
零基础入门 · 新手友好 · 可直接照做
作者整理说明:本文基于 Ollama 官方文档与 2026 年 3 月公开信息撰写,重点面向首次本地部署用户。
Ollama 本地部署大模型完整教程,小白也能学会
从下载安装到拉模型、跑 API、接入第三方工具,再到迁移模型目录与常见报错排查,按顺序照着做就能跑起来。
| 先看结论:第一次上手,建议这样做 • 新手优先选 Windows 图形安装或 macOS / Linux 官方脚本安装,别一开始就折腾 Docker。 • 第一个模型建议从 3B / 4B 级别开始,例如 llama3.2:3b 或 qwen3:4b,先确保环境、磁盘与 API 都跑通。 • 当你需要接入编辑器、工作流工具或自建应用时,本地地址通常就是 http://localhost:11434。 • 如果遇到磁盘爆满、下载慢、模型卡死等问题,优先检查模型大小、代理设置和 OLLAMA_MODELS。 |
一、Ollama 到底是什么,为什么适合新手
简单说,Ollama 是一个把本地大模型“装起来、拉下来、跑起来、接出去”的工具层。它能在 macOS、Windows 和 Linux 上运行,提供命令行与本地 API;你既可以直接在终端聊天,也可以让自己的应用通过 localhost 调它。
对新手来说,它最大的价值不是“功能最多”,而是上手路径最短:安装后先 pull 一个模型,再 run 起来测试,最后再决定要不要接 IDE、知识库、自动化工作流。
• 支持 macOS、Windows、Linux 三个平台。
• 本地 API 默认走 http://localhost:11434,局域网/本机调试很直观。
• 既能运行公开模型,也支持通过 Modelfile 基于已有模型、Safetensors 权重或 GGUF 文件创建自定义模型。
• 新版文档已经提供 OpenAI 与 Anthropic 兼容接口,方便把现有应用切到本地后端。
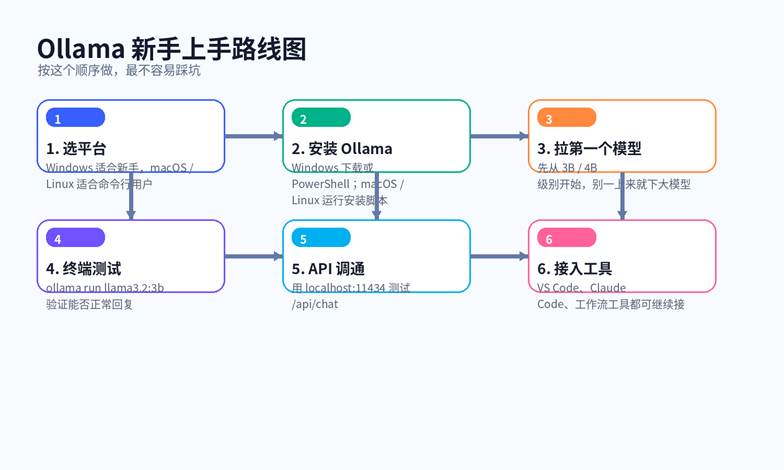
图 1:新手最稳妥的上手顺序,是先装环境、再拉小模型、再调 API。
二、安装前先搞清楚:你需要准备什么
先说最现实的一点:本地部署从来都不是“装完就一定飞快”。是否好用,主要取决于三个变量:模型大小、你的内存 / 显存、以及你是不是只做轻量问答。
如果你只是想体验本地聊天、做总结、写提纲、跑简单工作流,那么从小模型开始完全够用;如果一上来就装 30B、70B 甚至更大的模型,失败概率和等待时间都会明显上升。
| 场景 | 建议 |
| 操作系统 | macOS、Windows、Linux 都支持。Windows 10+ 和 macOS 14+ 是官方明确写出的最低门槛。 |
| 磁盘空间 | Windows 文档写明安装本体至少需要 4GB,模型本身还会继续占用几十 GB 甚至更多。 |
| GPU 驱动 | Linux 走 NVIDIA 时需要先把 CUDA 驱动装好,并用 nvidia-smi 检查;AMD 路线看 ROCm。 |
| 网络 | 模型需要联网拉取;如果公司网络或地区网络受限,可能要配置 HTTPS_PROXY。 |
| 模型选择 | 第一次建议选 3B / 4B / 8B 这类更容易跑起来的版本;先追求“稳定能用”,再追求“更强”。 |
经验上,你可以这样理解:CPU 也能跑,但速度一般;内存越紧张,越要优先选小模型;上下文开得越大,资源占用也会继续上涨。本文里我会把“先跑通”放在第一位。
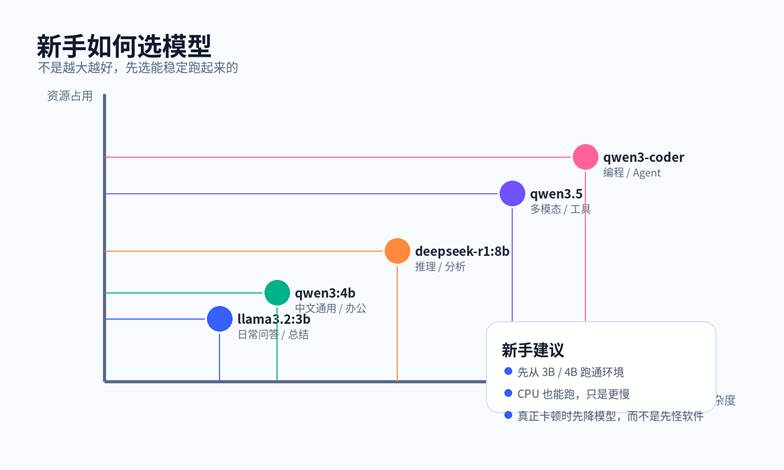
图 2:模型不是越大越好。新手先把中小模型跑稳,体验通常更好。
三、官方安装方式:Windows、macOS、Linux 分别怎么做
1. Windows:最适合纯新手
Windows 路线通常最省心。你可以直接下载官方安装包,也可以用 PowerShell 一键安装。官方文档还特别说明:默认安装不需要 Administrator,程序通常装在你的用户目录里。
| PowerShell 一键安装 irm https://ollama.com/install.ps1 | iex |
1. 双击安装包或执行上面的 PowerShell 命令完成安装。
2. 安装完成后,打开开始菜单或终端,输入 ollama。
3. 第一次建议直接执行 ollama run llama3.2:3b,让它自动拉模型并进入对话。
4. 若磁盘空间吃紧,稍后把 OLLAMA_MODELS 指向其他盘符。
2. macOS:命令行最简单
macOS 官方下载页写明需要 macOS 14 Sonoma 或更高版本。你既可以下载图形安装包,也可以直接在终端执行安装脚本。
| macOS / Linux 官方脚本 curl -fsSL https://ollama.com/install.sh | sh |
3. Linux:推荐把服务方式顺手配好
Linux 安装同样可以走官方脚本。官方 Linux 文档还给出了 systemd 服务方式,因此如果你打算把它当作长期驻留的本地模型服务,Linux 反而更适合。
• NVIDIA 用户先把 CUDA 驱动装好,再执行 nvidia-smi 检查是否识别成功。
• AMD 用户走 ROCm,官方文档当前写的是 ROCm v7。
• 需要长期运行时,可以按文档把 ollama 配成 systemd 服务。
四、安装后第一件事:先跑通第一个模型
很多新手装完之后马上去接插件、接编辑器,结果到底是模型没下好、服务没起来,还是接口没填对,自己也说不清。正确顺序应该是:先在终端里把“下载 → 运行 → 回复”这三步做通。
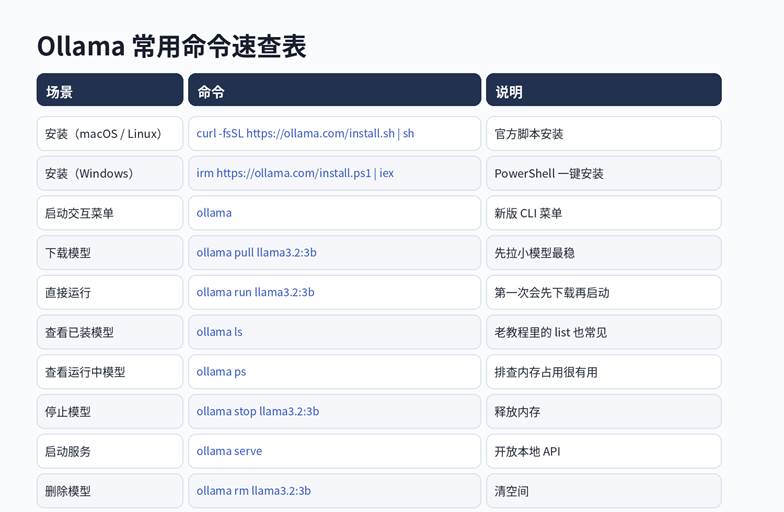
图 3:这些命令记住了,后面 80% 的使用场景都能覆盖。
| 第一次建议你至少做一遍的命令 # 直接运行一个轻量模型(第一次会自动下载) ollama run llama3.2:3b # 查看本地已经安装的模型 ollama ls # 查看正在运行的模型 ollama ps # 停止一个模型 ollama stop llama3.2:3b |
如果你想先体验中文办公场景,也可以换成 qwen3:4b 这类体量更友好的模型;如果你想试推理类回答,可以稍后再拉 deepseek-r1:8b。关键不是模型名单,而是先建立一个“我已经能在本机稳定对话”的基线。
五、模型怎么选:别被参数规模带偏
对于大多数第一次装 Ollama 的用户,模型选择可以按任务分,而不是按“谁最火”来分。
| 任务类型 | 推荐起步 | 为什么这么选 | 提醒 |
| 日常问答 / 总结 | llama3.2:3b | 轻量,适合先验证环境 | 先求稳定,不要急着追大参数 |
| 中文办公 / 写作 | qwen3:4b | 中文体验通常更友好 | 长文任务依旧建议分步提问 |
| 推理分析 | deepseek-r1:8b | 适合链式推理类场景 | 资源占用会更高 |
| 多模态 / 看图 | qwen3.5 或 llama3.2-vision | 可处理文本 + 图像输入 | 先确认工具链是否支持图像传入 |
| 编程 / Agent | qwen3-coder | 更适合代码与工具调用 | 别一上来装极大版本 |
一句话原则:新手第一次装的时候,不要想着“一步到位”,而要想着“低成本验证 + 逐步加码”。模型能稳定回答、速度还能接受,你就已经成功了。
六、本地 API 怎么调:用最简单的方式先打通
Ollama 本地 API 默认地址是 http://localhost:11434。官方文档说明,本地访问这个地址不需要额外认证;所以在你自己的电脑上调试,门槛是很低的。
| 最基础的 /api/chat 示例 curl http://localhost:11434/api/chat -d ‘{ “model”: “gemma3”, “messages”: [ { “role”: “user”, “content”: “你好,请用三句话解释一下 Ollama 是什么。” } ] }’ |
如果你更喜欢一次性给 prompt,也可以用 /api/generate;如果你要做向量检索或知识库,可以看 /api/embed;如果你原来已经有基于 OpenAI 或 Anthropic 的应用,最新版文档还给了兼容层,迁移成本会更低。
| 当你已有 OpenAI 风格调用代码时,可以考虑兼容接口 # OpenAI 兼容接口(示意) curl http://localhost:11434/v1/responses -d ‘{ “model”: “llama3.2:3b”, “input”: “请把这段话总结成三点。” }’ |
七、进阶一点:Modelfile、自定义模型和本地导入
当你不满足于“直接拉官方库里的现成模型”时,Ollama 的 Modelfile 就会派上用场。它可以理解成一个“模型蓝图文件”:你可以在里面指定基础模型、系统提示词、参数,甚至从本地 GGUF 文件或 Safetensors 权重构建新模型。
| 一个适合办公助手的 Modelfile 示例 FROM llama3.2 SYSTEM “””你是一个中文办公助手,回答要求: 1. 先给结论 2. 再给执行步骤 3. 尽量少说空话 “”” PARAMETER temperature 0.3 PARAMETER num_ctx 4096 |
| 创建并运行自定义模型 # 根据 Modelfile 创建新模型 ollama create office-helper -f Modelfile # 运行它 ollama run office-helper |
如果你手里已经有 GGUF 文件,文档也给出了 FROM ./xxx.gguf 的写法;如果你拿的是一套 Safetensors 权重,则可以直接把权重目录作为 FROM 目标。对于想把 Hugging Face 上的模型资产接入本地工作流的人来说,这一步很关键。
八、第三方工具怎么接:思路比死记命令更重要
你可以把 Ollama 看成一个“本地模型后端”。前端可以是终端,可以是编辑器插件,也可以是你自己写的应用。关键不是记住某个插件的设置页面,而是理解:大多数接入都绕不开“模型名 + 本地地址 + 接口格式”。
• 如果工具支持 OpenAI 风格接口,优先尝试填本地 base URL 到 http://localhost:11434。
• 如果工具支持 Anthropic Messages API,也可以按官方文档设置 ANTHROPIC_BASE_URL=http://localhost:11434。
• 如果是 VS Code、Claude Code、Codex 等工具,最新版 CLI 还提供了 ollama launch 的交互式配置入口。
也就是说,你不一定要先学会写代码。很多时候,先让工具连上 Ollama,再慢慢调整模型与参数,已经足够你完成一套本地工作流。
九、模型目录迁移、代理、服务常驻:真正开始长期使用后的三个高频问题
当你第一次把 Ollama 真的用起来之后,最常遇到的不是“不会安装”,而是下面三类问题:模型把系统盘塞满了、网络环境导致下载卡住、以及想让服务长期在线却老是忘记启动。
| 问题 | 怎么做 | 为什么 |
| 系统盘空间不够 | 设置 OLLAMA_MODELS 到其他目录 | 模型通常比程序本体更占空间 |
| 下载慢或下载失败 | 优先检查 HTTPS_PROXY 与网络环境 | 模型拉取依赖外网连接 |
| 希望开机即用 | Linux 可配置 systemd;其他系统可做自启动 | 避免每次手动开服务 |
官方 FAQ 里还给出了默认模型目录位置:macOS 在 ~/.ollama/models,Linux 在 /usr/share/ollama/.ollama/models,Windows 在 C:\Users\%username%\.ollama\models。知道这个位置之后,你就知道空间到底被谁吃掉了。
十、常见报错怎么排:把排查顺序固定下来
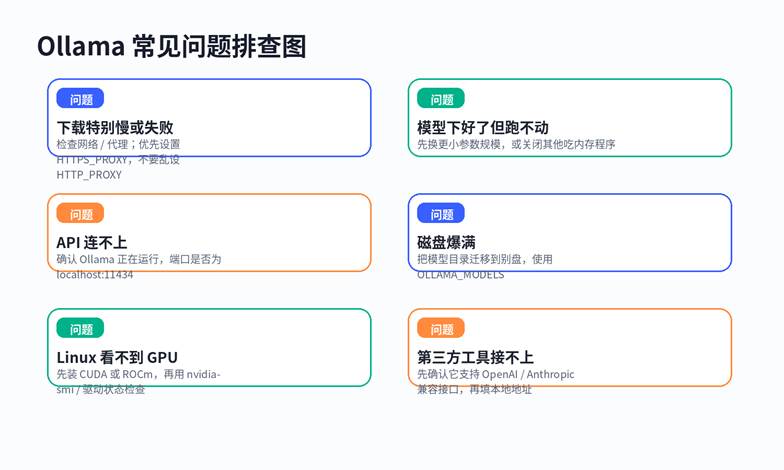
图 4:遇到问题时,别乱试配置,按“网络 → 模型大小 → 服务状态 → 路径”顺序排查。
1. 先确认 Ollama 是否已经在运行:终端执行 ollama 或 ollama serve,别先怀疑插件。
2. 再确认模型有没有真的下好:执行 ollama ls 看本地清单。
3. 如果回答特别慢或直接卡死,优先换更小模型,而不是立刻换系统。
4. API 连不上时,先确认地址是不是 localhost:11434,而不是瞎填别的端口。
5. 磁盘空间不够时,优先迁移 OLLAMA_MODELS,不建议反复删装程序。
6. Linux 想用 GPU 时,先看驱动和 nvidia-smi / ROCm 状态,再看 Ollama 本身。
十一、给新手的一套推荐落地流程
| 如果你只想今天就把 Ollama 用起来,按下面这个最省事 • 第 1 步:用官方安装方式把 Ollama 装好。 • 第 2 步:执行 ollama run llama3.2:3b,等模型下载完成。 • 第 3 步:问它一个简单问题,确认能稳定回答。 • 第 4 步:执行 ollama ls 和 ollama ps,学会看本地模型与运行状态。 • 第 5 步:用 curl 试一次 /api/chat,确认本地 API 打通。 • 第 6 步:再去接 IDE、知识库、自动化工具,而不是反过来。 |
这套顺序的好处在于,你每做一步都能验证上一层有没有成功。对新手来说,能够“分层确认”比一次把所有插件全装上更重要。
FAQ:
| 问题 | 建议回答 |
| Ollama 支持哪些系统? | 支持 macOS、Windows 和 Linux。新手通常优先选 Windows 或 macOS 图形化安装,Linux 更适合长期作为本地模型服务运行。 |
| Ollama 本地部署需要联网吗? | 安装后本地运行可以离线,但第一次下载模型通常需要联网;如果网络受限,可能需要设置 HTTPS_PROXY。 |
| Ollama 可以在没有 GPU 的电脑上运行吗? | 可以,CPU 也能运行,只是速度通常会更慢。新手建议先从 3B / 4B 级别的小模型开始。 |
| Ollama 的模型存在哪里? | 默认会放在本地模型目录中;如果系统盘空间不够,可以通过 OLLAMA_MODELS 迁移到其他目录。 |
| Ollama 可以接现有应用吗? | 可以。它提供本地 API,也提供 OpenAI / Anthropic 兼容层,适合接编辑器插件、自动化工具和自建应用。 |
十二、结语:Ollama 值不值得学
如果你想要的是“把大模型装在自己电脑上,能离线、可控、能接应用、还能逐步扩展”,那 Ollama 非常值得学。它不是唯一方案,但确实是当前最适合新手迈出第一步的方案之一。
你不需要第一天就懂所有参数、所有模型、所有插件。先装好、先跑通、先问出第一轮回答,然后再慢慢接工具、调提示词、做工作流,这才是最稳的学习路径。
附录:官方资料与建议继续阅读
• Quickstart:docs.ollama.com/quickstart
• CLI Reference:docs.ollama.com/cli
• Windows:docs.ollama.com/windows
• Linux:docs.ollama.com/linux
• FAQ:docs.ollama.com/faq
• API / chat:docs.ollama.com/api/chat
• OpenAI compatibility:docs.ollama.com/api/openai-compatibility
• Modelfile:docs.ollama.com/modelfile
• 模型库:ollama.com/library
