

上下文窗口、推理模型、MoE 到底是什么
新手也能看懂的概念拆解与选型指南
分类:资源与模型 | 定位:新手入门 / 概念辨析 | 适合阅读时长:8 分钟
| 文章摘要 很多新手在看大模型介绍时,会同时遇到“上下文窗口”“推理模型”“MoE”这三个词,但它们并不在同一个层面上:上下文窗口讲的是模型一次能看到多少内容,推理模型讲的是模型为了复杂任务会不会走更长的思考路径,MoE 讲的是模型内部是不是采用“专家分工”的结构。看懂这三个概念,你在选聊天模型、代码模型或本地部署模型时就不会再把参数、速度、长文本能力和架构设计混成一团。 |
为什么这三个词总会一起出现
因为它们都出现在模型介绍页、榜单评测和本地部署讨论里,但说的并不是同一件事。很多人会把“上下文更长”理解成“更聪明”,把“推理模型”理解成“参数更大”,又把“MoE”理解成“所有专家一起上所以一定更强”。这些理解都不够准确。
更好的记法是:上下文窗口属于输入范围;推理模型属于能力使用方式;MoE 属于模型架构设计。先把层级分开,后面无论是看官方说明、看评测,还是本地部署时看显存要求,都会清楚很多。
图 1:三个概念分别对应“输入范围 / 推理方式 / 架构设计”三个层面。
一、上下文窗口是什么
上下文窗口(Context Window)可以理解为:模型在当前这一轮处理里,最多能同时“看见”的文字、代码、表格或其他输入内容总量。这个总量通常以 token 计算,而不是直接按“汉字个数”或“单词个数”计算。
你可以把它想成一张工作台。工作台越大,一次能摊开的材料越多;工作台越小,就需要你先删减、摘要,或者分多轮输入。它决定的是“能装多少”,不是“会不会想”。
| 一句话理解 | 模型一次最多能参考多少上下文 |
| 最适合场景 | 长文档总结、长对话、多文件代码审阅、整页资料分析 |
上下文窗口大,具体好在哪
- 可以一次塞进更完整的资料,不用频繁切段。
- 前后文保留更多,模型更不容易“忘掉”前面刚说过的条件。
- 适合做长代码、长文档、会议纪要、合同、论文、知识库问答这类需要整体视野的任务。
但它不等于“记忆力更强”
很多新手最容易误会的点就在这里:上下文窗口只是当前轮次可用的“工作区”,不是跨会话永久记忆。会话结束以后,模型并不会因为窗口大就自动长期记住你。
而且“理论窗口很长”不等于“有效利用率一定高”。输入越长,越考验模型在长距离依赖、检索定位、注意力分配上的真实能力。也就是说,能装进去,不一定就能用得同样好。
二、推理模型是什么
推理模型可以理解为:在面对复杂任务时,更愿意把问题拆成多步、进行中间分析、再给出答案的一类模型。它强调的是“解决问题的过程是否更擅长分解、规划和校验”,而不是只追求第一时间给出一句结果。
这类模型通常更适合数学题、逻辑题、复杂代码调试、方案比较、多约束规划这类需要逐步推进的任务。通俗点说,它更像一个会先列草稿、再落答案的人。
| 更适合 | 一般表现 | 不一定占优 |
| 数学 / 逻辑 | 更稳地分步求解 | 纯闲聊、简单改写 |
| 代码 / 调试 | 更擅长定位错误链路 | 极短、极快的问答 |
| 规划 / 决策 | 更会列条件、比方案 | 只求速度的批量输出 |
推理模型不等于参数更大
“会推理”描述的是模型在任务处理策略上的倾向,而不是单纯的体量标签。一个模型参数更大,不代表它在复杂推理上就一定比专门优化过的推理模型更稳;反过来,一个推理模型也未必在每个简单任务上都值得你使用。
对用户来说,更现实的区别通常体现在三个维度:延迟更长、成本更高、复杂任务正确率更好。所以你在选型时要先问自己:我要的是“更快出结果”,还是“更愿意为复杂任务多想一步”。
三、MoE 是什么
MoE 是 Mixture of Experts 的缩写,通常翻成“专家混合”架构。你可以把它想成一个团队:团队里有很多专家,但每次处理一个问题时,不是把所有人都叫来一起写答案,而是先做路由判断,再挑最合适的少数专家上场。
这样做的好处是,模型总参数可以做得很大,但单次推理时只激活其中一部分参数,因此在效果和成本之间寻找平衡。也正因为如此,很多人会看到“总参数非常大”,但真正单次参与计算的只是其中活跃的一小部分。
怎么理解“总参数”和“活跃参数”
这也是本地部署里经常被问到的点。一个 MoE 模型可能总参数很大,但如果每次只激活少量专家,那么你真正关心的除了总参数,还要看活跃参数、显存占用、吞吐速度以及量化后的部署表现。
所以看到 MoE 时,不要只盯着参数数字。更关键的问题是:单次推理到底会调动多少计算、你本地机器能不能扛住、量化之后性能掉不掉得太明显。
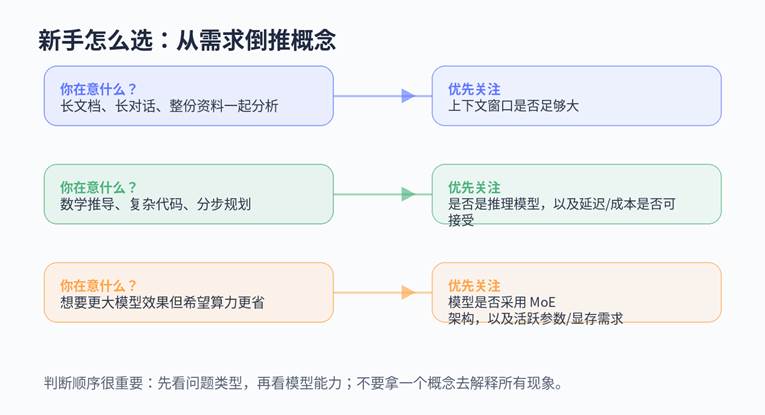
图 2:不要先盯模型名,先看你要解决的是“长输入”“复杂推理”还是“更省算力的更大架构”。
四、三者的区别,一张表记住
| 概念 | 它回答的问题 | 你应该关注什么 | 最常见误解 |
| 上下文窗口 | 一次能看多少内容 | 长文档/长对话/长代码是否够用 | 窗口大就等于更聪明 |
| 推理模型 | 会不会分步想、会不会更稳 | 复杂任务正确率、延迟、成本 | 推理模型一定在所有任务更强 |
| MoE | 模型内部是不是专家分工 | 活跃参数、显存、吞吐、量化表现 | 总参数大就等于每次都全量计算 |
五、新手到底该怎么选
| 场景:如果你主要做长文档总结、资料归纳、合同/论文阅读 建议:优先关注上下文窗口和长文档利用能力。 |
| 场景:如果你主要做代码调试、数学题、复杂方案规划 建议:优先看是否是推理模型,以及速度和成本是否可接受。 |
| 场景:如果你在看本地部署模型,机器配置有限,但又想追求更大模型效果 建议:重点看 MoE 架构、活跃参数、量化版本和实际显存占用。 |
| 场景:如果你只是日常聊天、写作润色、轻量问答 建议:不必执着这三个词的“最大值”,够用、稳定、响应快往往更重要。 |
六、新手最容易踩的 5 个坑
- 把上下文窗口当成长期记忆系统。
- 看到“推理模型”就默认它对所有任务都更好。
- 只盯总参数,不看活跃参数和真实部署成本。
- 用一个指标解释所有体验差异,例如把慢、贵、长文档能力都归因到同一概念。
- 看模型宣传页时只记名词,不回到自己的任务场景。
结语
把这篇文章压缩成一句话:上下文窗口看“能装多少”,推理模型看“会不会多想一步”,MoE 看“模型内部怎么分工”。它们不是替代关系,而是不同维度的描述。
所以你以后看到模型介绍时,先不要急着被名词带着走。先问:我的任务到底需要更长输入、更强复杂推理,还是更省算力的大模型结构。问题一旦问对,选型就会简单很多。
FAQ:读完后最常见的 8 个问题
| 1. 上下文窗口越大,回答一定越好吗? 不一定。窗口越大只是允许你放进更多材料,真正能不能高质量利用这些材料,还取决于模型的长距离注意力、检索能力和任务设计。 |
| 2. 推理模型是不是就等于“思维链可见”? 不是。推理模型强调复杂任务上的分步求解能力;它是否向用户展示中间过程,是产品层和安全层的另一个问题。 |
| 3. MoE 是不是把所有专家一起算,所以更吃显卡? 不是。MoE 的关键恰恰在于稀疏激活:通常只让少数专家参与一次推理。真正部署时仍要关注模型实现、量化和显存管理。 |
| 4. 为什么有些长上下文模型看长文档还是会漏? 因为“能装下”不等于“能稳定定位重点”。文档结构、提示词写法、是否分段检索、模型本身的长上下文利用能力都会影响结果。 |
| 5. 我主要写代码,应该先看哪个概念? 如果是复杂调试、重构和多文件理解,通常先看推理能力,再看上下文窗口是否够大。 |
| 6. 本地部署时最容易忽略的点是什么? 只看参数数字,不看量化版本、活跃参数、上下文长度设定、推理速度和真实显存占用。 |
| 7. 推理模型一定更慢吗? 通常会更慢一些,因为它更擅长走多步分析,但是否明显变慢,还和实现方式、服务策略、硬件条件有关。 |
| 8. 这三个词里,哪个最值得新手先搞懂? 先搞懂上下文窗口最容易上手,再理解推理模型的适用任务,最后把 MoE 当作架构知识补上,会更顺。 |
