 iOS 用户推出,并覆盖 iOS、Android、Mac 和 Windows 等主要平台。
这会改变资料整理的入口:以前用户打开浏览器是“看网页”;现在浏览器本身会变成“资料助手”。当你浏览一篇长报告、新闻专题或产品文档时,可以让 Comet 在当前页面里做摘要、提炼争议点、比较多个来源,甚至把页面内容整理成决策备忘录。
Deep Research 与资产生成:从资料到可交付物
Perplexity 在 2026 年 3 月 27 日的更新中提到,Deep Research 和 Pro Search 已支持在产品内创建演示文稿、电子表格、仪表盘、网站等结构化输出。这说明 Perplexity 的研究链路正在从“给我一段回答”升级为“给我一个能直接使用的成品”。
对于网站作者、自媒体运营、产品经理和企业研究人员来说,这类能力的价值不在于省掉所有人工工作,而在于快速完成初始整理:先生成资料框架、证据表、对比表和初稿,再由人进行事实核查、观点修正和发布排版。
文件上传与多模态材料:资料整理入口变宽
Perplexity Help Center 显示,用户可以在新线程中通过“+ Attach”上传文件,也支持拖拽文件和文件夹。支持材料包括文本、代码、PDF、图片,以及音频和视频文件;音频和视频会被转写成可搜索文本,并支持说话人标注。
这让资料整理的边界扩大了:会议录音、访谈视频、课程音频、研究报告 PDF、网页资料、代码文件,都可以进入同一个研究上下文。对做教程文章的人来说,尤其适合把“公开资料 + 自己收集的材料 + 采访/会议记录”统一整理成一篇内容。
API 平台:把实时搜索和引用能力接入自己的产品
Perplexity API 平台目前包括 Agent API、Search API、Sonar API 和 Embeddings API。官方文档将 Search API 描述为面向实时网页结果的接口,Sonar API 则偏向带引用的网页 grounded AI 回答,Agent API 支持多供应商模型、实时搜索工具、推理控制和 token 预算。
这意味着 Perplexity 不只是一个网页端搜索工具,也在向“可集成的搜索/研究基础设施”发展。开发者可以把实时检索、引用、网页结果排序和智能体能力接入 CRM、知识库、行业监测、销售研究或内容生产系统。
AI 搜索如何改变资料整理方式?
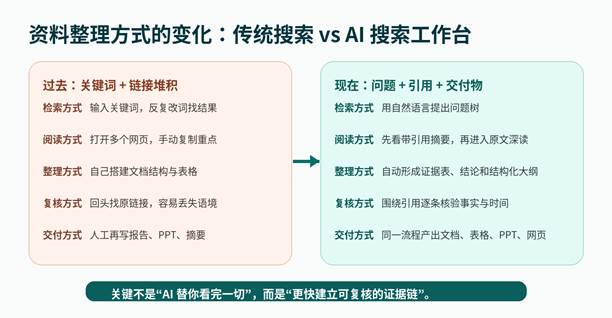
图 2:资料整理从传统搜索转向 AI 搜索工作台。
从关键词搜索,变成问题树拆解
传统搜索通常从关键词开始,用户需要不断换词、筛链接、判断相关性。AI 搜索更适合从问题开始:先把主题拆成背景、定义、时间线、观点差异、典型案例、数据证据和适用人群,再让工具分别检索。
例如,写“AI 搜索工具如何改变资料整理方式”,不要只搜这个标题,而要拆成:AI 搜索与传统搜索区别、Perplexity 最新功能、Deep Research 场景、文件上传能力、引用可信度、适合自媒体的工作流、风险与版权注意事项。
从链接堆积,变成证据表
资料整理最容易出问题的地方,是最后只剩一堆链接,真正写作时找不到每个观点对应哪条证据。Perplexity 的引用机制可以帮助用户先形成“观点—来源—时间—可信度—可用方式”的证据表。
建议每次研究都要求工具输出一张证据表:观点写一句话,来源列出原文标题和发布时间,可信度标注为官方文档、新闻报道、第三方测评或用户反馈,最后标注这条信息适合写在文章的哪一部分。
从阅读资料,变成先结构化再深读
AI 搜索不是替代阅读,而是改变阅读顺序。过去用户从第一篇文章开始读;现在可以先让 AI 把多个来源整理成结构化大纲,再回到最关键、最新、最权威的原文进行深读。
这种方法特别适合资料量大的选题。先用 AI 找出关键分歧、核心术语和时间线,再人工验证高价值来源,效率会比从头读到尾更高。
从单人整理,变成团队知识工作流
Perplexity 的 Spaces、Computer in Slack、Computer in Microsoft Teams、Space Skills 等功能,指向的是团队协作场景:把资料、任务、风格规范和常用流程沉淀到工作空间里。
对企业用户来说,AI 搜索不只是“找答案”,还可以变成“每周自动整理竞品动态”“根据销售会议生成客户简报”“把网站审计结果整理成优先级清单”等可复用流程。
从一次性回答,变成持续任务和可复用技能
Perplexity Computer 的 Workflows 和 Skills 方向说明,资料整理会越来越像“模板化任务”。同一个选题研究流程、竞品分析流程、新闻监测流程、SEO 审计流程,可以被封装成重复调用的能力。
这对网站运营尤其重要:如果你长期写 AI 工具更新、教程和测评,可以把“查官方更新—查第三方报道—整理功能表—生成教程—产出 SEO 文档—生成 FAQ”的流程固定下来。
适合哪些资料整理场景?
| 使用场景 | 推荐用法 | 输出结果 |
| AI 工具最新动态文章 | 让 Perplexity 对比官方 changelog、产品页、帮助中心和新闻报道。 | 更新时间线、功能变化表、适合用户、FAQ。 |
| 竞品分析报告 | 围绕多个竞品建立功能、价格、用户口碑、更新频率的对比表。 | 竞品矩阵、差异化结论、决策建议。 |
| 行业趋势研究 | 用 Research / Deep Research 追踪政策、融资、技术、产品发布和媒体观点。 | 趋势报告、关键时间线、风险清单。 |
| 课程或论文资料整理 | 上传 PDF、课程资料、讲义,让 AI 提炼核心概念并补充来源。 | 学习笔记、概念卡片、复习题、引用清单。 |
| 会议/访谈内容整理 | 上传音频或视频,让系统转写并提炼要点。 | 纪要、行动项、可发布问答稿。 |
| 网站内容生产 | 把选题、资料、SEO 要求和历史文章放入同一流程。 | 文章初稿、SEO 文档、FAQ、内链建议。 |
网站作者如何使用 Perplexity 整理一篇文章?
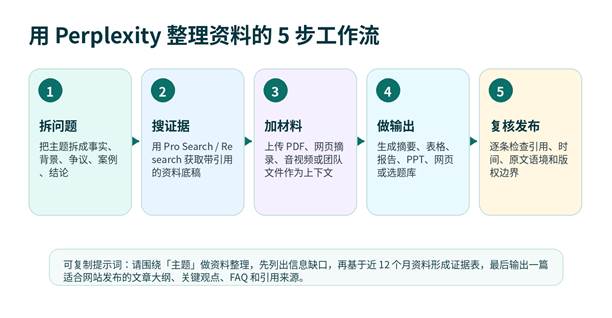
图 3:适合网站发布内容的 Perplexity 资料整理工作流。
第 1 步:先定义文章任务,而不是直接搜索
建议把任务写清楚:文章类型、读者对象、发布时间范围、是否需要教程、是否需要 FAQ、是否要 SEO 文档。任务越具体,AI 搜索越容易把资料整理到正确方向。
示例:请围绕“Perplexity 最新动态:AI 搜索工具如何改变资料整理方式”做资料整理,优先参考官方 changelog、帮助中心和 API 文档,再补充权威媒体报道。请输出适合网站发布的文章大纲、功能表、使用教程、FAQ 和 SEO 元信息。
第 2 步:要求它先列信息缺口
不要急着让 AI 写全文。第一轮最好让它列出还需要确认的问题,例如:最近一次更新日期是什么?Computer 和 Comet 的区别是什么?Deep Research 是否能生成 PPT 或表格?文件上传支持哪些类型?API 平台面向谁?
这一步能避免文章只停留在泛泛介绍,也能提醒你哪些事实必须回到官方来源核对。
第 3 步:把引用整理成证据表
让 Perplexity 输出“证据表”,而不是直接输出一篇华丽文章。证据表至少包括:观点、来源标题、来源类型、发布日期、原文要点、适合写入文章的位置。
这一步对网站内容很重要:后续改稿、查错、补链接、做 SEO 描述时,都能回到证据表快速定位来源。
第 4 步:再生成文章、FAQ 和 SEO 文档
当事实底稿比较可靠后,再让 AI 生成文章正文。建议明确要求:正文一级标题使用 H2,二级标题使用 H3;封面标题不作为正文 H1;FAQ 放在末尾;相关阅读使用相对链接。
如果是 WordPress 文章,还可以让它同时输出主标题、别名、分类、标签、SEO 标题、SEO 描述、特色图 Alt、特色图标题、说明和描述。
第 5 步:人工复核,不要直接发布
AI 搜索最大的优势是快,但它并不等于最终编辑。发布前至少复核四件事:第一,核心事实是否来自官方或权威来源;第二,引用是否支持对应观点;第三,日期和版本是否最新;第四,是否涉及版权、隐私或未经授权的内容复用。
可复制提示词模板
| 目标 | 提示词模板 |
| 快速整理更新点 | 请帮我整理 Perplexity 最近 3 个月的重要产品更新,优先使用官方 changelog、帮助中心和 API 文档。按“更新时间—功能名称—影响场景—适合用户—注意事项”输出表格。 |
| 生成证据表 | 请把资料整理成证据表:观点、来源标题、来源类型、发布日期、原文摘要、适合写入文章的位置。只保留能被来源支持的观点。 |
| 写网站文章 | 请根据证据表写一篇中文网站发布文章,标题为《Perplexity 最新动态:AI 搜索工具如何改变资料整理方式》。正文一级标题用 H2,二级标题用 H3,包含教程步骤、FAQ、相关阅读和风险提醒。 |
| 做竞品对比 | 请把 Perplexity 与传统搜索、ChatGPT 搜索、Gemini、Kimi 在“资料检索、引用、长文档、浏览器、团队协作、交付物生成”维度做对比,并给出适合人群。 |
| 生成 SEO 元信息 | 请为这篇文章生成 SEO 文档:文章摘要、主标题、别名、标签、SEO 标题、SEO 描述、5 个关键词一行逗号分隔、特色图 Alt、标题、说明、描述、FAQ Schema 建议。 |
与传统搜索、通用聊天机器人有什么区别?
Perplexity 的差异不在于“它也能聊天”,而在于它更强调实时检索、引用来源和研究链路。传统搜索给链接,通用聊天机器人擅长写作和推理,而 Perplexity 的强项是把公开网页、文件资料和引用结果组织成一个可继续追问、可输出、可复核的资料整理过程。
| 工具类型 | 强项 | 短板 | 更适合的任务 |
| 传统搜索引擎 | 覆盖面广、原始链接多、适合人工深挖。 | 需要自己筛选、阅读和整理。 | 查找官网、查原文、验证来源。 |
| 通用聊天机器人 | 写作、改写、代码、头脑风暴能力强。 | 如果没有联网或引用机制,时效与可追溯性不足。 | 写初稿、改结构、生成表达方案。 |
| Perplexity 类 AI 搜索 | 实时检索、引用溯源、研究报告和资料整理链路更突出。 | 仍需人工核查引用是否准确支持观点。 | 资料搜集、证据表、研究简报、竞品分析。 |
| 企业智能体/工作流 | 可连接内部数据和应用,适合重复任务。 | 配置、权限和安全要求更高。 | 销售简报、数据分析、团队知识库。 |
使用风险与注意事项
- 不要只看 AI 摘要。重要结论必须打开原文,确认上下文、发布时间和是否仍然有效。
- 不要把“有引用”误解为“完全正确”。引用可能只支持部分观点,或来源本身并不权威。
- 涉及价格、政策、产品可用地区、会员权益时,优先查看官方页面和最新 changelog。
- 上传公司文件、客户资料、合同、财务数据前,先确认账号类型、数据保留策略、企业权限和内部合规要求。
- 生成文章时避免大段照搬来源文本,要基于多来源综合后重新组织表达。
- 对争议性话题保留不同来源视角,不要只摘取支持自己观点的材料。
FAQ
Perplexity 适合用来写网站文章吗?
适合做资料搜集、证据整理、文章大纲和初稿生成,尤其适合需要引用公开资料的工具介绍、行业趋势、竞品分析和教程文章。但最终发布前仍需要人工核查事实、日期、链接和表达。
Perplexity 和普通搜索引擎最大的区别是什么?
普通搜索引擎主要返回链接,用户自己阅读和整理;Perplexity 会把多个来源综合成带引用的回答,并支持追问、Research、文件上传和结构化输出。
Deep Research 适合什么场景?
适合复杂问题,例如行业趋势、竞品分析、政策背景、技术路线对比、市场报告等。它的价值在于多步检索和综合分析,而不是简单问答。
Comet 浏览器对资料整理有什么用?
Comet 可以在浏览网页时直接总结内容、比较不同来源、起草邮件或执行页面内任务,适合边阅读边整理。
文件上传能处理哪些材料?
Perplexity 帮助中心显示可上传文本、代码、PDF、图片、音频和视频等材料;音视频会被转写成可搜索文本,但视频画面本身并非重点索引对象。
为什么仍然需要人工复核?
因为 AI 搜索可能出现引用不充分、遗漏最新信息、误读原文语境或混合不同来源结论的问题。人工复核能保证文章可发布、可负责。
参考资料
Perplexity Changelog:Personal Computer on Mac for all – May 11, 2026:https://www.perplexity.ai/changelog/personal-computer-for-all-users-on-mac
Perplexity Changelog:Improved Computer Models and Enterprise Updates – May 4, 2026:https://www.perplexity.ai/changelog/improved-computer-models-and-enterprise-updates—may-4-2026
Perplexity Changelog:Comet iOS Launch and Computer Updates – March 27, 2026:https://www.perplexity.ai/changelog/what-we-shipped–march-27-2026
Perplexity Changelog:What We Shipped – March 13, 2026:https://www.perplexity.ai/changelog/what-we-shipped—march-13-2026
Perplexity Help Center:File Uploads:https://www.perplexity.ai/help-center/en/articles/10354807-file-uploads
Perplexity API Platform:https://www.perplexity.ai/api-platform
Perplexity API Docs:Quickstart:https://docs.perplexity.ai/docs/getting-started/quickstart
Perplexity API Docs:Sonar Models:https://docs.perplexity.ai/docs/sonar/models
工具选型与提示词资料
适合阅读工具评测、工具推荐、对比测评类文章后继续转化。
