

最适合本地部署的开源模型推荐
按显存门槛、中文能力、推理速度与许可条件,帮你把本地部署路线一次选清楚
| 分类 资源与模型 | 适读人群 想在本机或私有环境跑模型的个人 / 团队 | 阅读重点 轻量入门、单卡主力、工作站级选型 |
| 文章摘要:这不是一篇只比参数量的“模型排行榜”,而是一篇从本地部署真实约束出发的选型文章。文中按显存预算、中文能力、上下文长度、许可条件、推理速度与工具链成熟度,拆解 Qwen3、Gemma 3、Mistral Small 3.1、Phi-4-mini、Llama 3.2 / 3.3、DeepSeek-R1-Distill-Qwen-32B 等路线,给出轻量入门、单卡主力与工作站级三档建议。 | ||
先看结论
如果你只有一台普通笔记本或 8GB-12GB 级显存,优先看 Phi-4-mini、Llama 3.2 3B、Gemma 3 4B 这类轻量模型;如果你有 16GB-24GB 级显存,真正的甜点区通常在 Qwen3 8B / 14B、Gemma 3 12B、Mistral Small 3.1;如果你追求更强推理或更高稳定性,再上 DeepSeek-R1-Distill-Qwen-32B 或 Llama 3.3 70B。
真正影响体验的往往不是“参数越大越好”,而是三件事:你的机器能不能稳定跑、你平时做的是中文写作还是复杂推理、以及模型许可是否适合你的商用场景。
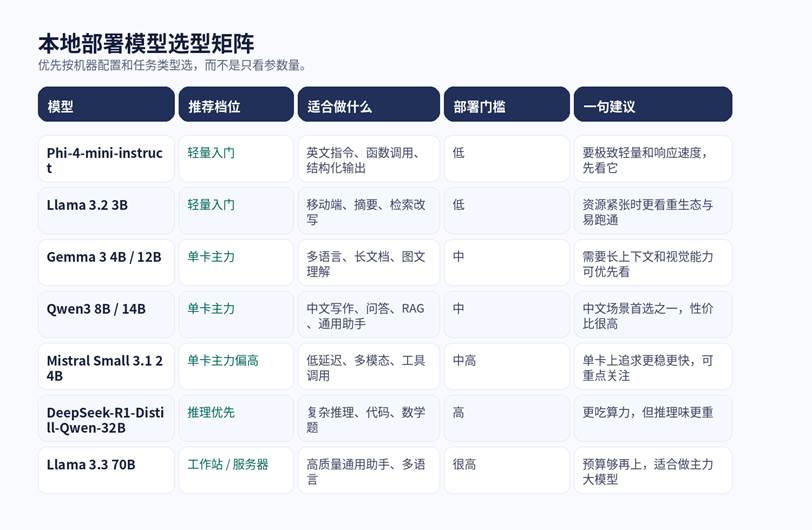
图 1:先按硬件与任务选区间,再在同档位里比风格和许可。
为什么很多“本地部署推荐”并不实用
第一类问题是只看榜单,不看推理成本。很多榜单里的模型在 API 里很强,但一旦落到个人电脑、Mac、单卡工作站上,速度、显存和上下文成本会立刻变成现实约束。
第二类问题是只看参数,不看任务。写作改写、知识库问答、代码补全、复杂推理,其实对模型风格要求不同。一个擅长长链路推理的模型,不一定就是最舒服的日常本地助手。
第三类问题是忽略许可差异。中文内容里常把开放权重模型统称为“开源模型”,但严格说来,Apache 2.0、MIT 与 Llama Community License 在商用自由度和约束上并不完全一样。
本地部署时最该看的 5 个指标
1. 显存 / 内存门槛:能不能装得下、上下文一拉长会不会明显掉速。
2. 中文体验:看中文写作是否自然、术语是否稳、指令跟随是否听话。
3. 上下文长度:长文档、RAG、对话记忆都依赖这个维度。
4. 推理速度:本地可用体验往往输在首字延迟和每秒 token 数。
5. 许可与生态:能不能商用、社区量化版本多不多、Ollama / LM Studio / llama.cpp 好不好接。

图 2:显存区间只是起点;量化方式、上下文长度和推理框架会直接影响最终体验。
最值得优先看的几条模型路线
1. Qwen3:中文本地部署的主力路线
如果你更看重中文写作、问答和通用助手体验,Qwen3 仍然是最值得优先试的一条线。它把 0.6B、1.7B、4B、8B、14B、32B 六个 dense 版本,以及 30B-A3B、235B-A22B 两个 MoE 版本都开放出来,覆盖面非常完整。对个人用户最实用的是 8B、14B 和 30B-A3B:前两者更适合单卡与桌面端,后者更像“高配但还讲究效率”的路线。
2. Gemma 3:长上下文、多语言和图文理解兼顾
Gemma 3 的优势是形态非常规整:270M、1B、4B、12B、27B 五档尺寸,4B 以上给到 128K 上下文,且 4B、12B、27B 能处理图像输入。对本地部署来说,它的价值不只是“能跑”,而是量化信息、上下文和多语言支持都很清楚,适合做文档问答、跨语言内容处理和轻量视觉理解。
3. Mistral Small 3.1:单卡上的高质量主力模型
如果你已经有 24GB 左右显存,或者愿意在 Mac / 工作站上追求更顺手的综合体验,Mistral Small 3.1 很值得看。它的亮点是 24B 体量、128K 上下文、多模态和函数调用能力,同时官方明确给出了“单张 RTX 4090 或 32GB RAM Mac 可运行”的定位。对于希望把本地模型接进工具链、自动化流程或多模态工作台的人,这条线很实用。
4. Phi-4-mini:极致轻量但依然能干活
很多人想要的其实不是“最强模型”,而是“启动快、占用小、结构化输出干净”的模型。Phi-4-mini-instruct 的位置就在这里。它是 3.8B 级模型,支持 128K 上下文,微软还强调了更大的词表、函数调用与更好的指令跟随。对于英文为主、要做小助手、表单抽取、工具调用或本地自动化的人,它往往比更大的模型更顺手。
5. Llama 3.2 / 3.3:生态最成熟的一条线
Llama 的最大优势永远是生态。Llama 3.2 的 1B 和 3B 更像“资源受限环境里的通用底座”,很适合移动端、嵌入式或极轻量本地助手;Llama 3.3 70B 则是预算更高时的旗舰级路线,适合需要高质量多语言助手、复杂工作流和团队级私有部署的场景。要注意的是,它用的是自定义社区许可,不是 Apache / MIT 这类更宽松的标准开源许可。
6. DeepSeek-R1-Distill-Qwen-32B:想要更强推理就看它
如果你的核心任务是代码、数学、复杂逻辑链条,DeepSeek-R1-Distill-Qwen-32B 仍然很有代表性。它不是最轻的模型,但在本地部署世界里,它代表的是“把推理味做得更明显”的路线。它更适合进阶用户:愿意接受更高推理成本,来换取更强的复杂问题拆解能力。
怎么按自己的机器来选
只有 CPU 或很小显存:先以 3B-4B 级模型为主,重点是跑通工作流与验证需求。
16GB 左右显存:这是本地部署最舒服的入门线,8B-14B 往往能兼顾质量和速度。
24GB 左右显存:可以开始认真看 24B-32B 路线,中文、RAG、写作和工具调用体验会明显提升。
48GB 以上或多卡:这时才有必要讨论 70B 级旗舰,或更完整的私有服务化部署。
部署工具怎么选更省事
对大多数个人用户来说,桌面端优先选 LM Studio 或 Ollama,原因很简单:上手快、量化版本多、切模型成本低。想把模型嵌进脚本、服务或自动化流程,再考虑 llama.cpp、vLLM 这类更工程化的路线。最常见的错误,是一开始就搭复杂服务,结果模型还没真正跑明白。
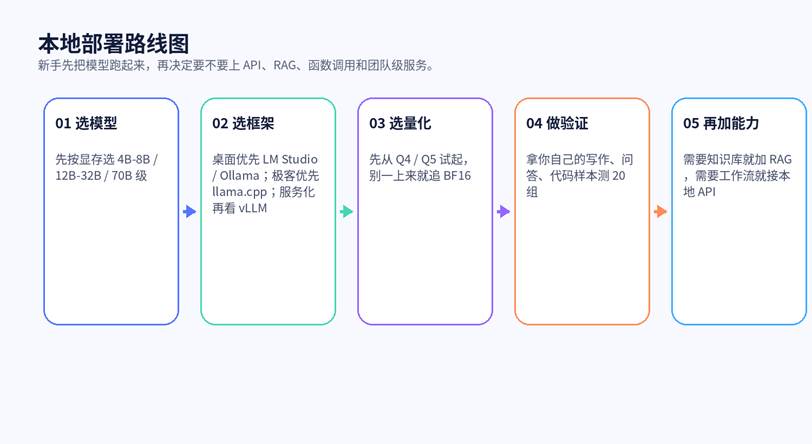
图 3:新手最稳的路径,是先做单机验证,再逐步上本地 API、知识库和自动化流程。
最后给一套更实用的选择顺序
第一步,不要先问“最强是谁”,先问“我的机器能长期跑什么”。
第二步,不要只测公开 benchmark,用你自己的中文写作、资料整理、代码片段和知识库样本去压测。
第三步,把许可单独看一遍。个人折腾和团队商用,对许可敏感度完全不同。
第四步,先定 1 条主力路线,再定 1 条轻量备份路线。比如 Qwen3 14B 做主力,Phi-4-mini 做快速调用;或者 Mistral Small 3.1 做主力,Gemma 3 4B 做轻量助手。
| 一句话总结: 轻量入门看 Phi-4-mini / Llama 3.2 3B,中文主力看 Qwen3 8B / 14B,需要长文档和图文理解看 Gemma 3,需要更稳的单卡体验看 Mistral Small 3.1,追求复杂推理再上 DeepSeek-R1-Distill-Qwen-32B,预算足够才考虑 Llama 3.3 70B。 |
