这是一篇面向企业管理层、信息化负责人和 AI 项目经理的实施型长文,围绕企业如何从试点走向规模化落地展开。文章覆盖业务选型、治理框架、数据底座、评测体系、安全合规、90 天推进节奏,并整理 20 个来自官方客户故事的行业案例,同时附上可直接改写成演示稿的 PPT 页面源码。
企业级 AI 落地实施方案 :从试点到规模化,附 20 个行业案例与可复用 PPT 页面源码
文档定位 适用对象 附加内容
这不是一份“堆功能名词”的 AI 文章,而是一份适合发布、也适合继续扩写成咨询提案或汇报稿的实施版本。全文用官方框架、公开客户案例与可复用页面骨架,帮助你把“企业想上 AI”拆成能执行、能评估、能审计的落地动作。
执行摘要
企业级 AI 落地最常见的问题不是“模型不够强”,而是业务目标不清、数据治理缺位、权限边界模糊、评测体系缺失,以及试点成功却无法规模复制。
McKinsey 2025 调研显示,78% 的受访组织已经在至少一个业务职能中使用 AI,71% 的组织在至少一个业务职能中经常使用生成式 AI。说明“是否要做”已不是关键问题,真正的分水岭在于能否跨过从试验到规模化的那一步。[R1]
IBM 的企业级调研则显示,42% 的千人以上企业已主动部署 AI,另有 40% 仍处于探索或试验阶段;技能短缺、数据复杂度和伦理担忧仍是主要阻碍。[R2]
Microsoft Cloud Adoption Framework 将成功的 AI 战略归纳为四个核心:可量化业务价值、匹配团队能力的技术选择、可扩展的数据治理,以及负责任 AI 实践。[R3]
NIST AI RMF 与 ISO/IEC 42001 提醒企业:AI 不是一个单纯的软件采购项目,而是需要长期治理、风险管理和持续改进的管理体系。[R4][R5]
一句话结论:企业要把 AI 做成 “ 体系 ” ,而不是做成 “ 演示 ” 。
一、为什么 2026 年企业更适合系统化做 AI
过去两年,市场已经给出一个很明确的信号:企业对 AI 的兴趣不再停留在创新部门,而是扩展到 IT、市场、销售、客服、产品研发、知识管理和运营支持等多个职能。McKinsey 2025 调研显示,组织平均已在三个业务职能中使用 AI,而生成式 AI 的使用最集中在 IT、市场销售、服务运营和产品/服务开发。[R1]
这意味着,企业在今天做 AI,应该从“单点工具采购”转向“跨职能能力建设”。如果还沿用传统信息化项目思路,只看功能清单、一次性交付和短期采购预算,往往会在上线后迅速暴露出数据权限、内容可信度、成本控制和内部采纳率等问题。
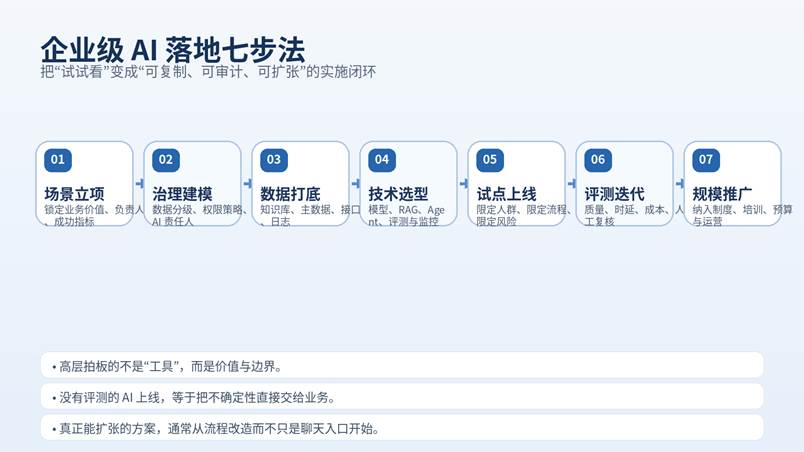
图 1 |企业级 AI 从试点到规模化的七步法
真正值得投入的,不是让所有员工立刻“用上某个大模型”,而是建立一套可重复的方法:如何找场景、如何接数据、如何设边界、如何做评测、如何做组织推进、如何把经验固化成制度。
二、企业级 AI 落地的五个底层原则
1. 先定业务结果,再定技术形态: 不要从“做个知识库”或“上个机器人”开始,而应从明确结果开始:想减少多少处理时间、提升多少转化率、缩短多少分析周期、减少多少人工回呼。没有业务指标,AI 项目很容易变成长期试验。
2. 先治理数据与权限,再开放交互入口: 企业一旦把内部资料接进模型,就必须明确哪些数据能被检索、哪些内容能被总结、哪些答案必须人工审核、哪些用户只能看到自己权限范围内的信息。
3. 先做评测体系,再做大规模推广: 很多项目不是“完全不能用”,而是“偶尔说错却没人知道什么时候错”。所以必须有离线评测集、上线监控、人工抽检和风险升级机制。
4. 先改流程,再谈 AI 体验: 如果 AI 只停留在一个聊天框,而没有嵌入审批、工单、CRM、采购、客服台、研发知识流等实际流程,价值通常会被高估。
5. 先做组织机制,再谈规模复制: 企业级项目一定涉及业务负责人、IT、法务/合规、数据治理、采购、培训和运营。没有明确的 owner 和节奏,试点成功也很难扩张。
三、可直接复用的实施方案:7 个模块搭建企业 AI 体系
模块 A|场景与价值设计
建立“候选场景池”,按业务价值、数据可得性、风险等级、实施复杂度四维打分。
优先选择高频、重复、知识密集、可量化的流程,如客服问答、报告摘要、售前资料检索、内部制度问答、采购支持、研发资料搜索。
为每个试点写出一页纸 business case:业务目标、负责人、当前流程、目标流程、成功指标、上线边界。
模块 B|治理与责任划分
建议设立轻量级 AI 治理机制:业务 owner 负责目标,IT/平台负责技术与安全,数据治理负责权限与质量,法务/合规负责高风险场景审查。
Microsoft 的 AI 战略框架强调,把数据治理和 responsible AI 作为前置要求,而不是项目末尾的补充项。[R3]
治理文档至少要包含:允许接入的数据类型、禁止内容、审计日志要求、人工复核场景、模型变更审批方式。
模块 C|数据与知识底座
把企业知识分成三类:公开知识、内部共享知识、受限知识;分别设计检索范围与角色权限。
优先治理高价值资料:制度文档、FAQ、产品资料、合同模板、售前方案、项目复盘、研发报告、客服工单。
如果主数据与流程数据分散在多个系统,先做目录与映射,不急于一次性全量打通。
模块 D|技术架构与评测
大多数企业场景不需要一开始就 fine-tune,自然语言检索 + RAG + 工作流编排 + 审计日志,已经能覆盖大量内部应用。
高风险场景要同时配评测:准确性、引用完整性、拒答率、时延、成本、人工回退率。
Morgan Stanley 的官方案例强调,其 AI 成功的基础是稳健的 eval 框架,而不是单纯追求更大模型。[C4]
模块 E|安全、合规与风险管理
参考 NIST AI RMF,企业要把治理、风险映射、度量与处置纳入闭环,而不是只在出问题后补救。[R4]
参考 ISO/IEC 42001,建议把 AI 管理体系纳入组织长期制度,建立持续改进机制。[R5]
最容易出问题的环节通常不是模型输出本身,而是数据越权、错误引用、未标注生成内容、缺少人工兜底。
模块 F|试点、培训与采纳
试点阶段建议限定人群、限定流程、限定语料、限定指标,避免“全员开通后没人真正使用”。
培训不要只教 prompt,而要教“何时可信、何时要复核、何时要转人工、如何反馈错误”。
建立 champion 机制,让一线骨干用户参与试用、反馈和内部传播。
模块 G|规模化与运营
上线不是终点,必须进入运营:月度质量复盘、知识库更新、模型版本管理、成本看板、用户满意度。
当某个试点成熟后,再复制“方法”到第二、第三个场景,而不是简单复制机器人界面。
企业真正的护城河是:你能否把数据、流程、角色和治理一起固化成组织能力。
四、一个适合多数企业的 90 天推进节奏
阶段 时间 关键动作 交付物 准备期 第 1–2 周 访谈业务、筛选 3–5 个候选场景、定义成功指标、梳理数据与权限边界 场景评分表、一页纸 business case、风险清单 试点期 第 3–8 周 接入知识源、完成原型、构建评测集、灰度给小范围用户使用 试点版本、评测报告、使用手册、人工兜底流程 验证期 第 9–12 周 复盘质量/时延/成本/满意度,决定保留、迭代还是停止 上线决策、二期路线图、运营与培训计划
对中大型企业来说,最容易失败的不是“技术没跑起来”,而是试点后没有形成标准模板。建议在 90 天内至少产出 4 个可复用模板:场景立项模板、风险清单模板、评测报告模板、上线运营模板。
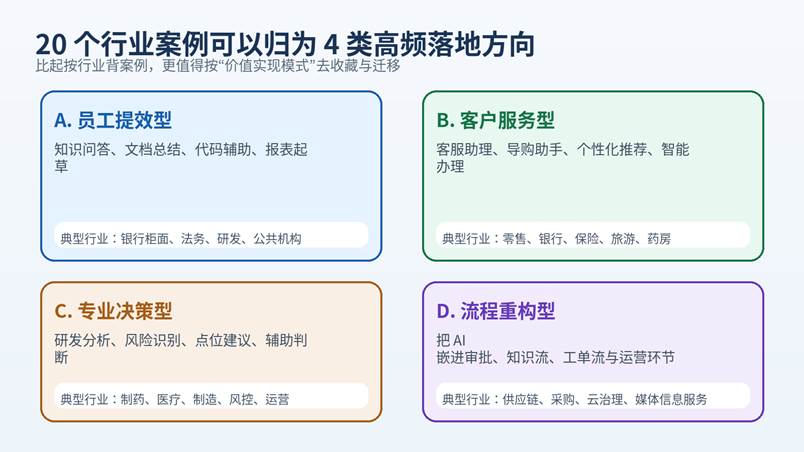
图 2 | 20 个行业案例背后,其实只是在重复 4 种高频价值模式
五、20 个行业案例:不要只收藏企业名,更要收藏落地方式
下面这 20 个公开案例全部来自官方客户故事或官方企业页面。我没有把它们写成“热榜”,而是刻意按“可迁移方法”去整理。这样你后续不管是写方案、做 PPT,还是跟客户交流,都更耐用。
案例清单(1–10)
行业 / 场景 企业 落地方向 可复制启示 来源 金融 / 柜面助手 E.SUN Bank 先从柜员问答场景切入,用 Vertex AI Search 处理银行里大量非结构化制度与流程文档,减少新手柜员频繁回呼总行的问题。 适合规程复杂、问答量大的一线组织。 C1 金融 / 消费者客服 Federal Bank 面向消费者推出完整生成式 AI 服务入口,把自然语言应答真正放进客户触点,而不是只停留在内部试验。 先选“高频且标准化”的客服问题。 C2 金融 / 数字银行 Cake Digital Bank 用 Vertex AI 与 Gemini Flash 做全渠道 chatbot,并把 AI 扩展到 eKYC、生物识别、反欺诈和个性化推荐。官方案例提到贷款或信用卡申请可在两分钟内完成,并已自研 50 个 AI 模型。 真正的企业级落地不是单点聊天,而是进入风控与运营链路。 C3 金融 / 财富管理 Morgan Stanley 把 AI 用在顾问知识获取、摘要与洞察生成,同时强调先建立 evaluation framework,确保结果稳定可靠。 金融行业最值得学习的是“先评测,再放量”。 C4 医药 / 研发 Pfizer 与 AWS 共建生成式 AI 原型,加快治疗方案与研发资料检索。官方披露每年节省 16,000 小时检索时间,并降低 55% 基础设施成本。 研发型企业可优先做知识搜索与研究助手。 C5 医药 / 数据分析 Sanofi 通过内部 Digital Accelerator,把先进分析周期从 6 个月压缩到 1 个月,并在 18 个月内推出 8 个产品。 落地速度来自“小型跨职能战队”而不是大而全项目组。 C6 医药 / 制造 Merck 在制造部门导入生成式 AI,目标是更快完成数据分析、药物开发与生产优化。 制造业的 AI 切口,往往是知识密集型运营而不是先上机器人。 C7 医疗 / 药房咨询 El Ezaby 构建药房咨询 chatbot,官方案例显示响应时间下降 70%,满意度提升 50%,问题解决率提升 3 倍,运营负载下降 25%。 非常适合连锁门店与专家支持体系。 C8 医疗 / 风险调整 Reveleer 用 Gemini 和 Vertex AI 做 prospective risk adjustment,让医生在 point of care 获得更及时的信息。 医疗 AI 的关键价值常在“提前给医生信息”,而不是事后整理。 C9 医学教育 / 行政 Uniformed Services University 除了研究支持,也把生成式 AI 用到邮件、报告、行政文书等工作中,把时间还给科研与教学人员。 组织协同效率场景更容易先形成正反馈。 C10
案例清单(11–20)
行业 / 场景 企业 落地方向 可复制启示 来源 公共卫生 Wayne State University 把专有数据接入 PHOENIX 与 CHNA2.0,用生成式 AI 更快完成社区健康需求评估,并支持实时更新。 公共部门也能做 AI,但前提是把数据接起来。 C11 制造 / 采购与客户研究 Jabil 基于 Amazon Q Business 建 Customer Research Assistant 与 Procurement Assistant,把 AI 放进采购与客户研究流程。 企业若要出 ROI,采购、售前、交付支持是高命中区。 C12 汽车 / 云治理 BMW Group 开发面向 DevOps 的云优化助手,官方案例强调其在安全前提下帮助扩展云治理、降本和缩短上市时间。 AI 也可以是内部平台团队的效率工具。 C13 化工 / 企业助手 Clariant 在安全环境中上线内部助手 Clarita,用于文档总结、专利综合、毒理学与研发等场景。 知识产权敏感行业应把安全边界前置设计。 C14 零售 / 导购助手 Central Group 用 Gemini 搭建 personal shopper chatbot,自动处理购物清单等导购任务,同时保留人工服务的温度。 零售里的 AI 不只是客服,还可做导购和转化。 C15 零售 / 一线反馈 Tapestry 一年收集 30,000 条门店反馈,8 周做出 Ask Rexy,生成式 AI 方案开发速度提升 10 倍。 先把一线反馈数字化,再让 AI 做归纳和行动建议。 C16 零售 / 商场与通信数据 StarHub 把通信数据与零售数据结合,形成 Smart Retail Platform,用来识别人流、交叉销售和忠诚度机会。 跨域数据一旦打通,AI 就能直接服务经营。 C17 媒体 / 公共信息服务 Megamedia 做高精度公共信息 chatbot,官方案例提到 30 秒内即可访问关键信息,且在 4 个月内完成模型构建与部署。 面向公众的信息服务很适合用 AI 提升可达性。 C18 体育 / 媒体内容 MLB 单场比赛实时分析 1,500 万个数据点,统计传递提速 300ms,同时用于个性化内容推荐。 当数据规模足够大,AI 的价值会直接体现在体验差异上。 C19 法律 / 专业服务 Harvey 联合 OpenAI 做定制案例法模型,用于文书起草、复杂诉讼问答和合同差异识别。 专业服务行业要把领域知识、评测与长文档能力一起考虑。 C20
六、附录:20 个行业案例 PPT 页面源码(可直接复制改写)
这里的“源码”不是指受限商业文件,而是可以直接复制到演示稿里的页面骨架:每页给出标题方向、讲法结构和建议的呈现重点。你后续做商务汇报、提案、投标材料或课程内容时,可以直接沿用。
Slide 01 |金融柜面助手 标题:制度问答从“打电话问总行”到“前台秒级自助检索” 结构:业务痛点 / 数据来源 / RAG 架构 / 上线边界 / 价值指标
Slide 02 |消费者银行客服 标题:先把高频标准问题自动化,再考虑复杂金融咨询 结构:客户旅程 / FAQ 归类 / 人工转接策略 / 合规提示
Slide 03 |数字银行全链路 AI 标题:聊天入口只是表面,真正价值在 eKYC、风控与推荐 结构:前台体验 / 中台模型 / 风控节点 / 指标
Slide 04 |财富管理顾问助手 标题:把评测体系做在前面,避免“能答但不敢用” 结构:知识接入 / eval 指标 / 顾问工作台 / 审计
Slide 05 |医药研发知识搜索 标题:检索时间下降,研发人员把时间留给判断 结构:知识库 / 原型范围 / 节省工时 / 成本变化
Slide 06 |医药数据加速器 标题:小型跨职能战队,往往比传统大项目更快出结果 结构:组织机制 / 迭代节奏 / 周期压缩 / 产品化
Slide 07 |医药制造优化 标题:制造现场的 AI,先做数据解释与异常分析 结构:制造数据 / 分析任务 / 产线协同 / 质量风险
Slide 08 |药房咨询机器人 标题:专家经验沉淀成前台可调用的能力库 结构:咨询链路 / 医学知识 / 人工复核 / 用户体验
Slide 09 |医疗风控与点位提示 标题:在正确时点把信息送到医生眼前 结构:患者画像 / 风险识别 / 提示方式 / 安全边界
Slide 10 |高校科研与行政提效 标题:先解放老师与研究人员的文书时间 结构:科研文档 / 行政表单 / 权限控制 / 培训
Slide 11 |公共卫生洞察 标题:把静态年报升级成可持续刷新的动态评估 结构:数据汇聚 / 生成分析 / 实时监测 / 社会价值
Slide 12 |制造采购助手 标题:采购与客户研究,是最容易被忽视的高 ROI 场景 结构:采购流程 / 检索与总结 / 建议输出 / 成本
Slide 13 |云治理助手 标题:平台团队也需要自己的 AI 同事 结构:云资源 / 成本优化 / DevOps 协同 / 安全加密
Slide 14 |化工企业内部助手 标题:安全环境是知识密集型行业落地 AI 的前提 结构:安全要求 / 内部助手 / 使用场景 / IP 保护
Slide 15 |零售导购助手 标题:导购型 AI 的目标不是回答问题,而是促成转化 结构:用户意图 / 商品数据 / 推荐链路 / 留资转化
Slide 16 |门店反馈智能归纳 标题:把海量前线反馈压缩成门店可以执行的动作 结构:采集 / 归类 / 优先级 / 运营闭环
Slide 17 |跨域经营洞察 标题:数据一打通,AI 才能对经营产生复利 结构:数据融合 / 客群洞察 / 营销动作 / 商场招商
Slide 18 |公共信息服务 标题:公共问答系统的第一价值是可达性与准确性 结构:知识边界 / 准确率 / 响应速度 / 责任机制
Slide 19 |体育内容个性化 标题:高实时性数据场景,是 AI 展现差异化体验的好机会 结构:实时数据 / 内容推荐 / 个性化 / 安全
Slide 20 |法律专业服务 标题:领域模型、长文档能力与审阅流程缺一不可 结构:语料来源 / 法律工作流 / 引用与审阅 / 交付质量
七、FAQ
1. 企业做 AI ,一定要先自建大模型吗?
2. 最适合先做的试点是什么?
3. AI 项目为什么常常 “ 演示效果很好,上线效果一般 ” ?
4. 如何判断一个试点是否值得继续投钱?
5. 法务、金融、医疗这些高风险行业还能做吗?
八、资料来源(官方)
以下清单用于正文事实校核与案例整理。为控制版面,我将网址压缩为“域名 / 路径摘要”的展示方式;如需原始链接,可直接参照本文 SEO 文档或按来源名称检索官方页面。
编号 来源 网址(简) R1 McKinsey《The State of AI: Global Survey 2025》 www.mckinsey.com / capabilities/quantumblack/…/the-state-of-ai-how-organizations-are-rewiring-to-capture-value R2 IBM 2024 企业 AI 采用研究 newsroom.ibm.com / 2024-01-10-Data-Suggests-Growth-in-Enterpris… R3 Microsoft Cloud Adoption Framework:Create your AI strategy learn.microsoft.com / en-us/azure/…/strategy R4 NIST AI Risk Management Framework www.nist.gov / itl/ai-risk-management-framework R5 ISO/IEC 42001 AI management systems www.iso.org / standard/42001 C1 E.SUN Bank × Google Cloud cloud.google.com / customers/esunbank C2 Federal Bank × Google Cloud cloud.google.com / customers/federalbank C3 Cake Digital Bank × Google Cloud cloud.google.com / customers/cake-digital-bank C4 Morgan Stanley × OpenAI openai.com / index/morgan-stanley C5 Pfizer × AWS aws.amazon.com / solutions/case-studies/…/pfizer-PACT-case-study C6 Sanofi × AWS aws.amazon.com / solutions/case-studies/sanofi-case-study C7 Merck × AWS aws.amazon.com / solutions/case-studies/innovators/merck C8 El Ezaby × AWS aws.amazon.com / solutions/case-studies/elezaby-itvisionary C9 Reveleer × Google Cloud cloud.google.com / customers/reveleer C10 Uniformed Services University × Google Cloud cloud.google.com / customers/uniformed-services-university C11 Wayne State University × Google Cloud cloud.google.com / customers/wayne-state-university C12 Jabil × AWS aws.amazon.com / solutions/case-studies/…/jabil-manufacturing-transformation-generative-ai C13 BMW Group × AWS aws.amazon.com / solutions/case-studies/bmw-generative-ai C14 Clariant × AWS aws.amazon.com / solutions/case-studies/…/clariant-generative-ai C15 Central Group × Google Cloud cloud.google.com / customers/central-group C16 Tapestry × AWS aws.amazon.com / solutions/case-studies/…/tapestry-generative-ai-case-study C17 StarHub × AWS aws.amazon.com / solutions/case-studies/generative-ai-starhub C18 Megamedia × AWS aws.amazon.com / solutions/case-studies/megamedia-case-study C19 MLB × Google Cloud cloud.google.com / customers/major-league-baseball C20 Harvey × OpenAI openai.com / index/harvey