

逻辑推导选 GPT,创意写作选 Claude?教你根据任务精准匹配模型
AI Stack Nav | 模型选型指南 | 2026 年 4 月版
| 一句话先讲结论 “逻辑推导选 GPT,创意写作选 Claude”大体方向没错,但这句话太粗。真正高质量的模型选择,应该先判断任务是“需要更深的推理”,还是“需要更自然的表达”,再进一步判断是否涉及长上下文、工具调用、实时多模态、成本控制和中文资料整理。 |
一、为什么现在不该再问“哪个模型最强”
到了 2026 年,主流模型已经不再是同一条赛道上的“单点 PK”,而是逐步分工:有的模型擅长多步推理和复杂决策,有的模型擅长把明确任务执行得又快又稳,有的模型更适合长文润色、品牌语气统一和创意延展,还有的模型在中文长资料整理和性价比上更有优势。
所以,真正实用的问题不是“GPT 和 Claude 谁更厉害”,而是“我手上的这类任务,到底该交给谁”。一旦问题改成这个角度,模型选择就会清晰得多。
这也是本文要解决的核心:把模型选择从“凭感觉试运气”,改造成一套可以反复复用的任务匹配方法。
二、先认清 2026 年主流模型的分工
1. GPT 阵营:别再把 GPT 当成单一模型
OpenAI 当前公开文档已经把模型分成两条路线:一条是 GPT 模型,例如 GPT-4.1;另一条是 reasoning 模型,例如 o3、o4-mini。官方对这两类模型的描述非常直白:o 系列更适合复杂问题、模糊信息、大量歧义和高准确率决策;GPT 模型则更像执行型工作马,速度更快、成本通常更低,适合定义清晰的任务。
如果你在做的是“先判断,再决策,再分步解决”的任务,比如复杂排障、策略规划、规则冲突判断、数学推理、代码调试链路,那么更应该优先想到 GPT 的 reasoning 路线;如果你要的是“把要求准确落地”,比如改写、提纲、结构化输出、文档抽取、代码实现、工具调用,那么 GPT-4.1 这样的非 reasoning 主力往往更顺手。
2. Claude 阵营:不是“只会写作”,而是更擅长高质量表达
Anthropic 当前的公开模型页把 Claude Opus 4.6 定位为适合 complex analysis、coding,以及 creative tasks requiring deep reasoning;Sonnet 4.6 被定位为智能与速度的平衡;Haiku 4.5 则是高吞吐、低延迟任务的快速档。
这意味着 Claude 不是只能写作,而是在“需要自然表达、长段连续润色、品牌语气收敛、文风统一、角色口吻稳定”的任务上,往往更容易给出让人直接可用的版本。尤其在你已经有一版草稿、需要它帮你改得更像“人写的”、更顺、更有节奏的时候,Claude 的优势会比纯 benchmark 更明显。
3. 国产替代:Kimi 与 DeepSeek 为什么值得放进工作流
如果你的任务非常依赖中文资料、长上下文、低成本实验,Kimi K2.5 与 DeepSeek-reasoner 其实都值得被纳入“工作流型选择”,而不是只作为备选。
Kimi K2.5 当前公开提供 256K 上下文,并同时支持 thinking / non-thinking 路线,特别适合做中文资料整合、研究摘要、长文问答和轻量代理任务。DeepSeek-reasoner 则更像一条成本更敏感的推理路线:它允许系统先进行 reasoning,再给最终答案,适合做复核、二次判断和解释性推断。
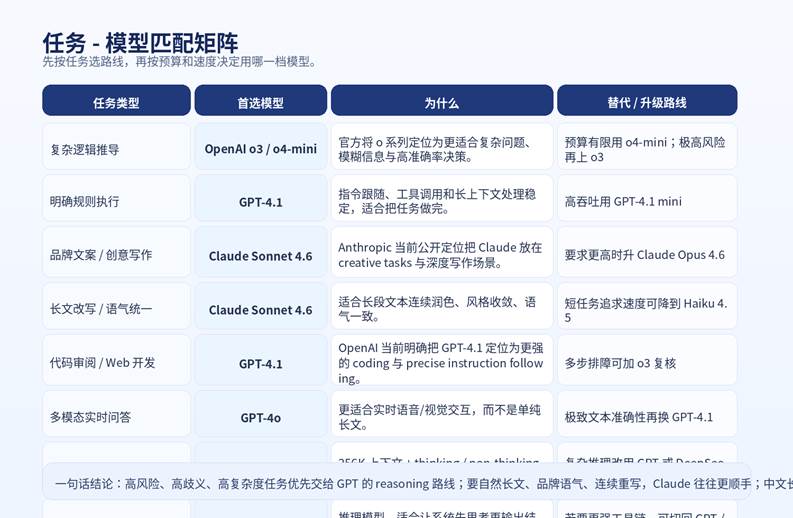
图 1:任务 – 模型匹配矩阵
三、真正好用的判断法:先看任务,不先看品牌
| 实战判断顺序 先问 6 个问题:①任务是否高风险?②是否需要多步推理?③是否更看重自然表达?④是否要处理很长的上下文?⑤是否需要工具调用或结构化输出?⑥预算和速度压力大不大? |
- 高风险、强逻辑、存在歧义的任务:优先考虑 GPT 的 reasoning 路线。
- 规则明确、要求落地、要结构化交付的任务:优先 GPT-4.1。
- 重语气、重表达、重改写、重连续长文质量:优先 Claude Sonnet / Opus。
- 中文研究、长资料梳理、成本敏感场景:优先 Kimi K2.5。
- 需要低成本推理复核、做第二意见:把 DeepSeek-reasoner 作为补充层。
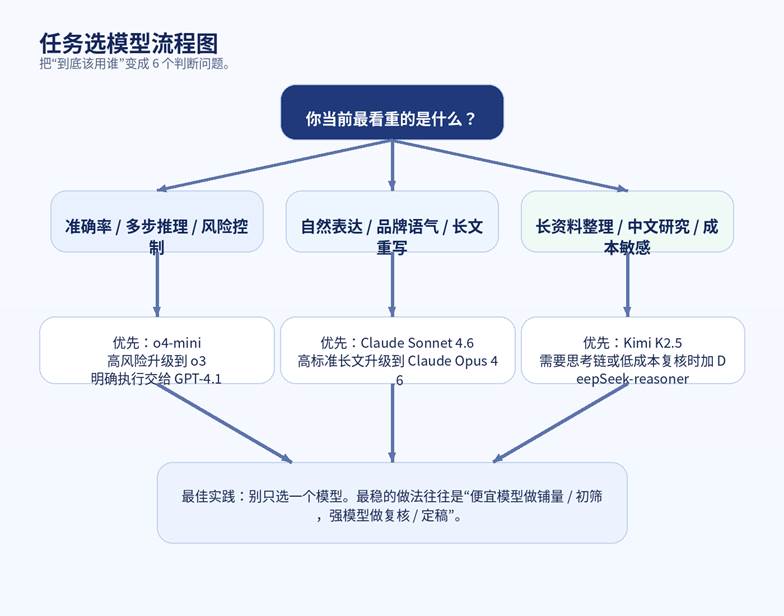
图 2:任务选模型流程图
四、按任务精准匹配:最常见的 12 类工作怎么选
| 任务 | 首选 | 推荐理由 | 补充建议 |
| 复杂逻辑推导 | o3 / o4-mini | 官方就把 o 系列定位为 planner,适合复杂问题和模糊信息。 | 大量任务先用 o4-mini,关键节点再升 o3 |
| 代码审阅 | GPT-4.1 | 指令跟随和 coding 表现稳定,适合明确改动要求。 | 难排障时让 o3 做第二轮原因分析 |
| 数学 / 决策题 | o3 | 需要更深的推理和更稳的中间判断。 | 成本敏感时先试 o4-mini |
| 品牌文案 | Claude Sonnet 4.6 | 更容易写出自然、顺畅、有节奏感的中文长段。 | 高标准 campaign 再升级 Opus 4.6 |
| 长文改写 | Claude Sonnet 4.6 | 语气统一、风格收敛、段落衔接更稳定。 | 先给参考样文,效果会更明显 |
| 采访稿润色 | Claude + GPT 组合 | Claude 负责润色,GPT 负责结构化提纲和事实检查。 | 组合使用通常比单模更稳 |
| 研究资料整合 | Kimi K2.5 | 256K 上下文适合做长资料摘要与问答。 | 结论性判断可再给 GPT / DeepSeek 复核 |
| 会议纪要整理 | GPT-4.1 | 规则明确,结构化输出稳定。 | 需要长上下文时可先分段整理 |
| 产品 PRD 草案 | GPT-4.1 | 执行型任务:按模板、按约束、按字段生成很稳。 | 用 Claude 做“人味和说服力”增强 |
| 视频脚本铺量 | GPT-4.1 mini / Haiku 4.5 | 追求速度、成本和批量产出。 | 爆款候选再交给强模型精修 |
| 低成本推理复核 | DeepSeek-reasoner | 适合做第二意见、风险提示、推断说明。 | 不要把它当唯一裁判,适合补充层 |
| 多模型工作流 | 混合编排 | 便宜模型初筛,强模型定稿,性价比最高。 | 给每一步定义清晰评价标准 |
五、别再单选:高手都在用“模型组合拳”
很多团队迟迟选不出“最适合自己的模型”,不是因为试得不够,而是因为他们从一开始就在问错问题:总想找一个模型包打天下。但现实里,最稳的方案往往不是“只用一个”,而是分工协作。
一个很通用的组合是:便宜模型负责铺量和初筛,强模型负责复核和定稿。比如 50 条短视频脚本先让 GPT-4.1 mini 或 Claude Haiku 4.5 批量出,再把点击率更高的候选交给 Claude Sonnet 做风格强化;又比如先用 Kimi 整理 20 万字资料,再让 GPT 的 reasoning 模型判断其中真正值得采纳的结论。
六、可直接复制的 Prompt 模板
| 模板 1:逻辑推导 / 高风险判断(GPT reasoning) 你是审慎的分析助手。请先识别题目中的约束、冲突点与未知项,再给出分步推理路径,最后输出结论。若信息不足,明确指出需要补充什么,而不是直接猜。输出格式:1)关键前提 2)推理步骤 3)结论 4)风险提醒。 |
| 模板 2:结构化执行 / 文档生成(GPT-4.1) 你将严格按照我给定的字段和格式输出,不要扩写到格式之外。任务目标是:____。必须遵守的约束:____。输出字段包括:____。若缺信息,请列出待补充字段,不要擅自虚构。 |
| 模板 3:品牌文案 / 创意写作(Claude) 请基于以下品牌语气写作:____。目标受众:____。文风参考:____。请先提炼语气关键词,再输出正文。要求语言自然、避免模板味,段落有节奏,结尾要有记忆点。给出 A/B 两个版本。 |
| 模板 4:长文改写 / 润色(Claude) 请保留原文核心信息和结构逻辑,但把语言改得更自然、更像资深编辑写的。重点优化:句式重复、口语与书面语混杂、段落衔接、节奏感、收束力。不要删掉关键信息。 |
| 模板 5:长资料整理(Kimi) 以下是多份资料,请先按主题聚类,再提炼共识、分歧和待核实点,最后输出一份给决策者看的摘要。请优先保留原始来源中的关键数字、时间和定义。 |
| 模板 6:第二意见复核(DeepSeek-reasoner) 请把下面的初稿当作候选答案,不要直接重复。你的任务是:检查其逻辑漏洞、事实跳跃、前提遗漏和潜在误导点,并给出一版更稳妥的修正版。 |
七、最容易踩的 5 个坑
- 把“表达自然”误判成“更聪明”。文风好不等于推理更稳,别让好读掩盖逻辑问题。
- 把“会推理”误判成“什么都适合”。推理模型并不总是最省钱、最快、最适合批量执行。
- 只看 benchmark,不看真实工作流。很多任务真正需要的是结构化输出、稳定性和可控性。
- 不给样例和约束,却期待模型精准。无论 GPT 还是 Claude,输入不清晰都会拉低表现。
- 坚持单模型信仰。今天最稳的生产方式,往往是混合编排。
八、FAQ
| Q1:逻辑推导是不是一律选 GPT? 不是。更准确地说,是“复杂逻辑、高风险决策、多步推理”优先考虑 GPT 的 reasoning 模型;如果只是明确规则下的执行型任务,GPT-4.1 可能更合适。 |
| Q2:创意写作是不是一律选 Claude? 也不是。Claude 在长段表达、语气统一、改写润色上通常更讨喜,但如果任务同时要求强结构、强约束和大量字段输出,GPT-4.1 反而更稳。 |
| Q3:Kimi 适合什么? 适合中文长资料处理、研究整理、长文问答和成本相对敏感的试验场景。 |
| Q4:DeepSeek 应该怎么用? 最适合放在复核层:让它对候选结论做二次推理、风险提醒和漏洞检查,而不是把它当唯一裁判。 |
| Q5:有没有一条最通用的原则? 有:先定义任务,再选模型;先小模型铺量,再强模型定稿;先让模型各司其职,再谈谁更强。 |
九、相关阅读
- 《长文本之王是谁?实测 Claude、GPT 与 Kimi 的上下文理解上限》
- 《三分钟读懂 Prompt:如何像指挥官一样给 AI 下达指令?》
- 《一人公司实战:我如何用 AI 辅助完成了从产品策划到代码实现的全过程》
- 《不用梯子也能飞:2026 国内最值得使用的 Top 10 AI 应用推荐》
十、结语
“逻辑推导选 GPT,创意写作选 Claude”可以当作一个入门判断,但别把它当成死规则。真正成熟的做法,是根据任务把模型拆成功能角色:谁负责推理,谁负责执行,谁负责润色,谁负责长资料整合,谁负责低成本复核。
一旦你用这种方式看模型,很多所谓“谁更强”的争论会自动失效。因为在生产环境里,强不强从来不是抽象问题,而是:在这个具体任务上,谁更值。
