

开源还是闭源?中小企业选择 AI 大模型方案的 3 个核心维度
版本:2026 最新修订版 · 定位:企业 AI 选型 / 管理决策 / 落地路线图 · 适用对象:中小企业老板、产品负责人、技术负责人
| 一句话结论:对多数中小企业而言,2026 年最稳妥的策略并不是在“开源”和“闭源”之间做意识形态式站队,而是先用闭源 SaaS 或 API 快速验证 ROI,再把高频、敏感、可复用的核心场景迁到开源或私有化环境。 |
过去两年,企业在大模型选型上最容易犯的错误有两个:一是只看模型榜单,不看组织能力;二是只看单次调用价格,不看整体交付成本。真正决定项目成败的,往往不是模型参数,而是你是否在正确的场景里用对了路线。

图 1 中小企业做大模型选型时,最该优先核算的 3 个维度
一、为什么 2026 年已经不适合用“开源 or 闭源”二分法看问题
今天的企业选择,其实至少有四种:① 直接采购闭源 SaaS;② 调用闭源 API;③ 使用托管的开源 / 开权重模型服务;④ 自部署开源 / 私有化模型。不同路线的边界正在变得模糊:一方面,闭源厂商不断补齐企业级隐私、审计和数据控制能力;另一方面,开源生态也越来越强调托管、兼容 OpenAI API、降低迁移成本。
因此,中小企业更合理的判断方式不是“哪一派更先进”,而是“我的业务在未来 6–12 个月最怕什么”:是怕上线慢、怕没人维护,还是怕数据出墙、怕被单一供应商锁死、怕后期定制受限?
二、核心维度 1:总拥有成本,不要只盯着模型单价
企业真正要看的不是单次调用多少钱,而是 TCO(Total Cost of Ownership,总拥有成本)。一套看似“免费”的开源方案,可能在 GPU、日志、评测、告警、容灾、版本切换和运维值守上付出更高代价;一套看似“贵”的闭源方案,反而可能因为省掉了平台建设和人力成本,在试点阶段更便宜。
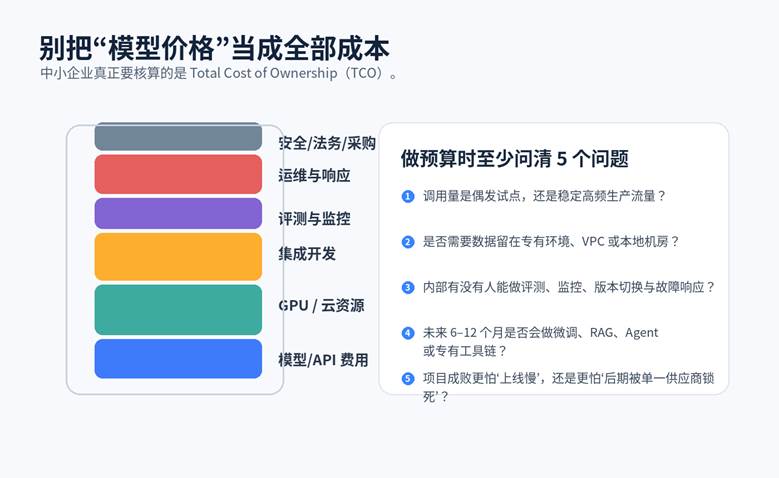
图 2 模型价格只是企业 AI 成本结构的一部分
闭源路线更常见的优势:
- 可以按 seat 或按 token 采购,预算模型更简单,MVP 更快。
- 模型、工具链、语音、图像、搜索、Agent 等能力通常已经打包,不必自己拼装。
- 当调用量还不稳定时,按需付费往往比自建 GPU 集群更划算。
开源 / 私有化路线更常见的优势:
- 当业务流量稳定且规模较大时,单位成本可能逐渐优于高阶闭源 API。
- 可根据业务需要换模型、降精度、做蒸馏、微调或自定义推理栈。
- 适合把模型能力沉淀为公司自己的技术资产,而不只是租用能力。
管理层应该追问的 3 个问题:
- 这套方案是为了 4 周试点,还是为了 12 个月规模化上线?
- 内部到底有没有人能做模型评测、上线回滚、故障响应和成本优化?
- 如果下季度调用量翻 10 倍,现有路线的单位成本会怎么变化?
三、核心维度 2:数据、合规与控制权
这不是一句“我很重视安全”就能解决的问题,而要拆成具体控制项:业务数据是否默认参与训练?日志保留多久?能否做 VPC、专有环境或本地部署?有没有审计能力、权限边界和管理接口?
2026 年的变化是:闭源厂商在企业隐私承诺上已经成熟得多,开源生态在私有化和可迁移性上也更完整。也正因如此,企业真正要比的是“控制权够不够”,而不是简单地把闭源等同于不安全。
| 判断项 | 闭源更适合 | 开源/私有化更适合 | 容易忽略的坑 |
| 训练策略 | 已有清晰的企业数据不默认训练承诺,适合办公与协作场景 | 需要“数据不出墙”、自管日志与模型版本 | 把消费级条款误当成企业级条款 |
| 部署边界 | 可以接受厂商托管,只要求企业级账号、权限与审计 | 必须放进 VPC、本地机房或专有环境 | 忽视跨区域、跨云和数据驻留要求 |
| 行业监管 | 以通用办公提效为主,合规要求相对温和 | 金融、政务、医疗、制造研发等敏感场景更常见 | 只看模型效果,不看法务和采购流程 |
| 长期控制 | 更看重现成体验和供应商 SLA | 更看重自主可迁移、可替换和定制空间 | 低估后期迁移和重构成本 |
在企业级隐私与控制上,至少有三类公开能力值得关注:
- 闭源厂商的企业承诺:如是否默认不拿业务数据训练、是否支持合规文档、是否有更低数据留存方案。
- 托管开源的兼容性:例如是否支持 OpenAI 兼容接口,是否方便后期迁移。
- 私有化部署的落地成本:不仅是能不能部署,更是部署后谁负责稳定性、告警、升级与审计。
四、核心维度 3:交付速度、定制化与组织能力
中小企业最贵的往往不是模型,而是时间窗口。很多团队错失机会,并不是因为模型不够强,而是因为从采购、集成到上线拖得太久。闭源方案通常更适合快速试点和跨部门推广;开源方案则更适合把 AI 能力深度嵌进业务系统、专有知识、企业流程和私有工具链。
一般来说:
- 要速度:优先闭源 SaaS / API。适合客服助手、会议纪要、内容初稿、办公协同等快速落地场景。
- 要深定制:优先开源或混合。适合企业知识问答、私有代码库助手、行业规则引擎、内嵌式 AI 产品。
- 要兼顾:优先混合架构。前台提效用闭源,核心数据与高频链路逐步迁往可控环境。
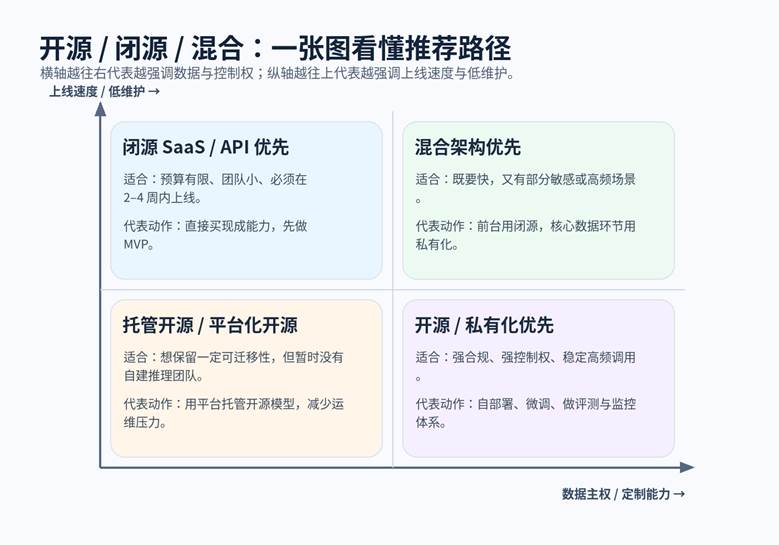
图 3 按速度与控制权要求选择闭源、开源或混合路径
五、四种最常见的企业落地路线
| 路线 | 最适合谁 | 优点 | 风险提示 |
| A | 10–50 人团队,先做 MVP | 最快上线,采购和推广门槛低 | 最怕后期发现成本和权限边界不够用 |
| B | 已有研发团队,准备做产品内嵌 AI | API 快,便于验证功能与用户需求 | 模型、工具与价格体系受供应商节奏影响 |
| C | 有一定平台能力,但不想自建全套推理栈 | 可托管开源,兼顾迁移性与速度 | 别误以为“托管开源”就等于零运维 |
| D | 强合规、强定制、稳定高频场景 | 控制权最高,可沉淀长期资产 | 最怕低估评测、监控、故障与升级的复杂度 |
我的建议是:多数中小企业先从路线 A 或 B 起步,再根据数据敏感度与调用规模,平滑过渡到路线 C 或 D。真正少见的不是“纯开源成功”,也不是“纯闭源成功”,而是从一开始就把全部鸡蛋放在单一路线里。
六、给中小企业的最终决策清单
- 先定义业务目标:你要解决的是效率问题、营收问题,还是合规与知识沉淀问题?
- 先跑试点,再谈平台:没有清晰 ROI 的情况下,不要一上来就砸钱自建大而全平台。
- 把数据分层:公开数据、普通业务数据、敏感核心数据,不要用同一条技术路线一刀切。
- 把场景分层:通用办公提效适合闭源;核心系统、稳定高频链路更适合开源或私有化。
- 留迁移余地:接口、评测集、提示词和业务流程尽量标准化,避免未来切换时全部重写。
真正成熟的企业 AI 方案,通常不是“最先进”的那条,而是“最适合当前组织能力”的那条。
FAQ
1. 中小企业是不是一开始就该上开源?
不一定。若团队还在验证需求、没有稳定调用量、也没有专门的平台或 MLOps 人员,直接上自部署通常会把试点周期拉长。更稳妥的方式往往是先用闭源 SaaS / API 验证业务价值。
2. 闭源就一定更贵吗?
也不一定。试点阶段闭源反而可能更便宜,因为它省掉了基础设施、运维、人力和评测体系建设。真正要比较的是 6–12 个月维度的总拥有成本,而不是一次调用的价格。
3. 开源是不是就更安全?
前提是你真的有能力把私有化部署、权限、审计、告警和更新维护都做扎实。否则“能部署”不等于“安全可用”。
4. 有没有适合多数中小企业的默认答案?
有,一个相对稳妥的默认答案是:前台办公和通用提效优先用闭源,核心数据与高频业务链路逐步迁到开源或私有化环境。
5. 什么时候必须认真考虑混合架构?
当你同时满足三个条件时:一,已经有验证过 ROI 的 AI 场景;二,数据敏感度上升;三,调用规模和定制需求开始增长。这个阶段继续单押某一端,往往都会变得不经济。
相关阅读
- 《逻辑推导选 GPT,创意写作选 Claude?教你根据任务精准匹配模型》
- 《长文本之王是谁?实测 Claude 3.5、GPT-4o 与 Kimi 的上下文理解上限》
- 《盘点那些深度集成 AI 功能的国产办公软件(WPS、飞书、钉钉)》
- 《不用梯子也能飞:2026 国内最值得使用的 Top 10 AI 应用推荐》
- 《小白必看:本地部署 DeepSeek 需要什么样的电脑配置?》
资料说明
本文基于截至 2026-04-08 的官方公开页面整理,重点参考了 OpenAI 企业隐私与 API / Business 定价页、Anthropic 商业数据使用与 Enterprise 定价页、Alibaba Cloud Qwen 开源与 OpenAI 兼容接口说明、以及 Mistral 的自部署与私有化部署说明。由于各厂商功能、条款与价格可能继续调整,正式采购前请以最新官方页面和合同条款为准。
