

资源与模型 · AI 内容策划专题
做 AI 内容站最值得长期积累的资源库有哪些
把零散网址、官方入口、模板和快照,整理成可持续更新的内容资产。
| 适合站点 AI 工具站 / 资源导航站 / 教程博客 / 行业资讯站 | 文章定位 长期收藏型资源清单 + 资源库搭建方法 | 核心目标 让选题、评测、教程与 SEO 更新更稳定 |
| 这类文章不该只停留在“列网站名单”,更重要的是说明:每一类资源为什么值得长期积累、应该怎样整理、最终能转化成什么内容。 |
一、为什么 AI 内容站一定要有自己的资源库
很多 AI 内容站更新不稳定,不是因为不会写,而是因为资料来源太零散:今天看一篇官方博客,明天记一个 GitHub 仓库,后天又收藏一个模板市场,真正要写文章时却很难快速定位、交叉验证和持续跟进。长期来看,真正有复利价值的,不只是某一篇爆文,而是一套可以不断扩充、反复调用、随时复查的资源库。
对 AI 工具类、工作流类、模型类内容站来说,资源库至少承担四个功能:第一,作为选题雷达,帮助你持续发现值得写的新方向;第二,作为事实底稿,降低介绍产品、对比模型、拆解功能时的信息偏差;第三,作为模板仓库,缩短写教程、做清单、写 SEO 聚合页的准备时间;第四,作为证据留档,帮助你记录版本变化、页面改版与官方口径更新。
| 核心判断|能让你“以后重复使用”的资料,才配进入资源库;只能看一次的链接,最多算临时参考。 |

图 1 最值得长期积累的 8 类资源库
二、最值得长期积累的 8 类资源库
| 资源库类型 | 代表入口 | 为什么值得长期积累 | 更适合产出 |
| 官方文档库 | OpenAI / Anthropic / Gemini | 最接近一手口径,适合核对功能、限制、用法与版本变化 | 产品介绍、参数说明、更新解读 |
| 提示词范式库 | Prompt guide / Cookbook / Skill 包 | 高复用,能持续沉淀结构化写法与任务模板 | 提示词合集、角色模板、输出格式库 |
| 工作流模板库 | n8n / Dify / Notion 模板 | 直接对应落地流程,最容易转化为教程与模板包 | 工作流拆解、模板分享、保姆级教程 |
| 模型与数据集库 | Hugging Face / API 文档 | 帮助你解释“这个模型适合什么、依据是什么” | 模型导航、能力对比、场景推荐 |
| 开源项目追踪库 | GitHub Trending / Awesome | 容易发现新工具,也能跟踪社区热度 | 新工具快报、开源榜单、趋势盘点 |
| 论文观察库 | arXiv / 研究博客 | 适合做前沿栏目与中长期趋势判断 | 论文解读、技术趋势、深度文章 |
| 趋势与选题库 | Google Trends / 用户问题 | 直接服务 SEO 与选题验证 | 关键词拓展、需求清单、主题策划 |
| 归档与证据库 | Wayback / Common Crawl / 截图 | 为版本变化、页面消失、历史对比保留证据 | 时间线梳理、版本对比、事实校验 |
1. 官方文档库:所有介绍型内容的“底稿层”
如果你的网站会写 AI 工具介绍、模型更新、功能差异、价格与使用方式,那么官方文档库一定要排在最前面。OpenAI 提供了 Cookbook 和 Learning Hub 这类偏实践的入口,也有面向开发者的教程与提示词资源;Anthropic 既有 Claude API 文档,也有 Academy 和 prompt engineering 指南;Google 侧则有 Gemini API 与 AI Studio 的官方说明。把这些入口长期归档,比到处搬运二手解读更可靠。[1][2][3][4][5][6]
这类资源最适合沉淀三个字段:一是“这条资料回答了什么问题”,二是“适合写成哪种内容”,三是“下次需要复查的时间点”。例如,一篇 release notes 更适合写成“更新速报”,一份完整文档更适合支撑“新手上手”和“功能拆解”。长期积累后,你会形成一套非常稳定的产品资料底盘。
2. 提示词范式库:把零碎好提示词变成可复用模板
AI 内容站往往不只是介绍工具,还会给用户现成可用的提示词。与其零散收藏,不如按任务类型建立范式库,例如:写作改写、摘要提炼、结构化输出、长文研究、表格整理、图像生成、代码辅助、客服问答、知识库检索等。OpenAI 的 prompting 资源与 Cookbook、Anthropic 的 prompt engineering 概览和 context engineering 文章,都适合作为范式库的来源与参考。[1][2][7]
真正高价值的不是保存一条“神提示词”,而是总结它的共性结构:角色设定、输入变量、输出格式、约束条件、失败补救。这样你以后写“提示词模板大全”“某场景提示词合集”时,几乎不需要从零开始。
3. 工作流模板库:最容易直接变现成教程与模板包
如果你的网站会做实战教程、自动化流程、模板分享,工作流模板库几乎就是现金流入口。n8n 官方文档提供模板库入口,营销自动化分类页当前就展示了数千个现成工作流;Notion Marketplace 的 AI 模板数量也非常庞大。这类平台最大的价值不只是“有模板”,而是能帮你快速观察:大家究竟在用 AI 做什么。[8][9][10]
建议把模板资源按“输入 → 处理 → 输出”三段法重写一遍:输入是什么数据,处理用了哪些 AI 能力,输出落到什么场景。重写之后,你就能很自然地扩写成教程、案例、模板包、注意事项清单。
4. 模型与数据集库:支撑评测、导航与场景推荐
做 AI 内容站时,读者常问的并不是“最新模型是谁”,而是“我该选哪个”。这时候,模型与数据集库就能发挥作用。Hugging Face 既是模型库也是数据集库,其官方博客披露,2025 年平台已增长到 1300 万用户、超过 200 万公开模型与 50 万公开数据集,说明它已经是观察开源 AI 生态的核心入口之一。[11][12][13]
这类资源最好建立统一卡片:模型名称、任务类型、主要卖点、输入输出形式、适用场景、是否开源、链接地址、配套数据集或 Demo。日后你做“模型导航”“某类模型盘点”“入门推荐”时,就能直接调用。
5. 开源项目追踪库:发现新工具最快的雷达
对于 AI 工具站来说,GitHub Trending 和优质 awesome 列表,是找新项目最快的雷达。它们不一定都成熟,但非常适合观察社区注意力在往哪里转移。与此同时,官方 changelog 和 release notes 也值得归档,因为真正长期可跟踪的项目,往往都留下清晰的迭代记录。[14][15][16]
这类资源不建议只记仓库名,最好补一段“它解决什么问题、和哪些现有工具相似、你网站将来可能写成什么栏目”。否则仓库越收越多,后面很难再次利用。
6. 论文观察库:给网站建立“深度内容层”
即使你的网站主要面向普通用户,也应该保留一层论文观察库。原因很简单:AI 行业变化太快,很多概念今天是研究点,几个月后就会成为产品卖点。arXiv 目前已经是一个拥有接近 240 万篇开放学术文章的预印本平台,计算机科学相关的新稿非常密集。[17][18]
论文观察库不必追求面面俱到,更适合建立主题订阅,例如:Agent、RAG、多模态、视频生成、语音合成、浏览器自动化、模型评测、上下文工程等。这样你写趋势稿时,就不会只停留在产品表面。
7. 趋势与选题库:让资源库直接服务 SEO
资源库如果不能反哺选题,就容易变成“好看但难用”的收藏夹。Google Trends 是最基础也最值得长期保存的趋势入口,它可以帮助你观察某个关键词在不同时间、地区与相关主题中的变化。Google 在 2026 年又对 Trends Explore 做了基于 Gemini 的升级,进一步降低了发现相关趋势的门槛。[19][20][21]
建议把趋势与选题库拆成两层:第一层是外部信号,例如搜索趋势、平台热词、官方更新;第二层是内部信号,例如你网站已有文章的搜索词、评论区问题、站内搜索、用户咨询。两层结合,才更容易做出既有热度又有转化潜力的内容。
8. 网页归档与证据库:对比版本变化时特别重要
AI 赛道页面变化极快,价格页会改、功能页会改、文档链接会改、模型支持列表也会改。遇到这些情况,Wayback Machine 与 Common Crawl 这种归档型资源就非常重要。Wayback Machine 已累计保存超过 1 万亿个网页快照;Common Crawl 仅 2026 年 3 月的抓取就覆盖了 19.7 亿个网页,未压缩数据量达 344.64 TiB。[22][23][24]
这类资源尤其适合用来支撑“版本变化”“官网改版”“某功能何时上线”的时间线文章。对内容站来说,它们不仅是资料库,还是事实核验与证据留档工具。
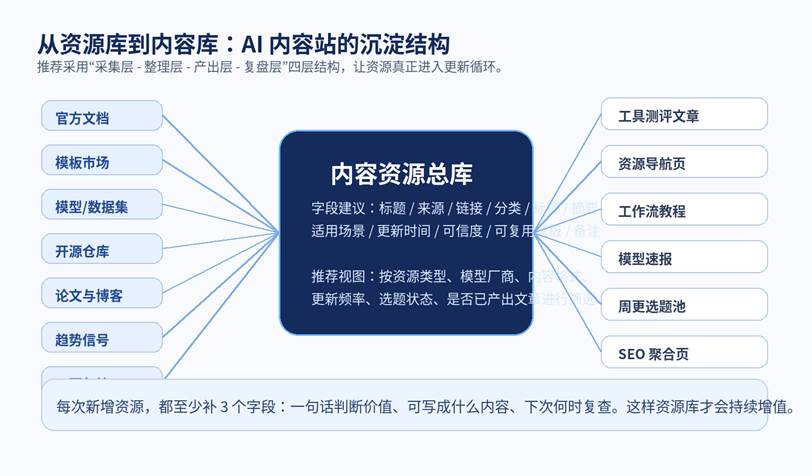
图 2 资源库真正有价值,在于它能持续进入内容生产循环
三、资源库怎么建,才不会越积越乱
最实用的做法不是一上来追求复杂系统,而是先统一字段。无论你用 Notion、Airtable、Obsidian、表格还是本地知识库,建议至少保留以下字段:资源标题、来源网站、原始链接、资源类型、适用场景、50 字摘要、标签、更新时间、可信度、可延展为哪些内容、下次复查时间。
当字段固定后,你就可以建立几个最常用视图:按资源类型查看,适合写站点栏目;按更新时间查看,适合做周更与快讯;按“已产出/未产出”查看,适合补齐内容空档;按模型厂商或产品线查看,适合做聚合页和专题页。
| 字段 | 建议写法 | 为什么要保留 |
| 资源摘要 | 一句话概括这条资料讲了什么 | 以后重看时不用重新打开整篇 |
| 适用场景 | 测评 / 教程 / 导航 / 选题 / 速报 | 决定它会进入哪个内容流程 |
| 可信度 | 官方 / 社区 / 二手整理 / 未核验 | 避免把低可信来源当成事实 |
| 可写内容 | 可扩成哪篇文章或哪个栏目 | 让资源库直接服务产出 |
| 复查时间 | 下周 / 下月 / 有更新再看 | 防止资源长期失效 |
| 最实用的原则|每新增一条资源,至少补三件事:一句摘要、一个适用场景、一个可写内容方向。没有这三项,资源很难进入实际产出。 |
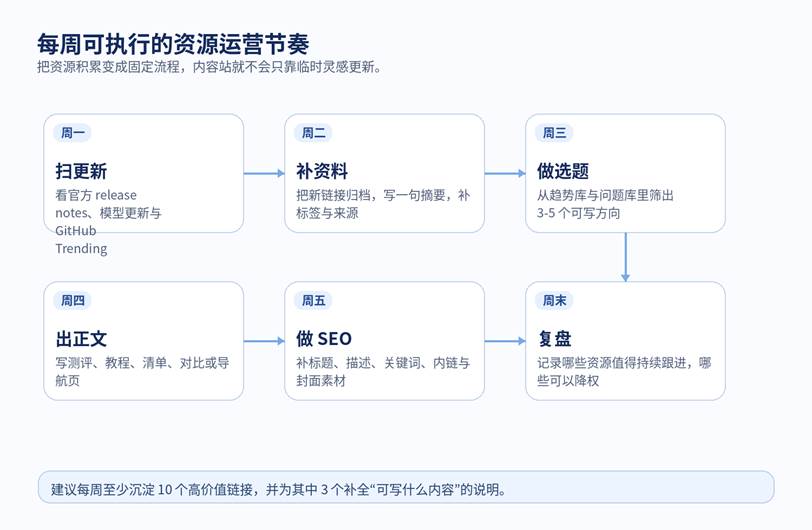
图 3 把资源积累纳入周节奏,内容站更新会明显稳定
四、做资源库最常见的 5 个误区
1. 只收藏,不整理:链接越来越多,但没有摘要、标签和用途说明,后面几乎不会再用。
2. 只看二手解读,不追官方源:转述链条越长,偏差越大,尤其是模型能力、价格、限制与版本变化。
3. 资源类型不分层:官方文档、社区帖子、模板示例、实验论文混在一起,检索效率会迅速下降。
4. 没有“可写内容”字段:资源无法进入选题池,最终就只是收藏夹。
5. 不做复查:AI 赛道变化快,失效链接、改版页面、退役模型都很常见。
五、资源库应该先建哪几个
如果你的网站还在早期阶段,建议先按优先级建立这四类:官方文档库、工作流模板库、趋势与选题库、开源项目追踪库。前两类负责事实与实操,后两类负责持续发现新内容。等站点有了一定体量,再逐步补强模型与数据集库、论文观察库以及归档证据库。
真正成熟的 AI 内容站,不会把资源当成一次性素材,而会把它们做成长期复用的内容基础设施。谁更早建立起自己的资源库,谁就更容易持续更新、更容易做专题、更容易形成差异化。
参考资源与说明
[1] OpenAI Prompting Resource https://academy.openai.com/public/clubs/work-users-ynjqu/resources/prompting
[2] Anthropic Prompt Engineering Overview https://docs.anthropic.com/en/docs/build-with-claude/prompt-engineering/overview
[3] OpenAI Cookbook https://developers.openai.com/cookbook/
[4] OpenAI Learning Hub https://openai.com/business/learn/
[5] Anthropic Academy https://www.anthropic.com/learn
[6] Gemini API Docs / Google AI Studio https://ai.google.dev/gemini-api/docs
[7] Anthropic Context Engineering https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents
[8] n8n Workflow Templates Docs https://docs.n8n.io/workflows/templates/
[9] n8n Marketing Workflows https://n8n.io/workflows/categories/marketing/
[10] Notion Template Marketplace https://www.notion.com/templates
[11] Hugging Face Models https://huggingface.co/models
[12] Hugging Face Datasets https://huggingface.co/datasets
[13] State of Open Source on Hugging Face: Spring 2026 https://huggingface.co/blog/huggingface/state-of-os-hf-spring-2026
[14] GitHub Trending https://github.com/trending
[15] Awesome Generative AI https://github.com/steven2358/awesome-generative-ai
[16] OpenAI / Anthropic Release Notes https://help.openai.com/en/articles/9624314-model-release-notes ; https://docs.anthropic.com/en/release-notes/overview
[17] arXiv https://arxiv.org/
[18] arXiv Computer Science Recent https://arxiv.org/list/cs/recent
[19] Google Trends https://trends.google.com/trends/
[20] Trends Explore https://trends.google.com/explore
[21] Google Blog: Trends Explore with AI https://blog.google/products-and-platforms/products/search/google-trends-explore-with-ai/
[22] Wayback Machine https://wayback.archive.org/
[23] EFF on Internet Archive / 1 Trillion Web Pages https://www.eff.org/deeplinks/2026/03/blocking-internet-archive-wont-stop-ai-it-will-erase-webs-historical-record
[24] Common Crawl March 2026 Archive https://commoncrawl.org/blog/march-2026-crawl-archive-now-available
