

本地部署时报错怎么办,常见问题排查全集
适用于 Ollama、ComfyUI、Stable Diffusion、Docker、WSL 等本地 AI 环境
| 文章摘要 这不是一篇只告诉你“重装试试”的排错文,而是一份按症状、按层级、按动作拆开的本地部署问题手册。你会先学会如何判断错误属于系统层、运行时层、硬件层、模型层还是网络与权限层,再对照最常见的报错类型逐步定位:Python 与 pip 找不到、依赖冲突、Torch 没有启用 CUDA、CUDA 版本不匹配、显存或内存不足、模型文件缺失、端口被占用、WSL / Docker 失灵、代理与证书问题、插件或自定义节点冲突等。 |
更新日期:2026-03-28
为什么本地部署一出问题,很多人会越修越乱?
本地 AI 环境的报错之所以让人头大,不是因为报错特别“高级”,而是因为问题经常跨层:你看到的是模型加载失败,真正原因可能是显卡驱动、PyTorch 构建、路径权限,甚至只是旧进程没退出。如果上来就同时升级驱动、重装 Python、换模型、删插件,最后通常只会把环境越改越乱。
• 本教程的核心目标不是让你背报错,而是让你建立一套稳定的排错顺序。
• 你会先学会“分层定位”,再用“最小复现 + 日志 + 单变量修改”去缩小范围。
• 只要顺序对了,大多数本地部署问题都能在 10–30 分钟内定位到根因。

图 1 先判断错误属于哪一层,再决定用什么方式排查
部署前先做 8 项快速检查
很多“玄学错误”其实可以在部署前避免。尤其是新机器、新系统、刚升级驱动、刚换 Python 版本时,更要先做预检查。
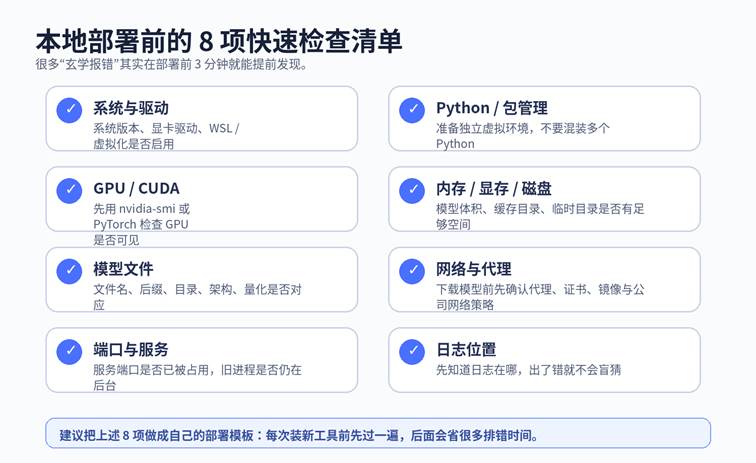
图 2 部署前的快速检查清单
| 部署前最容易忽略的 3 件事 ① 不要把多个 Python、多个 CUDA、多个包管理器混在同一个项目里。② 不要在没确认端口、日志、模型目录前就开始“瞎点”。③ 出现问题时,先记下你最后一次改动了什么。 |
通用排错流程:先定位,再修复
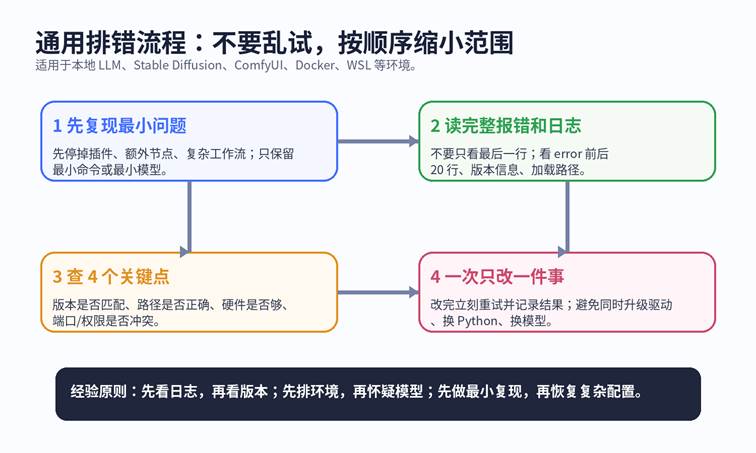
图 3 适用于大多数本地 AI 环境的排错顺序
• 第一步:先做最小复现。把插件、复杂工作流、大模型都先拿掉,只保留最小命令。
• 第二步:看完整日志。不要只盯最后一行,很多真正的原因在前面。
• 第三步:查四个关键点:版本、路径、硬件、端口/权限。
• 第四步:一次只改一件事。否则你无法判断到底是哪一个动作起了作用。
你应该优先看的几个命令
| 检查目标 | 命令 / 动作 | 你要看什么 |
| Python | python –version / where python | 是否真的是当前项目在用的那个 Python |
| pip | pip –version / pip list | pip 指向的环境是否和 python 一致 |
| Torch | python -c “import torch; print(torch.__version__, torch.cuda.is_available())” | 是否装对版本、能否看到 GPU |
| GPU | nvidia-smi | 驱动、显卡、显存是否正常显示 |
| WSL | wsl -l -v / wsl –update | 是不是 WSL 2、组件是否是最新 |
| Docker | docker ps / docker logs <容器名> | 服务是否启动、容器日志是否异常 |
| 端口 | netstat -ano | findstr :11434 | 目标端口有没有被占用 |
| 磁盘 | 查看模型目录和缓存目录空间 | 是否有足够空间写模型和临时文件 |
最常见的 10 类报错,逐条怎么排
1. “python / pip 不是内部或外部命令”
• 常见表现:命令行里输入 python、pip、ollama 或某个启动脚本,系统直接说找不到命令。
• 根因判断:要么程序根本没装好,要么 PATH 没配对,要么你打开的终端不是那个环境。
• 优先动作:先确认安装目录和当前终端;Windows 用 where python,macOS / Linux 用 which python。确认 pip 跟 python 指向的是同一套环境。
• 修复建议:新手尽量为每个项目单独建一个虚拟环境,不要把系统 Python、conda、venv、嵌入式 Python 混在一起。
2. ModuleNotFoundError / 依赖安装失败
• 常见表现:缺少 torch、xformers、opencv、safetensors,或者安装 requirements.txt 时中途报错。
• 根因判断:通常是环境不干净、Python 版本不合适、镜像源或网络不稳定,或者某个依赖需要编译工具链。
• 优先动作:新建干净环境重装,不要在坏环境里不停补包;先看第一个失败的包,不要只看最后的汇总报错。
• 修复建议:安装顺序优先按官方文档走,先装核心运行时,再装扩展依赖。
3. “Torch not compiled with CUDA enabled” / torch.cuda.is_available() = False
• 常见表现:程序能启动,但就是不吃 GPU;或者直接报 Torch 没启用 CUDA。
• 根因判断:你装到的是 CPU 版 PyTorch,或者当前环境里的 torch 不是给这张显卡准备的构建。
• 优先动作:先运行 Python 检查 torch 版本和 cuda 是否可用,再对照 PyTorch 官方“Start Locally”页面重新选择安装命令。
• 修复建议:不要盲目安装本机 CUDA Toolkit 试图“补齐”。对大多数用户来说,关键是装对 PyTorch 官方提供的匹配构建。
4. CUDA 版本不匹配 / 驱动过旧 / GPU 不受支持
• 常见表现:程序提示 CUDA driver version is insufficient、CUDA mismatch,或者启动时直接崩溃。
• 根因判断:显卡驱动、PyTorch 构建、扩展插件三者之间存在版本断层。
• 优先动作:先看 nvidia-smi,再看 PyTorch 构建信息;如果是 WSL,还要确认 WSL GPU 透传链路是否正常。
• 修复建议:先把驱动更新到稳定版,再按官方安装选择器重装匹配的 PyTorch;插件报错时,优先怀疑插件不是当前 CUDA / Torch 组合编译的。
5. 显存或内存不足:CUDA out of memory / model requires more system memory
• 常见表现:模型加载一半失败、生成到一半崩溃、系统变卡甚至被杀进程。
• 根因判断:模型太大、分辨率太高、批量太多,或者同时开了太多吃显存的软件。
• 优先动作:先关掉浏览器、游戏、录屏和别的 GPU 程序;把模型换小、分辨率调低、批次设为 1。
• 修复建议:本地部署优先追求“先跑起来”,不是一步到位上最大模型。小模型 + 成功闭环,比大模型 + 一直报错更重要。
6. 模型加载失败:missing model / architecture mismatch / safetensors error
• 常见表现:程序提示找不到模型、模型结构不匹配、checkpoint 无法加载,或工作流节点全部变红。
• 根因判断:文件放错目录、文件名不对、模型类型与工作流不匹配,或者下载到的是不完整文件。
• 优先动作:检查模型后缀、目录、文件大小与来源;再看你当前工作流期待的是 checkpoint、LoRA、VAE 还是其他模型。
• 修复建议:先用官方或最基础的示例工作流验证;复杂工作流先别上来就跑。
7. 端口被占用:address already in use / bind failed
• 常见表现:服务明明已经装好了,但启动时报端口占用,比如 11434、3000、7860 等。
• 根因判断:旧进程没退出、多个服务争抢同一个端口、容器或代理仍在后台运行。
• 优先动作:先查是谁占了端口,再决定是结束旧进程、改端口,还是重启对应服务。
• 修复建议:给常用本地服务固定一个自己的端口规划表,避免 LLM、WebUI、代理、容器互相撞车。
8. WSL / Docker / 虚拟化相关报错
• 常见表现:WSL 安装失败、0x80070003 / 0x80370102、Docker Desktop 无法正常使用 WSL 2 后端、容器能起但功能不完整。
• 根因判断:虚拟化没开、WSL 组件没启用、WSL 版本太旧,或者你在 WSL 里又装了一套冲突的 Docker。
• 优先动作:先确认 BIOS 虚拟化、WSL 功能和版本;Docker Desktop 的 WSL 2 后端要按官方步骤开启。
• 修复建议:Windows 端先把 WSL 2 单独装好、更新好,再上 Docker 和各类 AI 工具;不要反过来。
9. 下载失败:网络、代理、SSL、证书问题
• 常见表现:拉模型很慢、下载中断、TLS / certificate 报错、公司网络环境下始终连不上。
• 根因判断:代理变量设置不对、根证书没装好、只配置了 HTTP_PROXY 却没有 HTTPS_PROXY,或者请求被内网策略拦截。
• 优先动作:先确认工具是否真的支持代理,再检查系统证书和代理变量;在公司网络里最好让网络管理员确认出口策略。
• 修复建议:模型下载尽量走官方支持的方式;代理能用时也要尽量保持配置简单、可回滚。
10. 插件 / 自定义节点 / 第三方扩展导致崩溃
• 常见表现:主程序原本能开,一装插件就黑屏、报红、工作流不能执行,或者升级一次后全部坏掉。
• 根因判断:第三方插件最容易和当前 Python、Torch、主程序版本发生兼容性问题。
• 优先动作:先禁用全部插件,再按二分法逐步恢复;ComfyUI 官方文档也明确建议用这种方式排查自定义节点问题。
• 修复建议:插件要少而稳,不要一次装一堆;每次升级前先记录版本和能回滚的备份。
把最常见的报错按“第一反应”整理成表
| 报错 / 症状 | 你先怀疑什么 | 第一动作 |
| 找不到 python / pip | PATH 或环境错了 | where / which 查看实际路径 |
| No module named xxx | 环境不干净或依赖没装全 | 新建环境后重装核心依赖 |
| Torch 没启用 CUDA | 装了 CPU 版 torch | 按 PyTorch 官方选择器重装 |
| CUDA mismatch | 驱动 / 构建 / 插件不匹配 | 先看 nvidia-smi,再看 torch 版本 |
| OOM / 显存爆了 | 模型太大或并发太高 | 先减模型、降分辨率、关别的软件 |
| 模型加载失败 | 路径、架构、文件不完整 | 先验证目录与工作流类型 |
| 端口占用 | 旧进程没关 | 先查占用,再结束或改端口 |
| WSL / Docker 异常 | 虚拟化或 WSL 配置问题 | 先把 WSL 2 单独修好 |
| 下载失败 / 证书报错 | 代理或证书问题 | 先检查 HTTPS_PROXY 和系统证书 |
| 装插件后崩溃 | 插件兼容性问题 | 全部禁用,再二分法恢复 |
日志该去哪里看?这是很多人最该先养成的习惯
真正有价值的信息往往在日志里。如果你只盯着界面弹窗里那一句“failed”,几乎永远只能靠猜。
| 工具 / 环境 | 日志或关键位置 | 你可以看什么 |
| Ollama(Windows) | %LOCALAPPDATA%\Ollama、%HOMEPATH%\.ollama | server.log、模型与配置目录 |
| Ollama(容器) | docker logs <容器名> | 服务启动、拉模型、GPU/CPU 回退信息 |
| ComfyUI | 启动终端 + “Show report” | 具体报错节点、模型路径、显存与依赖异常 |
| Docker Desktop | Docker Desktop 日志 / docker logs | 容器启动失败、端口、挂载、镜像问题 |
| WSL | wsl -l -v、wsl –update | 版本、组件状态、是否为 WSL 2 |
| PyTorch 环境 | python 交互检查 | torch 版本、CUDA 是否可用 |
| 一个容易失误的细节 本地环境出错时,先复制完整报错和前后几十行日志,再开始搜原因。不要一边改环境一边才发现“刚才那段报错没保存”。 |
重装之前,先想清楚:到底该升级、回滚,还是重建环境?
• 能最小修复就不要全盘重装。很多问题其实只需要重装 torch、换模型目录、清理端口或禁用插件。
• 核心依赖坏了就重建环境,不要在旧环境里无限补包。
• 升级前先确认自己要得到什么;“所有东西都升到最新”并不等于最稳定。
• 第三方插件和节点出问题时,优先回滚到“最后一次可用”的状态。
| 建议你给每个本地项目保存一份部署记录: – 系统版本 / 驱动版本 – Python 版本 / 包管理方式 – 关键依赖版本(torch、xformers、docker、ollama 等) – 模型名称与下载来源 – 最近一次成功运行的命令 – 最近一次改动了什么 |
FAQ:新手最容易问的 6 个问题
Q:报错太长了,我到底先看哪一行?
A:先看第一处明确失败的位置,而不是最后一句“任务失败”。通常从 traceback 的第一条关键异常、模型加载路径、版本输出开始看。
Q:我是不是应该先装 CUDA Toolkit?
A:不一定。对大多数使用 PyTorch 预编译构建的用户,关键不是先装本地 Toolkit,而是装对官方提供的匹配构建。
Q:一台电脑可以同时装多个本地 AI 工具吗?
A:可以,但更要做好环境隔离。尤其是 Python 项目、插件和模型目录,不要互相覆盖。
Q:为什么别人同样的教程我照着做也不行?
A:因为你的系统、驱动、Python 版本、显卡、内存、网络环境都可能不同。教程是路径,不是保证书。
Q:最容易一键修好的问题是什么?
A:端口冲突、旧进程未退出、模型放错目录、装错 PyTorch 构建,这几类通常定位后修复很快。
Q:什么时候该直接重建环境?
A:当依赖已经乱到你不确定哪一层坏了,或者你已经进行了多轮互相冲突的修改时,直接新建干净环境往往更省时间。
最后的建议:排错能力,本质上是“建立秩序”的能力
本地部署最怕的不是报错本身,而是没有顺序、没有记录、没有最小复现。只要你学会按层级拆问题、按日志找线索、按单变量做修改,大多数错误都会从“玄学”变成“可解释”。
| 你可以把这篇文章当作一张排错地图 下一次本地环境出问题时,不要先焦虑,也不要先重装。先问自己三个问题:它属于哪一层?日志第一处关键异常是什么?我能不能先用最小命令复现?只要这三个问题答清楚,方向通常就不会错。 |
更多阅读:
《Windows 电脑如何搭建本地 AI 环境,详细步骤演示》

{kind=link}