

Gemma 4 是什么?开源 Agent 模型入门指南
从型号选择、函数调用到本地跑通,一篇看懂 Google 新一代开放权重 Agent 模型家族
| 栏目:资源与模型 | 定位:入门 + 选型 + 实操 | 建议阅读:8-10 分钟 |
如果你最近在关注“本地可跑”“Agent 能力”“开放权重模型”这几个关键词,Gemma 4 很值得认真看一眼。它不是单一型号,而是一整个模型家族:小到适合手机、树莓派和轻量边缘设备,大到可以在工作站和云端承担更复杂的推理、代码与工具调用任务。更关键的是,Gemma 4 把 thinking、system role、函数调用和长上下文这些做 Agent 常用的能力,统一放进了同一代模型能力栈里。
| 先说结论:Gemma 4 最适合两类人:一类是想做本地或边缘端 Agent 的开发者;另一类是想用开放权重模型搭建可控工作流的人。它的强项不是“替你自动做完一切”,而是把模型理解、推理和工具调用能力,和你自己的应用逻辑更顺滑地拼起来。 |
一、Gemma 4 到底是什么
更准确地说,Gemma 4 是 Google DeepMind 发布的开放权重模型家族。官方发布页把它定位为可商用的 open models,文档页说明它支持负责任的商业使用;开发者博客则明确写到 Gemma 4 以 Apache 2.0 许可提供,用于本地和边缘设备上的 Agent 开发。
这代模型最值得记住的四个关键词是:多模态、长上下文、原生函数调用、可配置推理。
• 多模态:全系支持文本与图像输入;E2B、E4B 还原生支持音频能力。
• 长上下文:小模型最高 128K,上位模型最高 256K,更适合长文档、长对话和工作流记忆。
• Agent 友好:支持 system role、function calling、结构化输出,更容易接进工具链。
• 部署跨度大:从手机、笔记本到工作站与服务器,都有相对合适的版本。

图 1 Gemma 4 型号与部署建议速览
二、为什么很多人把它称为“开源 Agent 模型”
原因不只一个。一方面,Gemma 4 提供开放权重与明确许可,方便开发者下载、微调、量化和自行部署;另一方面,它在能力层面直接补齐了做 Agent 最需要的几块:
• system role:可以稳定设定角色、边界、输出格式与工具使用规则。
• thinking mode:适合复杂推理、分步规划与多阶段决策。
• function calling:模型可以输出结构化工具调用请求,把动作交给你的应用执行。
• 多模态理解:做截图分析、页面理解、PDF/文档解析、图表理解时更方便。
| 关键边界:Gemma 4 可以“建议”调用什么工具,也可以“生成”函数调用参数,但它不会自己执行代码。真正的 API 调用、脚本执行、数据库写入和安全校验,都必须由你的应用层来完成。 |
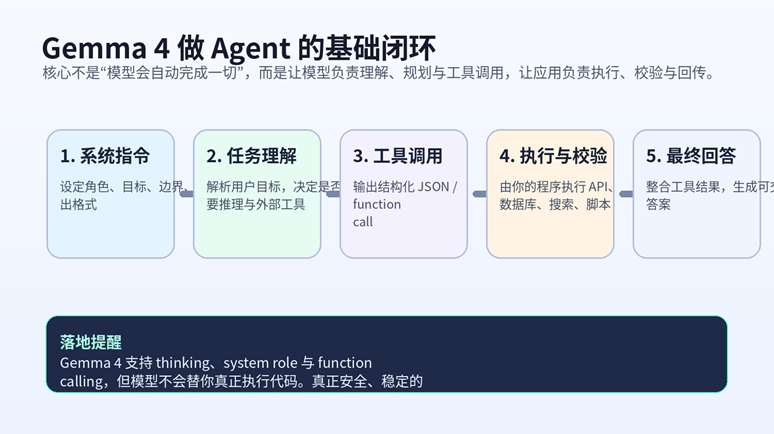
图 2 用 Gemma 4 做 Agent 的基础闭环
三、Gemma 4 家族该怎么选
| 型号 | 官方定位 | 上下文 | 模态 | 一句话建议 |
| E2B | 极轻量、本地/边缘优先 | 128K | 文本 / 图像 / 音频 | 适合手机、轻量助手、IoT 与离线实验 |
| E4B | 更均衡的轻量版本 | 128K | 文本 / 图像 / 音频 | 适合笔记本、本地多模态助手与轻量 Agent |
| 26B A4B | MoE,高性价比 | 256K | 文本 / 图像 | 适合单卡工作站上的较强 Agent 与代码任务 |
| 31B | 更高质量上限 | 256K | 文本 / 图像 | 适合复杂推理、代码、云端服务与更稳的最终回答 |
一个容易被忽略的点是 26B A4B。它是 Mixture-of-Experts(MoE)架构,官方模型卡给出的说明是:虽然每个 token 实际只激活约 3.8B 参数,但为了快速路由与推理,全部参数仍然需要加载进内存。也就是说,它的“推理活跃参数”更像 4B 级,但“显存门槛”并不会真的只有 4B 模型那么低。
显存参考(官方概览页整理)
| 型号 | BF16 | SFP8 | Q4_0 |
| E2B | 约 9.6 GB | 约 4.6 GB | 约 3.2 GB |
| E4B | 约 15 GB | 约 7.5 GB | 约 5 GB |
| 26B A4B | 约 48 GB | 约 25 GB | 约 15.6 GB |
| 31B | 约 58.3 GB | 约 30.4 GB | 约 17.4 GB |
四、Gemma 4 适合哪些场景
• 本地代码助手:读取项目片段、理解报错、生成函数或脚本。
• 企业内部 Agent:对接知识库、表单、审批接口、数据库查询。
• 多模态助手:看截图、识别文档、读图表、抽取页面信息。
• 离线边缘应用:对隐私敏感、低时延或弱网环境更友好。
• 手机或嵌入式设备上的智能功能:官方也在推动 AI Edge 方向。
五、从零开始跑起来:最小上手路径
如果你是第一次接触 Gemma 4,建议按这个顺序:
• 先在 Hugging Face 或 Kaggle 获取官方模型权重;
• 再用 Transformers 跑通最小推理;
• 之后再决定要不要做量化、本地 UI、Agent 编排或微调。
1)安装基础环境
| pip install -U torch accelerate transformers sentencepiece |
2)最小文本 / 图像推理示例
| from transformers import AutoProcessor, AutoModelForMultimodalLM import torch MODEL_ID = “google/gemma-4-E4B-it” processor = AutoProcessor.from_pretrained(MODEL_ID) model = AutoModelForMultimodalLM.from_pretrained( MODEL_ID, torch_dtype=”auto”, device_map=”auto” ) messages = [ {“role”: “system”, “content”: [{“type”: “text”, “text”: “你是一名中文技术编辑,回答要清晰、分点。”}]}, {“role”: “user”, “content”: [{“type”: “text”, “text”: “请用 5 句话解释 Gemma 4 为什么适合做 Agent。”}]}, ] inputs = processor.apply_chat_template( messages, tokenize=True, return_dict=True, return_tensors=”pt”, add_generation_prompt=True ).to(model.device) outputs = model.generate(**inputs, max_new_tokens=256) print(processor.decode(outputs[0], skip_special_tokens=True)) |
| 实操建议:第一次跑通时,优先选 E2B 或 E4B。它们更容易在普通设备上快速完成“验证闭环”,不要一上来就追求最大模型。 |
3)如何打开 thinking mode
官方文档说明,Gemma 4 支持可配置 thinking mode。对复杂推理题、规划题、多轮工具使用决策,它通常比直接回答更稳;但 thinking 会增加时延与 token 开销,所以不必对所有任务默认开启。
4)如何接上 function calling
基础原则只有一句:让模型负责“该调用什么”,让程序负责“真正去执行”。
| tools = [ { “name”: “get_weather”, “description”: “查询天气”, “parameters”: { “type”: “object”, “properties”: { “city”: {“type”: “string”, “description”: “城市名”} }, “required”: [“city”] } } ] # 典型闭环: # 1. 把 tools 定义传给模型 # 2. 模型返回函数名与参数 # 3. 你的程序校验参数并调用真实 API # 4. 把结果再喂回模型 # 5. 模型生成给用户看的最终答复 |
六、Gemma 4 做 Agent 时,最值得利用的能力
| 能力 | 适合做什么 | 实操建议 |
| system role | 给模型设规则、格式、角色边界 | 把“语气要求”“输出 JSON”“禁止越权动作”写进 system,不要散落在 user prompt 里。 |
| thinking mode | 复杂推理、任务拆解、规划 | 只在高复杂度任务开启,避免对简单聊天也强制思考。 |
| function calling | 调用搜索、数据库、邮件、日历、脚本 | 参数必须在应用层二次校验,尤其是写操作、外部请求和代码执行。 |
| 长上下文 | 长文档问答、流程记忆、多轮工单 | 适合长材料,但不是“无限记忆”;仍需做摘要与上下文整理。 |
| 多模态 | 看图、看文档、识别截图或图表 | 先设计稳定的输入模板,例如“先概括,再抽取字段,再输出结构化结果”。 |
七、部署建议:本地优先,还是云端优先
• 你更在意隐私、离线能力、低延迟:优先本地或边缘部署。
• 你更在意最高质量、多人并发、统一运维:优先工作站或云端部署。
• 你要做 PoC:先用 E2B / E4B 跑通流程,再决定是否升级到 26B A4B / 31B。
• 你做的是工具调用型 Agent:通常流程设计与工具校验,比一味升级参数更重要。
| 经验判断:很多 Agent 项目真正的瓶颈,不是模型参数不够大,而是工具接口定义混乱、权限边界不清、错误恢复机制不完整。Gemma 4 能把“理解与规划”做得更好,但工程质量仍决定最终上限。 |
八、Gemma 4 的限制,也要提前知道
• 开放权重不等于自动无门槛:真正跑得稳,仍然需要模型下载、量化、推理框架与设备适配。
• 函数调用不等于自动执行:所有高风险动作都必须在应用层加白名单与校验。
• 长上下文不是万能:上下文越长,越需要你主动做摘要、检索与选择。
• 小模型的优势是便宜、快、本地友好;但复杂推理、复杂代码和最终表达质量,通常还是大模型更稳。
九、写给新手的上手路线
• 先用 E2B 或 E4B 跑通一句话问答;
• 再做一次 system role + JSON 输出;
• 然后接一个最简单的 function calling;
• 最后再考虑多模态、长上下文和完整 Agent 流程。
这样做的好处是:你会先建立稳定的闭环,再逐步增加复杂度,而不是一开始就被权重、显存、推理框架和工作流编排同时绊住。
FAQ
Gemma 4 是真正意义上的开源吗?
中文语境里很多人会直接说“开源模型”,但更严谨的说法是开放权重模型家族。官方文档强调 open models / open weights,并提供商业使用与许可说明。
Gemma 4 能直接做 Agent 吗?
可以作为 Agent 的大脑,但它不会自动替你执行工具。完整 Agent 仍需要你自己写工具层、权限层和错误恢复逻辑。
新手应该从哪个版本开始?
优先从 E2B 或 E4B 开始,先跑通,再升级。
26B A4B 看起来像 4B 模型吗?
不是。它是 MoE,推理时激活参数较少,但全部权重仍要加载,显存门槛不能按 4B 模型去理解。
Gemma 4 适合本地部署吗?
适合,这正是它的重要卖点之一,尤其是 E2B、E4B。
做中文内容或中文 Agent 可以吗?
可以。官方文档写明其预训练覆盖 140+ 语言,开箱支持 35+ 语言。中文可用,但具体效果仍建议按你的业务数据实测。
相关阅读
• n8n、Dify、Coze 是什么?自动化工作流入门教程
参考资料(官方)
Google Blog|Gemma 4: Our most capable open models to date
Google AI for Developers|Gemma 4 model overview
Google AI for Developers|Gemma 4 model card
Google AI for Developers|Gemma releases
Google Developers Blog|Bring state-of-the-art agentic skills to the edge with Gemma 4
Google AI for Developers|Thinking mode in Gemma
Google AI for Developers|Function calling with Gemma 4
