

Ollama 教程:在个人笔记本上像运行软件一样运行开源大模型
从下载安装到模型选择、命令实战、API 调用与常见问题,一次讲清本地大模型上手路径
| 适用人群 零基础新手 / 开发者 / 内容创作者 | 阅读收获 装好 Ollama、跑通模型、会用命令和 API | 推荐系统 Windows / macOS / Linux |
| 文章类型 保姆级教程 | 推荐分类 安装部署教程;使用技巧教程 | 更新口径 基于 2026 年 4 月官方公开资料 |
| 一句话理解 Ollama 的本质,是把开源大模型做成一套“可安装、可运行、可调用、可集成”的本地运行时。 |
导读
如果你把大模型理解成一种“会思考的软件”,那么 Ollama 做的事情,就是把这些模型变成像普通应用一样可下载安装、可运行、可更新、可通过命令行或 API 调用的本地服务。
它最吸引个人用户的地方,不是炫技,而是门槛低:安装完成后,你可以直接用 `ollama run 模型名` 开始对话,也可以让编辑器、脚本、笔记工具、Agent 工具直接连接到本地模型。
对于想在个人笔记本上体验开源大模型的人来说,Ollama 是目前最顺手的入口之一。
一、Ollama 是什么,为什么它适合个人笔记本
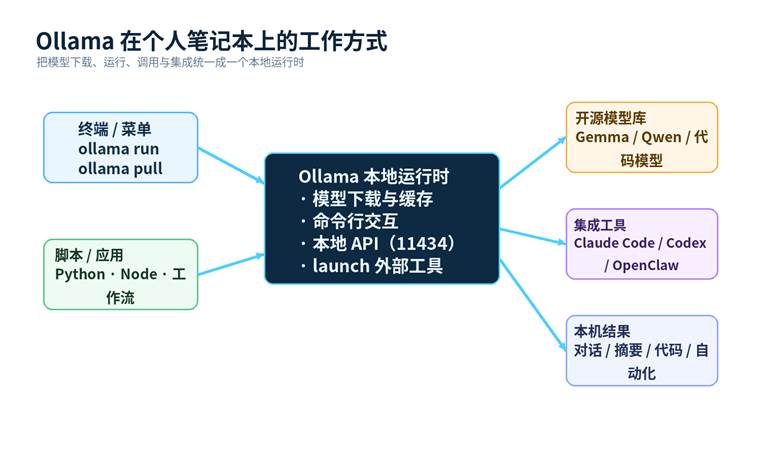
图 1 Ollama 在个人笔记本上的工作方式
Ollama 是一个本地模型运行时与分发平台。它把模型下载、量化封装、运行服务、命令行交互、HTTP API 暴露整合到了一起,让用户不必手动折腾复杂推理框架,也不需要从零搭建一套推理环境。
对新手来说,Ollama 的价值主要体现在四点:第一,安装路径清晰,支持 macOS、Windows、Linux;第二,命令足够简单,`pull / run / ps / list / rm` 基本就能完成日常操作;第三,模型生态丰富,文本、视觉、代码、Embedding、部分云模型都能统一管理;第四,它天然适合作为本地 AI 的“中间层”,可以被脚本、IDE 和 Agent 工具复用。
简单理解:如果 Hugging Face 更像模型仓库,llama.cpp 更像底层推理引擎,那么 Ollama 更像一层面向普通用户的本地运行平台。
二、上手前先看:你的笔记本需要准备什么

图 2 不同笔记本的模型选择建议
先记住一个核心原则:本地运行大模型时,决定体验的关键通常不是 CPU,而是可用内存 / 显存、磁盘空间以及你选择的模型大小。
官方文档显示,Ollama 现已支持 macOS、Windows 和 Linux。Windows 需要 Windows 10 22H2 或更新版本;macOS 需要 Sonoma 14 或更新版本,其中 Apple M 系列支持 GPU 加速,Intel Mac 则主要是 CPU 路线;Linux 则支持 CPU、NVIDIA、AMD ROCm 等路线。
磁盘空间也经常被低估。Windows 官方说明里提到,安装二进制本体至少需要约 4GB 空间,而模型文件本身往往还要再占用数 GB 到数十 GB。轻薄本如果系统盘空间本来就紧张,建议一开始就把模型目录迁到大容量磁盘。
三、安装 Ollama:Windows、Mac、Linux 三条路线
Windows:下载安装包后即可安装,默认以本机原生应用运行。安装后 Ollama 会在后台运行,并在本地暴露 `http://localhost:11434` API。若系统盘空间不足,可通过 `OLLAMA_MODELS` 环境变量修改模型存放位置。
macOS:推荐方式是挂载 `ollama.dmg` 后拖入 Applications。首次启动时,Ollama 会检查命令行工具是否已加入 PATH;若未检测到,会提示创建到 `/usr/local/bin` 的链接。Apple Silicon 机器可直接使用 Metal GPU 加速,无需额外安装 CUDA。
Linux:最省事的方式是执行官方安装脚本 `curl -fsSL https://ollama.com/install.sh | sh`。需要长期运行时,推荐配置成 systemd 服务,并按硬件情况补齐 NVIDIA CUDA 驱动或 AMD ROCm 驱动。
| 安装建议 新手优先使用官方安装包或官方脚本,不建议一开始就追求源码编译。 |
• Windows:安装后默认以原生应用运行;若系统盘吃紧,尽早设置 `OLLAMA_MODELS` 改模型目录。
• macOS:Apple Silicon 直接走 Metal;Intel Mac 更适合轻量模型与 CPU 路线。
• Linux:长期运行建议配 systemd 服务;如需 GPU,加装对应驱动后再验证。
| curl -fsSL https://ollama.com/install.sh | sh ollama -v |
四、第一次运行:3 分钟完成你的第一轮本地对话

图 3 从安装到本地对话的最小闭环
安装完成后,最简单的入门方式是直接在终端输入 `ollama` 打开交互菜单,或用 `ollama run 模型名` 直接启动一个模型。
例如,你可以先试体量较小、适合笔记本的模型,如 `gemma3:4b`、`qwen3.5:4b`,或者对代码场景更友好的 `qwen3-coder` 系列。第一次运行时,Ollama 会自动下载模型;第二次再运行时,速度会明显快很多。
建议你的第一轮体验按这套顺序来:`ollama pull 模型名` → `ollama run 模型名` → 输入问题测试 → `ollama ps` 查看驻留模型 → `ollama stop 模型名` 释放资源。这样你会很快建立起对“下载、运行、查看、停止”的完整心智模型。
| ollama pull gemma3:4b ollama run gemma3:4b ollama ps ollama stop gemma3:4b |
五、笔记本怎么选模型:不要一上来就追 70B
本地模型的实际体验,通常遵循“模型越大,质量越高,但对资源越苛刻”的规律。对于个人笔记本,最重要的不是盲目追大,而是找到你机器能长期稳定运行的甜蜜点。
如果你是 16GB 内存轻薄本,优先从 3B~4B 级别开始;如果是 24GB~32GB 内存或带独显的高配本,可以尝试 7B、9B、12B;再往上的 27B、30B、70B,大多数情况下更适合台式机、工作站,或者改用 Ollama 的 cloud 变体。
一个非常实用的策略是:聊天与总结用轻量模型,代码与长上下文任务用中等模型,只有在确实需要更高质量时才尝试更大体量。对大多数人来说,持续可用比偶尔跑通更重要。
| 机器类型 | 建议模型档位 | 适合任务 | 建议 |
| 轻薄本 / 16GB 内存 | 1B~4B | 日常问答、摘要、简单写作 | 优先速度与稳定性,不要一上来拉 14B+ |
| 主流本 / 24GB~32GB | 4B~9B | 进阶写作、代码辅助、较长上下文 | 适合长期主力使用 |
| 高配本 / 独显 + 较大内存 | 9B~14B | 更高质量对话、复杂推理、代码任务 | 注意磁盘空间与散热 |
| 更大模型需求 | 27B、30B、70B 或 cloud 版本 | 高质量推理、复杂 Agent 场景 | 优先台式机或云端混合路线 |
六、最常用的 Ollama 命令,一张清单就够
`ollama run`:运行模型并进入交互;`ollama pull`:预先拉取模型;`ollama list`:查看已下载模型;`ollama ps`:查看当前正在运行的模型;`ollama rm`:删除模型;`ollama stop`:停止指定模型;`ollama launch`:交互式配置并启动外部集成工具。
2026 年的 Ollama 已经不只是“本地聊天壳”。官方 CLI 还加入了 `ollama launch`,可以更方便地把 Claude Code、Codex、OpenCode、VS Code 等工具挂到 Ollama 模型上。对开发者而言,这意味着本地模型不再只是单独聊天,而是开始进入实际工作流。
如果你平时会写脚本或搭自动化工作流,记住一条就够:只要 Ollama 服务在本机跑起来了,它就是一个标准的本地 AI 接口层。
| 命令 | 作用 | 示例 |
| ollama | 打开交互菜单 | ollama |
| ollama pull | 拉取模型 | ollama pull gemma3:4b |
| ollama run | 运行模型 | ollama run qwen3.5:4b |
| ollama list | 查看已下载模型 | ollama list |
| ollama ps | 查看当前运行模型 | ollama ps |
| ollama stop | 停止指定模型 | ollama stop gemma3:4b |
| ollama rm | 删除模型 | ollama rm qwen3.5:4b |
| ollama launch | 启动外部集成 | ollama launch claude –model qwen3.5 |
| curl http://localhost:11434/api/chat -d ‘{ “model”: “gemma3”, “messages”: [{“role”: “user”, “content”: “你好,帮我写一个产品简介。”}] }’ |
七、API 与自动化:把本地模型接进你的脚本和工具
Ollama 安装完成后,默认会在 `http://localhost:11434/api` 暴露接口。官方文档给出的最基础示例,是通过 `generate` 或 `chat` 接口向本地模型发送请求。
这意味着你可以很方便地把它接进 Python、Node.js、自动化脚本、知识库工具,甚至接到你自己的桌面工作流里。对于内容创作者,它可以用来做本地改写、提纲整理、摘要;对于开发者,它可以做本地代码解释、接口说明、测试样例生成;对于研究型用户,它可以做离线整理和隐私敏感文本处理。
如果你想更进一步,还可以通过 Modelfile 来导入或封装自定义模型,例如从 Safetensors 或 GGUF 导入权重,或者把你常用的 system prompt 固化成自己的模型别名。
| 进阶方向 先把 Ollama 当成“本机 AI API”使用,再去接 IDE、知识库、自动化平台,学习曲线会更平滑。 |
| FROM /path/to/your-model.gguf SYSTEM 你是一个擅长整理技术笔记的中文助手 PARAMETER temperature 0.3 |
八、常见坑位与排错建议
第一类问题是“模型能下载,但跑起来很慢”。这通常不是 Ollama 本身坏了,而是模型选得过大,或者当前实际走的是 CPU 路线。先用更小模型验证,再检查系统是否真的识别到了 GPU。
第二类问题是“磁盘空间越用越少”。这是因为模型文件默认会缓存在用户目录下。Windows 可通过 `OLLAMA_MODELS` 调整模型路径,macOS 和 Linux 也应尽量把模型目录规划到大容量磁盘。
第三类问题是“终端显示乱码或方块”。Windows 官方文档特别提到,旧终端字体对 Unicode 进度条支持较差,必要时可更换终端字体。
第四类问题是“Linux 下 GPU 没被识别”。官方 Troubleshooting 建议优先检查驱动版本、`nvidia-smi` 是否正常、容器运行时是否具备 GPU 权限,以及是否需要重新加载 `nvidia_uvm` 模块。
• 先验证小模型能否正常跑通,再尝试更大模型。
• 检查磁盘空间和模型缓存目录,别让系统盘被模型吃满。
• Linux/NVIDIA 路线先跑 `nvidia-smi`,再检查 Ollama 日志。
• 需要更大上下文时,可通过环境变量或参数单独调整,而不是盲目换更大模型。
九、适合哪些人,谁又不该从 Ollama 开始
如果你希望离线运行、希望数据尽量留在本机、希望把开源模型接进个人工具链,或者想用最低成本理解“本地大模型到底怎么跑起来”,那么 Ollama 非常值得作为入门第一站。
但如果你的目标是:立刻获得最强推理质量、稳定跑超长上下文、处理海量多模态任务,或者你完全不想碰命令行,那么单靠个人笔记本上的本地模型,未必是最高效的起点。这时更现实的策略,往往是“本地小模型 + 云端大模型”混合使用。
把 Ollama 用对的方法不是把所有模型都塞进笔记本,而是把它当成本地 AI 底座:让你的电脑先拥有一个真正可调用、可集成、可复用的模型运行环境。
FAQ|常见问题
| Q:Ollama 一定要独显才能用吗? A:不一定。Apple Silicon 可以直接用 Metal,加速体验通常不错;没有独显的机器也能跑,只是更适合 1B~4B 这类轻量模型,速度和并发能力会受限。 |
| Q:Windows 上安装需要管理员权限吗? A:官方文档说明 Windows 安装默认不要求 Administrator,并且默认安装到用户主目录;但如果你要改安装目录、配置驱动或修改系统级环境变量,可能仍需要管理员操作。 |
| Q:Ollama 和 LM Studio 有什么区别? A:两者都能本地跑模型,但 Ollama 更偏“运行时 + CLI/API + 集成层”,更适合脚本、开发和自动化;LM Studio 更偏图形化体验。 |
| Q:为什么我第一次运行特别慢? A:第一次需要下载模型,且首次加载会初始化权重;之后再次运行通常会快很多。若一直很慢,优先检查模型大小是否超出机器承载范围。 |
| Q:能不能导入我自己下载的 GGUF 或微调模型? A:可以。官方文档提供了通过 Modelfile 从 Safetensors、适配器或 GGUF 导入模型的方法。 |
相关阅读
• 本地部署入门:手把手带你下载 Stable Diffusion WebUI 整合包
• 小白必看:如何在 Windows / Mac 上配置 Python 与 GPU 加速环境
• OpenClaw 是什么?为什么 2026 年大家都在聊 AI Agent“龙虾”生态
参考资料
• Ollama Quickstart:https://docs.ollama.com/quickstart
• Ollama Windows:https://docs.ollama.com/windows
• Ollama macOS:https://docs.ollama.com/macos
• Ollama Linux:https://docs.ollama.com/linux
• Ollama CLI Reference:https://docs.ollama.com/cli
• Ollama API Introduction:https://docs.ollama.com/api/introduction
• Ollama Hardware support:https://docs.ollama.com/gpu
• Ollama FAQ:https://docs.ollama.com/faq
• Ollama Model Library:https://ollama.com/library?sort=newest
