

AI Stack Nav | 网站栏目发布风
AI 视频模型推荐,新手到进阶都适用
按真实使用场景拆解:不只看谁最火,更看谁更适合你的内容工作流。
| 一句话结论 不会剪、想快速出片,先看 Pika 和 Sora;想做广告分镜和表演控制,重点看 Runway;追求音画一体和更高规格,优先看 Veo;想兼顾修改、延展与角色连续性,可以看 Luma;需要私有化或本地部署,则把 Wan2.2 和 HunyuanVideo-1.5 放到第一梯队。 |
一、为什么这篇不按“谁最强”来写
AI 视频模型已经从“能不能动起来”进入“能不能稳定进工作流”的阶段。对多数创作者来说,真正重要的不是榜单名次,而是三个现实问题:第一,多久能得到一个可用结果;第二,能否按照你的镜头和角色要求迭代;第三,是否适合你目前的制作链路。
因此,这篇文章把模型分成两大类来看:一类是直接在线出片的闭源工作流,适合大多数新手、运营和内容团队;另一类是更偏进阶与私有化的开源路线,适合开发者、工作站用户和需要深度可控的团队。
二、评估一款 AI 视频模型,先看这 5 个维度
| 维度 | 你真正要看什么 | 为什么重要 | 新手优先级 | 进阶优先级 |
| 上手门槛 | 是否有现成网页、预设模板、默认工作流 | 决定你第一次出片要花多少时间 | 很高 | 中 |
| 画质上限 | 运动质量、角色稳定、细节和风格一致性 | 决定成片能否拿去发布或交付 | 高 | 很高 |
| 控制能力 | 镜头、关键帧、角色参考、视频修改 | 决定你能不能把“灵感”变成“可控镜头” | 中 | 很高 |
| 音频能力 | 是否支持对白、音效、口型或表演驱动 | 决定是否能减少后期补流程 | 中 | 高 |
| 本地化能力 | 是否可在本地/私有环境运行,是否好接 ComfyUI 或 Diffusers | 决定长期成本、数据控制和工程扩展 | 低 | 很高 |
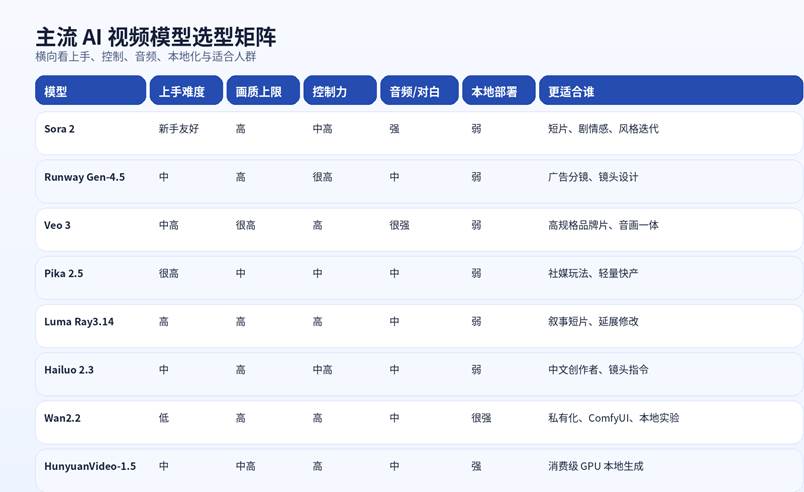
图 1:主流 AI 视频模型选型矩阵
三、主流 AI 视频模型推荐:按场景来选
1. Sora 2:适合“先有感觉,再做迭代”的创作者
如果你最在意的是电影感、物理真实感,以及从一个初稿继续往下修改的体验,Sora 2 仍然是很值得优先体验的一条路线。它的强项不是堆复杂参数,而是让你用较自然的语言先得到一个接近想法的版本,再通过 Re-cut、Remix、Blend 这类编辑能力,逐步把视频修到更贴近你要的方向。
- 更适合:短剧情、氛围片、世界观概念片、需要多轮改稿的内容团队。
- 优势:Sora 2 官方强调更强的物理准确性、真实感与可控性,并支持同步对白和音效;Sora 编辑器则提供 Re-cut、Remix、Blend 等继续加工能力。
- 注意点:如果你的诉求是精确到“表演驱动”“口型绑定”或工程化批量接入,就要结合别的工具一起用。
2. Runway Gen-4.5 + Act-Two:适合“我要控制镜头和表演”的制作型用户
Runway 的优势在于它更像一个面向制作流程的视频工作台,而不是单一生成器。Gen-4.5 强在复杂提示理解、镜头编排和运动质量,适合做广告感、分镜感更强的镜头;Act-Two 则把“表演驱动 + 角色输入”这条链路补齐了,特别适合做人物、角色和表演类镜头。
- 更适合:品牌短片、广告提案、分镜验证、角色演出镜头。
- 优势:Gen-4.5 支持文本到视频和图生视频;Act-Two 支持用 driving performance 驱动角色,最长可到 30 秒,并支持手势控制与换声。
- 注意点:Runway 的能力很强,但也意味着它更像制作工具,真正吃到红利的人通常愿意多做几轮测试和调整。
3. Veo 3:适合“要更高规格、还想要音频”的团队
如果你的重点是更高规格的输出、原生音频/对白,以及面向品牌和商业项目的严肃交付,Veo 3 是非常值得关注的路线。Google 官方文档把它定位为可生成带音频的视频模型,支持 720p、1080p 和 4K,以及 4、6、8 秒长度;在 Vertex AI 里,它还处在更偏企业和开发者友好的交付语境中。
- 更适合:品牌宣传片、企业创意团队、想从实验走向商用流程的团队。
- 优势:官方文档明确写到 Veo 支持音频和对白,且有 Vertex AI 与 Flow 两种典型入口。
- 注意点:相较于一些面向大众的网页产品,Veo 更像“高规格平台能力”,理解成本与接入门槛会更高一些。
4. Pika 2.5:适合“社媒快产、玩法导向”的新手
Pika 的价值在于它特别容易上手,而且把很多高频玩法做成了功能入口。比如 Pikascenes、Pikadditions、Pikaswaps、Pikatwists、Pikaframes,以及把音频驱动表情做得更直观的 Pikaformance。对于图文运营、小团队和短视频创作者来说,这种“能快速试、能快速发”的节奏非常重要。
- 更适合:小红书、TikTok、短视频账号、轻量营销内容。
- 优势:Pika 2.5 提供 5s、10s 乃至更长的 Pikaframes 路线,Pikaformance 则面向音频驱动表情和表演。
- 注意点:它的强项是快与有趣,不一定是所有复杂叙事场景下的最终上限。
5. Luma Ray3.14:适合“想做延展、修改和角色连续性”的创作者
Luma 的 Dream Machine 很适合那些已经不满足于“生成一个片段”,而是希望把片段接起来、改起来、延展起来的人。Ray3.14 在官方用户指南里把自己的定位说得很清楚:更快、更便宜、更稳定,并且覆盖文本生视频、图生视频、Keyframes、Video-to-Video、Modify Video 等全链路。
- 更适合:连续短片、系列内容、需要修改现有素材的创作者。
- 优势:Ray3.14 支持 Modify Video、Keyframes、Loop、延展到更长视频;Ray3 Modify 还能结合角色参考图控制视频修改。
- 注意点:它非常适合“二创式制作”,也就是先有草稿或参考,再不断修到更像最终成片。
6. Hailuo 2.3 / 02:适合中文创作者和镜头指令党
Hailuo 的优势在于它一直在强化镜头控制、动作表现和效率路线。MiniMax 的官方 API 文档里把 Hailuo 2.3 描述为在身体动作、表情、物理真实感和提示遵循上都有突破;Hailuo 02 则强调更高分辨率、10 秒时长和更强提示遵循。对于中文创作者来说,它往往是一个值得重点测试的高性价比路线。
- 更适合:中文创作者、镜头语言比较明确的导演型用户。
- 优势:镜头命令语法、图生视频和更强动作表现,使它在“命令式创作”上比较有吸引力。
- 注意点:不同版本在速度、质量和入口上会有差异,正式入生产前最好固定版本和模板。
7. Wan2.2:适合“我需要本地部署,还想保留较强能力”的团队
如果你已经进入到 ComfyUI、Diffusers 或私有化工作流,Wan2.2 是目前非常值得认真看的开源视频路线。官方公开仓库显示,Wan2.2 同时覆盖 Text-to-Video、Image-to-Video、Speech-to-Video,并提供 480P / 720P 路线;其中 TI2V-5B 模型明确支持 720P、24fps,并把单卡消费级 GPU 作为可行目标之一。
- 更适合:需要本地部署、工作站创作、私有化演示和研究实验。
- 优势:开源、生态活跃、可接工作流工具,且能力覆盖面较全。
- 注意点:真正的门槛不在“模型能不能跑”,而在你是否有足够的显存、耐心和工程环境来把它跑顺。
8. HunyuanVideo-1.5:适合“想要更轻量、又不想完全牺牲质量”的本地路线
HunyuanVideo-1.5 的亮点在于它把“本地视频生成”往更轻量的方向推进了一大步。腾讯开源仓库把它定位为只有 8.3B 参数、可以在消费级 GPU 上跑起来的高质量视频模型,并给出了 14GB 显存起步、支持 480P / 720P 与 1080P 超分的说明。对不少个人工作站用户来说,这条路线比一味追求更大的参数规模更实际。
- 更适合:本地实验、技术创作者、预算有限但希望掌握视频生成链路的人。
- 优势:参数量更轻、对消费级 GPU 更友好,并且已经有 Diffusers、ComfyUI 等社区支持。
- 注意点:轻量不等于零门槛。你仍需要处理依赖、显存、推理时长和后处理问题。

图 2:从新手到进阶的 4 条上手路线
四、如果你现在就要选,一个最省时间的判断方法
| 建议做法 先按“内容目标”选模型,而不是先按名气选模型。要社媒快产,先从 Pika 或 Sora 起步;要镜头和表演控制,优先 Runway;要高规格和音画一体,测试 Veo;要改视频和延展镜头,重点试 Luma;要本地化和私有化,再考虑 Wan2.2 与 HunyuanVideo-1.5。 |
对新手来说,最常见的误区是把所有模型一起试一遍,结果每个都只试到了皮毛。更高效的方法是:先确定一个主要发布场景,再给自己选一条主路线和一条备选路线。比如做小红书与短视频账号,主路线可以是 Pika / Sora,备选是 Luma;做品牌提案或商业镜头,主路线可以是 Runway / Veo,备选是 Sora。
对进阶用户来说,真正拉开差距的不是模型名字,而是你有没有稳定模板:固定的提示词骨架、固定的角色参考图、固定的画幅与长度、固定的后期处理方法。一旦模板定住,同一模型的可用率通常会明显提升。
五、4 个容易踩坑的地方
- 不要一开始就追求长视频。多数模型先从 5 到 10 秒的高命中片段开始,会比直接求全更稳。
- 不要同时改太多变量。角色、场景、镜头、风格最好一次只重点调整一到两项。
- 不要忽视后期。很多时候真正可发布的结果,来自“AI 初稿 + 简单剪辑 + 字幕/配乐/调色”的组合。
- 不要把开源模型想得太轻松。本地部署的真正成本,往往是显存、时间、环境和维护。
六、可直接套用的 AI 视频提示词结构
不管你用哪一家模型,提示词只要把“主体、场景、动作、镜头、光线、节奏、约束”这几层写清楚,整体命中率通常都会更高。特别是想要角色稳定时,必须把外观锚点、服装、色调和镜头约束写得更清楚。

图 3:通用 AI 视频提示词模板
七、结论:不要只问“谁最好”,要问“谁最适合你的下一条内容”
如果把 2026 年的 AI 视频模型市场浓缩成一句话,那就是:闭源产品越来越像完整工作台,开源路线越来越像可配置引擎。前者解决的是“更快做出好内容”,后者解决的是“更深接入自己的生产线”。
所以,对大多数内容创作者来说,最实用的路径通常不是二选一,而是两条线同时准备:在线工具负责快速试错和快速出片,本地或开源路线负责中长期能力储备。当你既能快,又能控,AI 视频才真正进入可持续生产阶段。
信息说明与参考来源
本文以 2026 年 3 月 30 日前可访问的官方公开页面为准,重点参考 OpenAI、Runway、Google Cloud / Flow、Pika、Luma、MiniMax、Wan 与腾讯混元相关文档。由于模型版本迭代较快,定价、分辨率、时长和入口后续可能调整,发布前建议再次核对官方页面。
- OpenAI:Sora 2 发布页、Sora 帮助文档、OpenAI 开发者定价页
- Runway:Gen-4.5 与 Act-Two 官方帮助文档
- Google:Veo / Vertex AI 文档与 Flow 官方页面
- Pika:官网与定价页
- Luma:Ray3.14 / Dream Machine 用户指南
- MiniMax:Hailuo API 文档
- Wan:GitHub 与 Hugging Face 官方页面
- Tencent Hunyuan:HunyuanVideo-1.5 GitHub 官方仓库
