
摘要
在AI工具开发和编程辅助领域,基于本地环境的上下文智能记忆系统能有效平衡效率和隐私。本文以开源项目rainman为例,介绍如何部署和使用本地AI上下文记忆系统,帮助开发者实现无需远程调用的智能编程辅助,提高开发协同和信息管理效率。
适用人群
本教程适合具备中级Python及AI工具开发经验的程序员、AI工具开发者,以及对本地AI辅助系统感兴趣的技术爱好者。尤其适合关注数据隐私、希望减少对云端依赖的开发环境搭建者。
核心功能解释
rainman 简介
rainman是一个基于Python开发的上下文记忆系统,支持本地数据存储和智能信息检索,能够在AI辅助开发中实现对上下文信息的持续管理和调用,提升模型对历史交互的记忆能力。
主要功能模块
- 本地存储引擎:支持SQLite或轻量级KV数据库存储上下文数据
- 智能检索模块:结合向量搜索实现快速相关上下文调用
- 接口适配层:支持与主流AI语言模型集成(如OpenAI GPT系列)
- 安全与隐私保障:所有数据均保存在本地,防止外部泄漏
准备工作
- 系统环境:确保Windows、Linux或MacOS系统支持 Python 3.8 及以上
- Python环境搭建:推荐使用virtualenv创建独立环境
- 安装依赖库:通过pip安装rainman及必要的支持库
- 获取rainman源码:从 官方GitHub仓库 克隆项目代码
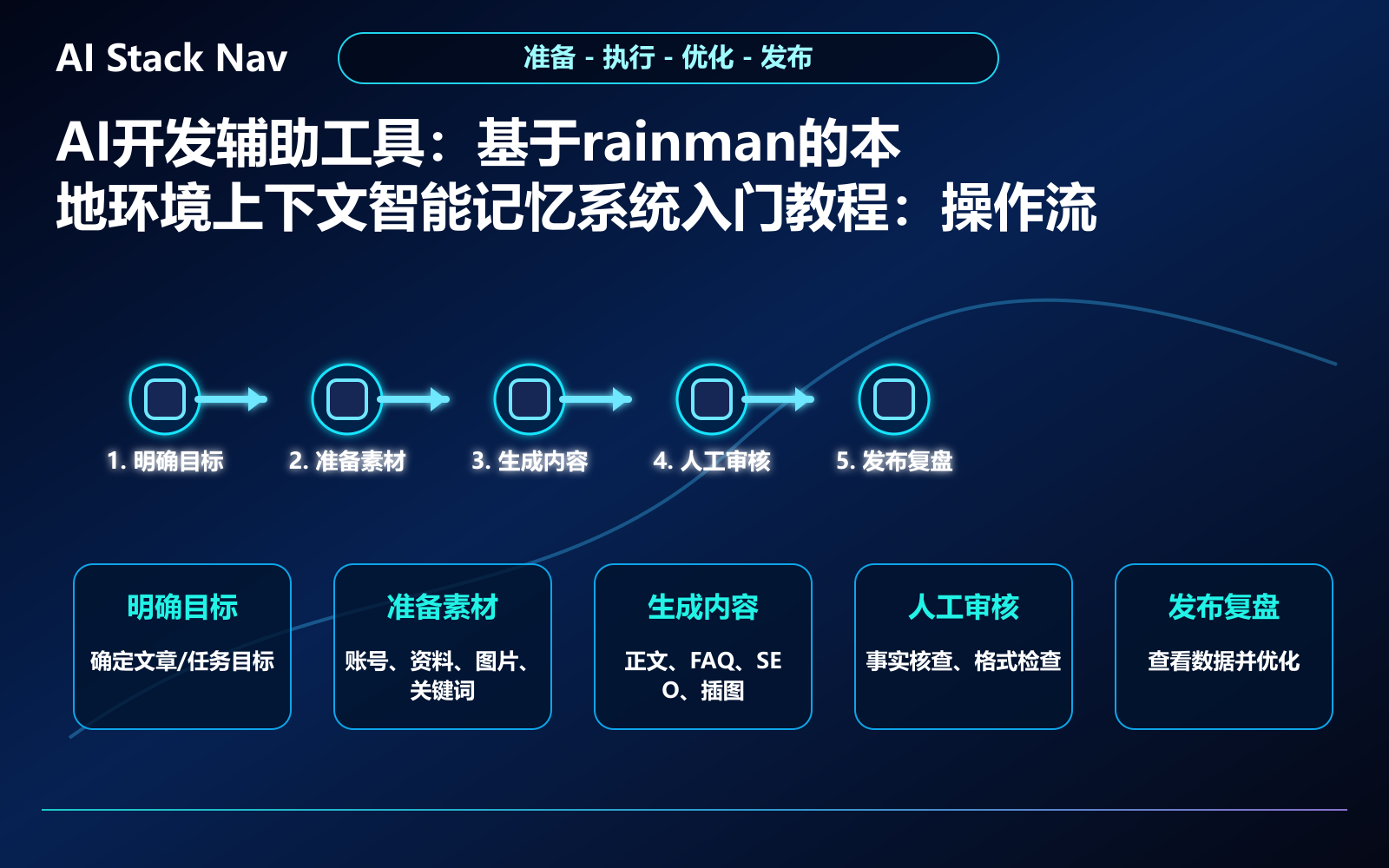
分步骤操作流程
步骤1:安装与配置
在终端执行以下命令部署rainman:
git clone https://github.com/yan-yanko/rainman.git cd rainman python -m venv venv source venv/bin/activate # Windows使用 venv\Scripts\activate pip install -r requirements.txt
步骤2:初始化本地数据库
运行初始化脚本,创建上下文存储数据库:

python initialize_db.py --db-path ./rainman_context.db
步骤3:集成AI模型接口
修改配置文件 config.yaml,指定本地模型或API调用参数:
model: type: gpt-3.5 api_key: YOUR_API_KEY_HERE # 本地模型替换为路径或服务地址
步骤4:启动上下文记忆服务
执行主程序,进入交互环境:
python run_rainman.py --db-path ./rainman_context.db
典型使用场景
| 场景 | 难度 | 适用对象 |
|---|---|---|
| 代码开发辅助上下文记忆 | 中级 | Python开发者、AI工具研发团队 |
| 本地数据保护型AI助手 | 中高级 | 隐私敏感行业研发人员 |
| 离线模型上下文管理 | 高级 | AI模型调优工程师 |
常见错误和解决方法
- 依赖安装失败:确认Python版本符合要求,pip是否升级至最新。推荐先执行
pip install --upgrade pip。 - 数据库初始化错误:检查数据库路径是否有写权限,重复初始化会导致文件锁冲突。
- 模型接口调用异常:确认API密钥正确,或本地模型路径配置无误。
- 上下文检索延迟:尝试调整向量搜索索引参数,避免数据过大导致性能瓶颈。
进阶技巧
定制本地存储引擎
根据项目需要,可替换默认SQLite为更高效的redis或自定义KV存储,通过扩展接口实现更快上下文访问。
优化向量数据库
集成Faiss或Annoy等高性能向量搜索库,提高上下文检索速度与准确度。
多模型融合
结合rainman上下文管理,灵活调度不同AI模型,满足复杂开发辅助需求。
模板与检查清单建议
- 确定本地环境配置符合需求(Python版本、依赖库)
- 完整测试数据库初始化脚本
- 配置并验证AI模型接口调用
- 启动服务前清理旧缓存文件,避免冲突
- 测试多轮上下文记忆调用效果是否稳定
- 开发文档及时维护,保障团队成员协同
FAQ
1. rainman支持哪些AI模型接入?
rainman支持主流云端API如OpenAI GPT系列,也支持本地部署的轻量级模型,具体请参考配置文档。
2. 数据存储安全如何保障?
所有上下文信息均保存在本地磁盘,且支持加密存储,避免数据被外部访问。
3. 能否实现跨项目共享上下文?
可以通过数据库复用策略或多实例同步实现不同项目间上下文共享。
4. 如何提高检索效率?
建议采用专业向量搜索库,并合理设置索引分片和更新频率。
5. 数据量过大时如何优化?
分层存储和定期清理过期上下文,有助于控制存储和计算负担。
6. 是否支持多语言上下文管理?
rainman设计支持多语言数据存储,但检索效果依赖底层模型语言能力。
7. 如何快速入门rainman?
跟随本文准备环境及安装步骤,结合官方GitHub示例代码实践。
8. rainman是否有社区支持?
项目在GitHub上活跃,开发者社区定期更新功能和收集反馈。
AI开发辅助工具:基于本地环境的上下文智能记忆系统入门教程 的实操补充
为了让读者能够直接把 rainman 应用到真实工作中,下面补充一组更细的落地步骤。建议先用一个低风险任务测试,例如整理资料、生成初稿、总结会议纪要或搭建一个小型自动化流程,再逐步迁移到正式业务场景。

落地前的判断标准
| 判断项 | 建议做法 | 通过标准 |
|---|---|---|
| 目标是否清晰 | 把任务拆成输入、处理、输出三部分 | 任何成员都能复述最终产物 |
| 资料是否完整 | 准备样例、限制条件、参考格式和禁止事项 | AI 不需要反复追问基础背景 |
| 结果是否可验证 | 设置人工审核点和检查清单 | 错误能在发布前被发现 |
推荐执行顺序
- 先定义 AI上下文记忆 本地运行 的使用目标,例如提效、减少重复劳动、优化内容质量或辅助排错。
- 准备一份真实但不敏感的测试材料,避免一开始就处理账号、订单、客户隐私等高风险数据。
- 让 AI 输出第一版结果后,不要直接采用,先检查事实、格式、语气和是否遗漏关键步骤。
- 把可复用的提示词、流程节点和审核标准沉淀为模板,后续每次只替换变量。
- 连续测试三到五个案例,确认稳定后再接入自动化工具或 WordPress 发布流程。
常见风险与优化建议
内容质量检查清单
- 标题是否准确覆盖 AI上下文记忆 本地运行,没有偏离原始选题。
- 步骤是否足够具体,读者能否按顺序复现。
- 是否包含适用场景、限制条件、错误处理和人工审核点。
- 是否避免虚构链接、虚构功能和未经验证的数据。
- 是否保留必要的人工判断,避免把 AI 输出当成最终结论。
如果用于 aistacknav.com 的内容运营,建议把这套流程固定为“选题确认、资料核验、正文生成、图片生成、SEO 补全、人工审核、草稿发布”七个环节。这样既能提高生产效率,也能降低重复草稿、错题跑偏和内容过短的问题。
环境配置与 Docker 工作流
适合阅读安装部署、本地配置、服务器搭建和自动化流程类文章后继续转化。
