

Make + GPT-4o:自动处理邮件询盘并录入企业 CRM 系统
从收件箱到 CRM 的零代码自动化实战指南
| 文章定位 | 一篇讲透 Make + 邮件询盘 + CRM 落地链路的保姆级教程 | 适合人群 | 销售运营、客服负责人、自动化工程师、企业数字化负责人 |
| 推荐分类 | 实战工作流 > 自动化工作流 | 阅读收益 | 看懂流程、抄走 Prompt、按步骤搭出可上线 MVP |
| 先说结论: 对大多数企业来说,最值得自动化的不是“自动回邮件”本身,而是“自动理解询盘 + 自动建档 + 自动分配 + 自动生成草稿”。AI 负责理解,规则层负责控制,CRM 负责沉淀,这样最稳。 |
一、为什么“邮件询盘自动化”值得优先做
很多企业已经把表单、广告线索、官网咨询接进了 CRM,但真正成交概率更高的询盘,往往还躺在销售或客服的邮箱里。一个典型问题是:邮件进来了,却没有人第一时间提炼关键信息,导致联系人没有建档、客户需求没有标签、商机没有及时转给对应负责人。
这件事特别适合用 Make 做自动化中枢。因为它天然擅长把触发器、过滤器、Router、数据存储、HTTP/API 调用和第三方 SaaS 串起来。再把 GPT 模型接上,就能把“非结构化邮件”转换成“可入库字段”,让 CRM 真正开始工作。
你可以把整条链路理解成 3 层:第一层是收件层,负责拿到邮件;第二层是理解层,负责判断这是不是有效询盘、客户在问什么、优先级有多高;第三层是执行层,负责写入 CRM、提醒销售、生成回复草稿。真正让人省时间的是后两层。
二、这条自动化链路到底怎么跑
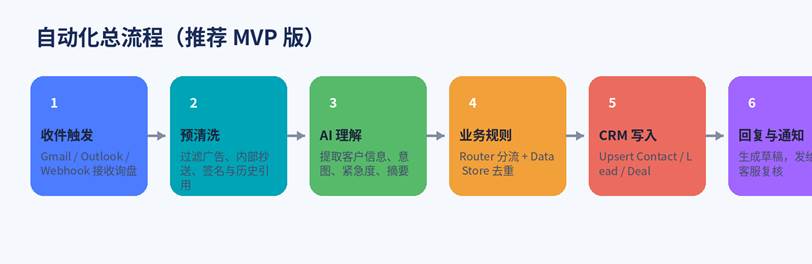
图 1 推荐的 MVP 流程:先做“理解 + 建档 + 分发”,再逐步增加自动回复与复杂规则。
最稳妥的做法,不是一步到位做成“收到邮件就自动给客户发回信”,而是先把自动化目标定为:自动读取邮件、抽取字段、判断是不是有效询盘、进入 CRM 并生成建议动作。这样既能立刻提升效率,又能避免误判直接触发对外沟通。
如果你的线索来源很多,也可以把入口统一改成 Webhook。官网表单、客服系统、广告表单、活动报名都能先打到 Make,再走同一套理解与入库流程。对于企业内部协同,统一入口比到处复制规则更容易维护。
推荐的 6 个核心模块
• 触发模块:Gmail / Outlook 监听新邮件,或自定义 Webhook 接收来自官网/表单系统的数据。
• 预处理模块:删除签名、历史引用、退订信息、系统通知等噪音,避免模型把无关内容当客户需求。
• AI 模块:让 GPT 按固定 JSON 结构输出联系人、公司、需求、紧急度、意向等级、摘要、建议动作。
• 规则模块:用 Router 做分流,比如“高意向直接通知销售”“低价值先入池”“缺手机号则标记待补充”。
• 去重模块:用 Data Store 或 CRM 自带查询,按邮箱、手机号、公司名做查重与 upsert。
• 执行模块:把数据写入 CRM,同时生成内部通知,必要时再生成客户回复草稿。
三、上线前要准备什么
• 一套能稳定收到询盘的邮箱或入口。最常见的是销售邮箱、客服邮箱、官网线索收件箱,或者统一的线索别名邮箱。
• 一个明确的 CRM 字段模型。最少要想清楚:联系人、公司、线索来源、需求摘要、优先级、负责人、下次动作。这一步越清晰,后面越不容易返工。
• 一个清楚的业务规则清单。例如:哪些邮件算有效询盘;哪些要自动分给华东区销售;哪些行业属于重点客户;哪些关键词代表高优先级。
• 一个 AI 输出格式规范。不要只让模型“总结邮件”,而要让它按字段输出 JSON;不要只让它“判断客户意向”,而要让它在有限选项里分类。
| 2026 更新提醒: 如果你照着本文新建生产环境,不要死盯着旧的 chatgpt-4o-latest 快照。OpenAI 官方已将该快照在 2026-02-17 移除,建议把“GPT-4o 工作流思路”理解为一类高质量邮件理解范式,实际接入时使用当前可用的 OpenAI 最新聊天模型或 Make 的等价 AI Provider 模型。 |
四、在 Make 里手把手搭建一条可上线的场景
步骤 1:设置触发器
最简单的是 Gmail 的 Watch emails 或 Outlook 的对应模块。建议单独建一个标签,例如“leads”或“inquiry”,只监听这个标签下的新邮件,避免把所有日常沟通都扔进 AI。若你的线索来自官网表单或其他系统,则改用 Custom Webhook,统一把数据推给 Make。
步骤 2:先做预清洗,而不是一上来就喂给模型
真实邮件常带着签名、免责声明、历史引用、自动转发痕迹。如果不先清洗,模型会把“公司地址”“免责声明”误判为客户需求。你可以用文本函数、正则或简单代码节点截断“From:”“Sent:”后面的历史回复,并过滤含有退订、newsletter、no-reply 等特征的非询盘邮件。
步骤 3:让 AI 输出结构化 JSON
这是整条链路成败的关键。与其问“帮我总结这封邮件”,不如要求模型输出固定字段:contact_name、company、email、phone、interest_product、intent_level、urgency、summary、next_action、should_create_crm、draft_reply_outline。字段越稳定,后续映射越轻松。
步骤 4:用 Router 做业务分流
建议至少分 3 条路:高优先级询盘、普通询盘、无效/噪音邮件。高优先级可直接通知销售负责人;普通询盘进入 CRM 并生成待跟进任务;无效邮件则记录日志但不进主漏斗。这样能把 AI 的判断和业务动作拆开,方便运营团队调权重。
步骤 5:查重并写入 CRM
查重是企业流程里最容易被忽略的一步。建议先按邮箱查 CRM 中是否已有联系人,再按公司名或手机号补一层模糊判断。没有则创建,有则更新;如果 CRM 支持 upsert,就尽量使用 upsert。以 HubSpot 为例,联系人接口本身就是为了管理联系人数据并与其他系统同步。
步骤 6:生成邮件草稿,而不是默认自动发送
对大多数 B2B 场景,我更推荐“AI 生成草稿 + 销售一键确认”。这样既保留速度,也不会在语气、报价、政策承诺上出问题。只有在 FAQ、高频、低风险场景下,才适合把自动发送打开。
可直接复用的 Prompt 模板
你是企业销售询盘分拣助手。请阅读输入邮件,并严格输出 JSON。
要求:
1) 只根据邮件里明确出现的信息判断,不要编造。
2) intent_level 仅允许:high / medium / low / invalid
3) urgency 仅允许:urgent / normal / low / unknown
4) should_create_crm 仅允许 true / false
5) next_action 仅允许:assign_sales / nurture / ask_more_info / ignore
输出字段:
{
“contact_name”: “”,
“company”: “”,
“email”: “”,
“phone”: “”,
“country_or_region”: “”,
“interest_product”: “”,
“intent_level”: “”,
“urgency”: “”,
“summary”: “”,
“pain_point”: “”,
“should_create_crm”: true,
“next_action”: “”,
“owner_hint”: “”,
“draft_reply_outline”: “”
}
字段映射建议
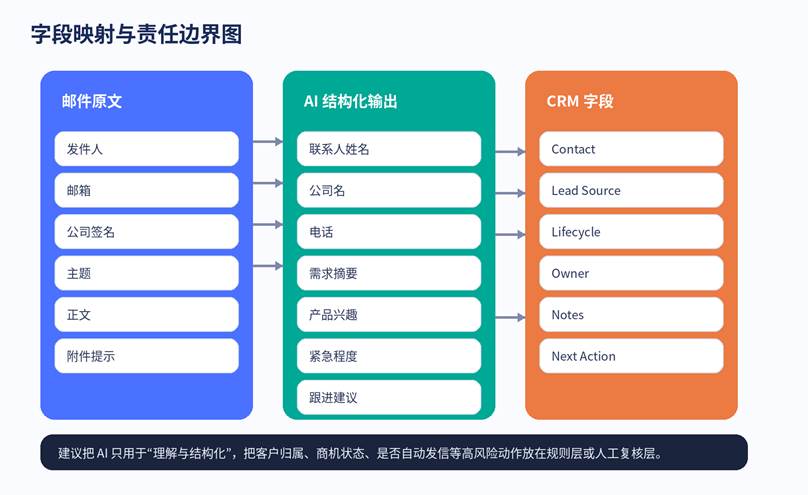
图 2 不要让 AI 直接决定所有业务动作。更稳的做法是:AI 负责抽取与判断,规则层负责审批与分发。
| 邮件信息 | AI 输出字段 | CRM 对应字段 | 说明 |
| From Name | contact_name | Contact Name | 联系人姓名;没有就留空,不要猜 |
| From Email | 优先做唯一键或主去重键 | ||
| 签名公司名 | company | Company | 有时正文不写公司,签名里反而更稳定 |
| 正文需求 | summary / pain_point | Notes / Description | 建议保留原始摘要,别只保留标签 |
| 产品关键词 | interest_product | Interest / Product | 便于后续自动分配给产品线 |
| 语气与时间词 | urgency | Priority | 如 ASAP、this week、RFQ 等 |
| 综合判断 | intent_level | Lead Score / Lifecycle | 不要直接映射成交概率,可先映射为线索等级 |
| 规则建议 | next_action | Task / Owner / Status | 比如 assign_sales、ask_more_info |
五、企业 CRM 接入时,最常见的 4 个坑
• 把 AI 当审批器用。模型可以给建议,但别让它单独决定“是否自动发报价”“是否自动建商机”。高风险动作一定要有规则层或人工确认。
• 字段模型没定义好就开始搭场景。结果是今天写 notes,明天又拆成 summary、pain_point、product_interest,越改越乱。
• 只做创建,不做更新。真实业务里联系人会多次来信,CRM 必须支持补写、覆盖和历史沉淀,不然只会制造重复记录。
• 没有失败兜底。HTTP 调用失败、CRM 限流、邮箱格式异常、模型输出 JSON 不合法,都应该落日志并通知运营,而不是悄悄失败。
六、成本、稳定性与合规,怎么一起兼顾
成本控制最有效的方式,不是抠模型价格,而是减少无效调用。先用过滤器挡掉系统通知、自动回复、垃圾邮件,再把真正的询盘送进 AI。你还可以在预处理阶段把附件说明、冗余引文裁掉,减少输入 token。
稳定性控制的关键是“分阶段上线”。第一阶段只做建档和通知;第二阶段加入草稿;第三阶段再根据业务成熟度决定是否自动发信。每上一层自动化,都要回头看误判率。
合规控制的关键是最小必要原则。不要把全部邮箱历史无条件送进模型;不要把不需要的身份证、地址、敏感价格条款长期存进 Data Store;不要让 CRM 里堆满 AI 猜测字段。企业真正需要的是可追溯、可审计、可关闭的自动化流程。
推荐的上线节奏
• 第 1 周:只做监听 + AI 提取 + 飞书/Slack/邮件通知,不写 CRM。
• 第 2 周:加入 CRM 创建与去重,开始积累真实字段质量。
• 第 3 周:加入负责人分配、优先级、下一步动作建议。
• 第 4 周:对高频低风险场景尝试“自动草稿”,保留人工确认。
七、一个最容易落地的 MVP 方案
如果你是第一次做,我建议直接采用下面这个最简版本:Gmail Watch Emails -> 文本清洗 -> OpenAI 结构化输出 -> Router -> Data Store 查重 -> HubSpot/CRM Upsert -> 给销售发送内部通知。整条链路不超过 8 个模块,维护成本低,出了问题也好排查。
这套方案的本质,不是为了炫技,而是为了把“过去靠人手抄、靠经验判断”的工作,变成一个稳定的数字化入口。只要 CRM 里开始有结构化数据,你后面就能继续做自动打标签、自动归属、自动商机评分、自动复盘。
FAQ
1. 这套方案适合 B2B 还是 B2C?
两者都能用,但 B2B 更适合先做,因为邮件里通常会包含更完整的公司、需求和项目背景,结构化价值更高。
2. 一定要用 GPT-4o 吗?
不一定。本文用“GPT-4o”主要是因为大家熟悉这一类高质量邮件理解模型。2026 年实际接入时,你应以 OpenAI 当前可用模型和 Make 的官方支持情况为准。
3. CRM 一定要用 HubSpot 吗?
不一定。HubSpot 只是最容易讲清楚的示例。Salesforce、Zoho、纷享销客、销售易,甚至自建 CRM,都可以通过原生模块或 HTTP API 接入。
4. 自动回复会不会有风险?
会。尤其涉及价格、交期、政策承诺、法务条款时,建议只生成草稿。把“自动发信”放在流程成熟后再评估。
5. Data Store 的作用是什么?
它适合存去重键、暂存状态、幂等标识和小体量业务记录。不要把它当长期主数据库,而要把它当 Make 工作流里的轻量状态层。
6. 如果模型输出不是合法 JSON 怎么办?
给输出加严格结构约束;如果仍失败,就让场景进入错误分支,记录原文并通知运营人工处理。
相关阅读
• 《提示词工程(Prompt Engineering):让 AI 听懂人话的 5 个万能模板》
• 《Gamma 进阶:如何用 AI 在 3 分钟内完成一份融资计划 PPT》
• 《Coze(扣子)实战:从零搭建一个自动抓取热点的微信订阅机器人》
| 最后一句话: 邮件询盘自动化最怕两个极端——要么全靠人手,要么一上来就“全自动回复”。真正靠谱的路线,是让 Make 负责编排,让 AI 负责理解,让 CRM 负责沉淀,让关键动作始终可控。 |
