

聚焦中文写作、长文成稿、资料整合、创意表达与成本友好度
先看结论
| 一句话选型 如果你只想先拿结论:综合写作优先看 GPT-5.4;长文润色与文风打磨优先看 Claude 4.6;资料型写作与大文档整合看 Gemini Pro;中文长资料和学习型写作看 Kimi K2.5;预算敏感或批量起稿看 DeepSeek-V3.2;小说、角色文案和强风格化表达可关注 Mistral Small Creative。 |
“最适合写作”的大模型,未必是参数最大、跑分最高,真正影响体验的往往是三件事:第一,能不能把结构搭稳;第二,能不能把语气写得像人;第三,能不能在长资料、长上下文里保持不跑偏。
所以这篇文章不打算再做一遍空泛的参数盘点,而是直接站在真实写作场景里来选:你到底是写公众号、专栏、报告、脚本、知识整理,还是在做图文账号内容生产?不同任务,答案并不一样。
为了更贴近实际使用,我把这次判断重点放在六个维度:中文自然度、长文稳定性、资料整合能力、创意表现、成本友好度,以及是否适合长期当“写作主力模型”。
判断“写作模型”时,我最看重哪六件事
| 维度 | 为什么重要 |
| 中文自然度 | 句子是否顺、是否有翻译腔、是否能写出更像中文母语者的表达。 |
| 长文稳定性 | 是否能把提纲贯彻到全文,而不是写到中段就散。 |
| 资料整合 | 面对多篇材料、长 PDF、访谈记录、会议纪要时,能否先吃透再写。 |
| 创意表现 | 是否擅长故事感、角色感、标题感、金句感和风格迁移。 |
| 成本友好度 | 是否适合高频调用、批量起稿或中小团队长期使用。 |
| 工作流兼容性 | 是否便于接入搜索、文档、工具、项目空间与自动化流程。 |
六个值得优先关注的写作大模型
下面这张图先帮你建立整体感觉:它不是客观跑分榜,而是面向真实写作工作流的编辑判断。
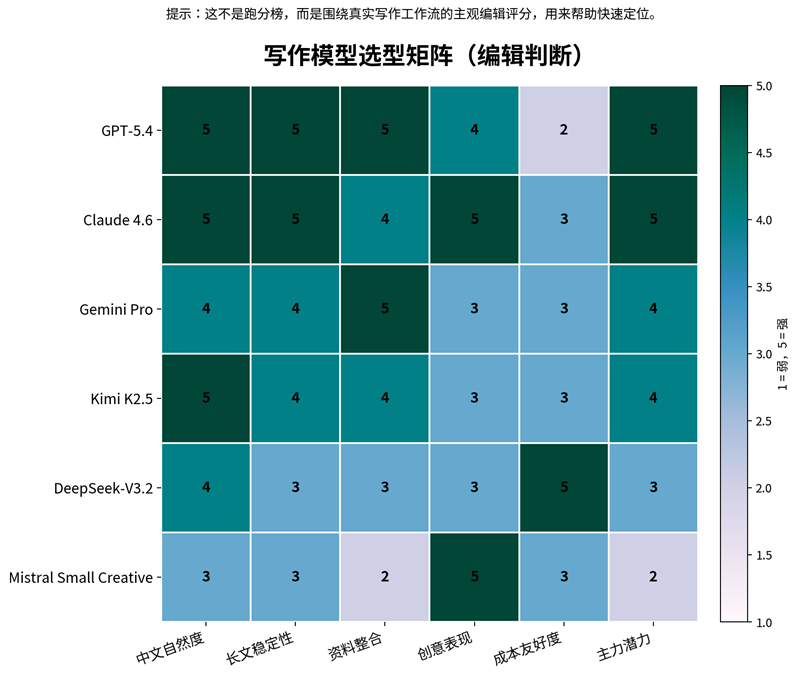
图 1|写作模型选型矩阵(编辑判断)
| 模型 | 最适合 | 你会喜欢它的原因 | 要注意 |
| GPT-5.4 | 长期主力 | 研究 + 提纲 + 成稿 + 改写都很稳 | 追求极强文学风格时未必最有味 |
| Claude 4.6 | 长文润色 | 自然文风、长段落节奏、重写能力强 | 最终事实仍需单独核验 |
| Gemini Pro | 资料整合 | 大文档理解、先读后写、资料压缩 | 更像资料型写作助手 |
| Kimi K2.5 | 中文实用 | 中文长资料、知识整理、学习型写作 | 强文学风格不是最强项 |
| DeepSeek-V3.2 | 批量起稿 | 成本友好、适合自动化与第一轮生成 | 常需要第二轮润色 |
| Mistral Small Creative | 创意补强 | 小说、角色、风格表达、对话感 | 不适合作为唯一主力 |
1. GPT-5.4:综合写作最稳的一档
最适合:职业写作、商业写作、知识整理、长项目文档、需要研究与写作一体化的人
为什么值得关注
- 结构感强,适合先做框架、再做成稿、最后做多轮改写。
- 对正式文体、说明文、商业文案、分析型长文都比较稳定。
- 在文档、表格、演示等知识工作场景上投入明显,适合把“写”和“整理”放在一个工作流里。
- 如果你需要一边研究一边写,再继续拆成多平台版本,GPT-5.4 很适合作为主控模型。
要注意什么
- 在追求极强个人风格、文学腔或情绪密度时,不一定总是最“有味道”的那一个。
- 如果只是低成本批量起稿,性价比未必最优。
编辑结论:适合作为大多数写作者的默认主力。尤其适合做一个长期稳定的“写作操作系统”。
2. Claude 4.6(Sonnet / Opus):长文打磨、语气润色、自然文风很能打
最适合:专栏、深度文章、讲述型长文、说明文重写、润色改写、人味增强
为什么值得关注
- 对长段落节奏、过渡、收束和语气统一往往做得更自然。
- 适合拿来做“第二棒”:把初稿重写得更像成熟作者,而不是像模型在输出。
- 面对长上下文与大量页面输入时更从容,适合做改稿、整稿和统一口吻。
- 做长文修订时,常能更好地保留原意,同时减少机械感。
要注意什么
- 如果你的目标是多工具联动、非常工程化的流水线,配置和成本要算清楚。
- 写得顺不代表事实就自动可靠,资料核验仍然要单独做。
编辑结论:如果你已经有提纲或初稿,Claude 往往是把内容从“能读”推到“更像成稿”的强力选手。
3. Gemini Pro 系列:资料型写作和长上下文整合能力很强
最适合:需要先读大量资料再写的文章、白皮书、报告、研究综述、课程笔记整理
为什么值得关注
- 长上下文和文档理解能力突出,适合吃多份 PDF、网页、资料包之后再组织内容。
- 更适合做“资料先行”的写作:先理解,再提纲,再压缩成稿。
- 如果你的写作经常依赖原始文档、研究资料和外部来源,它的路线会更顺。
要注意什么
- 预览版能力迭代快,适合关注版本变化;生产使用时要留意稳定性与版本更新。
- 单看语言风味,未必总是中文写作者最喜欢的一档。
编辑结论:当你的核心难点不是“写不出来”,而是“资料太多、看不过来”,Gemini 会很有价值。
4. Kimi K2.5:中文长资料与知识型写作的实用派
最适合:中文资料整理、课程笔记、知识号脚本、读书笔记、采访稿整理、学习型写作
为什么值得关注
- 长上下文对中文用户非常友好,适合把讲义、录音转写、论文摘要、文档笔记吃进去再输出。
- 更适合中文信息密集型写作,而不是纯创意表达。
- 如果你平时处理的是中文网页、中文文档和本地知识材料,上手门槛低。
要注意什么
- 强文学风格和极细腻修辞并不是它最亮的长板。
- 如果目标是做极高完成度的品牌文风,通常还会再接一轮润色模型。
编辑结论:非常适合中文内容工作者把零散材料变成结构化初稿,是“先整理、再创作”路线里的高实用型选择。
5. DeepSeek-V3.2:成本友好,适合批量起稿与流程化写作
最适合:批量标题、摘要、结构草稿、信息压缩、技术文章初稿、成本敏感团队
为什么值得关注
- 价格与接入门槛相对友好,适合高频调用。
- 在结构化任务、摘要提炼、技术向内容起稿上表现够用,适合先把毛坯做出来。
- 更适合进入自动化工作流,承担“第一轮内容生产”角色。
要注意什么
- 如果你追求非常自然的人类写作质感,通常需要第二轮人工或更强模型润色。
- 复杂叙事、品牌语气和高情绪密度文本,不是它的优势区。
编辑结论:适合作为写作流水线里的“起稿机”和“压缩机”,而不是最终定稿机。
6. Mistral Small Creative:创意写作、角色口吻、风格化表达值得关注
最适合:小说片段、短剧梗概、IP 人设文案、角色对话、风格模仿、创意段子
为什么值得关注
- 官方就把它定位在 creative writing 与 dynamic character interaction 上,方向很明确。
- 当你需要更强的人设感、角色感、对话感,它比通用模型更有“偏科优势”。
- 适合给内容生产加入更多故事性和差异化表达。
要注意什么
- 它不是最典型的资料型写作模型,也不是默认的中文长文主力。
- 更适合作为创意环节的专项模型,而不是全流程唯一模型。
编辑结论:如果你的内容靠风格、角色、故事感取胜,它值得进入你的备用模型列表。
如果你不是做评测,而是真的要开始写
对于多数写作者来说,选型并不难,难的是把模型放到对的环节。先按场景选,再按预算和文风细调,效率会高很多。

图 2|按写作场景选模型
- 只想选一个长期主力:优先 GPT-5.4。它更像全能写作平台,研究、框架、改写、结构化输出比较平衡。
- 已经有初稿,只想把文章写得更像人:优先 Claude 4.6。拿来做重写、润色、统一口吻很合适。
- 材料很多,写之前先要读懂:优先 Gemini Pro 系列或 Kimi K2.5。前者更偏多文档整合,后者更偏中文资料实用处理。
- 预算敏感,还要批量生成:优先 DeepSeek-V3.2 做第一轮,再用更强模型或人工做终稿。
- 内容强依赖故事感和角色感:优先 Mistral Small Creative,或者把它放在创意前期。
更推荐的做法:别找唯一冠军,而是搭一条写作生产线
在真实内容工作里,最稳妥的方式通常不是押注一个模型,而是让不同模型分工。下面是一条很实用的组合路线:
- 资料收集阶段:Gemini Pro / Kimi K2.5 负责吃文档、做摘要、压缩重点。
- 提纲阶段:GPT-5.4 负责把主题、受众、结构、节奏一次理顺。
- 成稿阶段:GPT-5.4 或 Claude 4.6 负责完成正文。
- 润色阶段:Claude 4.6 负责口吻统一、删冗句、提气口、补过渡。
- 批量分发阶段:DeepSeek-V3.2 负责把长文拆成标题、摘要、短帖和多平台版本。
- 创意强化阶段:Mistral Small Creative 负责把平直内容改得更有角色感、故事感。
四个常见误区
- 误区一:把“会回答问题”当成“会写文章”。很多模型对问答不错,但写长文时结构很容易散。
- 误区二:只追求一个模型包打天下。现实里最有效的通常是两到三模型分工,而不是单点神话。
- 误区三:不做事实核验。越会写的模型,越容易把错误写得像真的。
- 误区四:把模型输出直接当成定稿。真正好的工作流,至少会经过提纲、成稿、润色、校核四步。
三条可以直接套用的 Prompt
再好的模型也怕指令模糊。你可以直接把下面三条模板拿去改。

图 3|可直接套用的写作 Prompt 模板
最后的选择建议
如果你问“写作到底选哪一个”,真正有用的答案不是某个绝对冠军,而是你的工作流对应哪一种模型分工。
对大多数内容工作者来说,最稳的路线通常不是单模型,而是“资料整合模型 + 主力成稿模型 + 润色模型”的组合。这样既能保持效率,也能把文章质量拉上去。
一句话收束:想要全能稳定,选 GPT-5.4;想要文风自然、长文更像成稿,选 Claude 4.6;想要先吃透资料再写,选 Gemini Pro 或 Kimi K2.5;想要低成本批量起稿,选 DeepSeek-V3.2;想要更强故事感,补上 Mistral Small Creative。
说明与参考范围
说明:文中关于模型定位、上下文与公开能力的信息,参考各家截至 2026 年 3 月的官方文档与发布页面。
- OpenAI:Introducing GPT-5.4
- Anthropic:Intro to Claude / Models overview / Context windows / Migration guide
- Google AI for Developers:Gemini Models / Gemini 3.1 Pro Preview / Document understanding / Long context
- Moonshot AI:Kimi K2.5 Quickstart / Kimi API docs
- DeepSeek API Docs:Your First API Call / Models & Pricing / V3.2 Release
- Mistral Docs:Models / Mistral Small Creative
