

Coze(扣子)实战:从零搭建一个自动抓取热点的微信订阅机器人
从“定时抓取—智能筛选—去重记录—微信推送”四个环节,手把手搭出一个真正能跑的热点订阅机器人。
| 本文适合谁 • 想用 Coze 做自动化内容分发,但还没有工作流经验的新手。 • 想做行业日报、AI 资讯早报、赛道监控、品牌舆情摘要的人。 • 已经会搭智能体,但还没跑通过“定时触发 + 外部数据源 + 微信发布”闭环的人。 |
一、先说结论:这类机器人真正的价值是什么?
很多人做“热点机器人”时,容易把重点放在抓得多不多。真正能长期运行的方案,核心不在“抓”,而在于能不能把海量信息变成高质量、低噪音、持续可读的订阅内容。
• 抓取层:从 RSS、新闻 API、榜单页或自建接口稳定拿到原始数据。
• 理解层:让大模型做摘要、分类、重写标题和重要性评分,而不是直接生搬硬贴。
• 治理层:通过数据库去重、过滤营销稿、限制单次推送数量,避免把用户“刷烦”。
• 分发层:把结果投递到微信订阅号,让读者在熟悉的入口里接收信息。
| 一个最小可用目标(MVP) • 每天 3 次自动抓取。 • 每次抓取 20 条原始热点。 • 筛出 3~5 条真正值得看的内容。 • 自动记录已推送链接,防止重复发送。 |
二、为什么用 Coze(扣子)来做?
从平台能力看,扣子编程已经具备做这类自动化机器人的关键积木:低代码工作流、定时触发器、HTTP 请求节点、代码节点、数据库,以及发布到微信订阅号。对于不想自己搭服务器的新手来说,这样的门槛明显更低。
| 能力模块 | 你会怎么用 | 在本教程里的作用 |
| 定时触发器 | 固定时间 / 间隔触发 | 每天定时执行“抓取热点 → 处理 → 推送” |
| HTTP 请求节点 | 请求外部 API 或 RSS 转 JSON 服务 | 获取原始热点内容与链接 |
| 代码节点 | Python / JavaScript 清洗数据 | 统一字段、生成哈希、过滤噪音 |
| 大模型节点 | 摘要、改写、打分、归类 | 把原始信息变成可读的订阅内容 |
| 数据库 | 查询 / 插入 / 更新 | 记录已推送内容、做去重与日志 |
| 微信订阅号发布 | 发布到公众号渠道 | 让用户在微信里收消息并与机器人互动 |
三、上线前你要先弄清的 4 个边界
• 第一,扣子能自动拉数据,但数据源本身是否稳定,取决于你接的 RSS、API 或网站。
• 第二,公众号推送不是“群发文章”,而更像把机器人接到订阅号场景里,让用户在公众号中向机器人提问或接收自动整理结果。
• 第三,热点机器人最容易翻车的不是模型,而是“重复推送、抓到营销稿、接口超时、格式脏乱”。
• 第四,越接近生产环境,越建议把外部数据源做成自己可控的统一接口,而不是直接依赖多个野生热榜。
| 信息说明 • 本文基于 2026 年 4 月公开资料整理,重点参考扣子官方文档中关于定时触发器、HTTP 请求节点、代码节点、数据库与微信订阅号发布的说明。 • 由于第三方热点榜接口、RSS 源、公众号审核规则都可能变化,真正上线前请以你自己的数据源稳定性和微信侧配置结果为准。 |
四、整体架构:先把流程想对,再去搭节点
建议你把这个机器人拆成两层:一层是“外部数据抓取层”,另一层是“Coze 编排与输出层”。这样做的好处是,一旦将来你要把 RSS 换成自建接口、把订阅号换成企业微信,整体结构不用重搭。
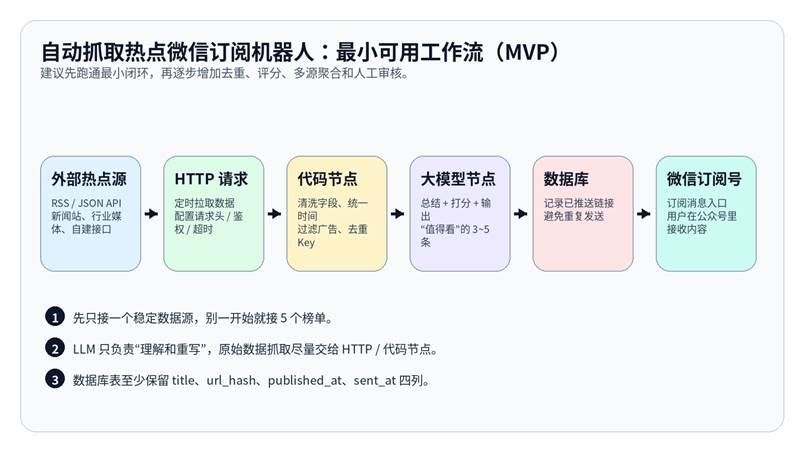
图 1:自动抓取热点微信订阅机器人最小可用工作流
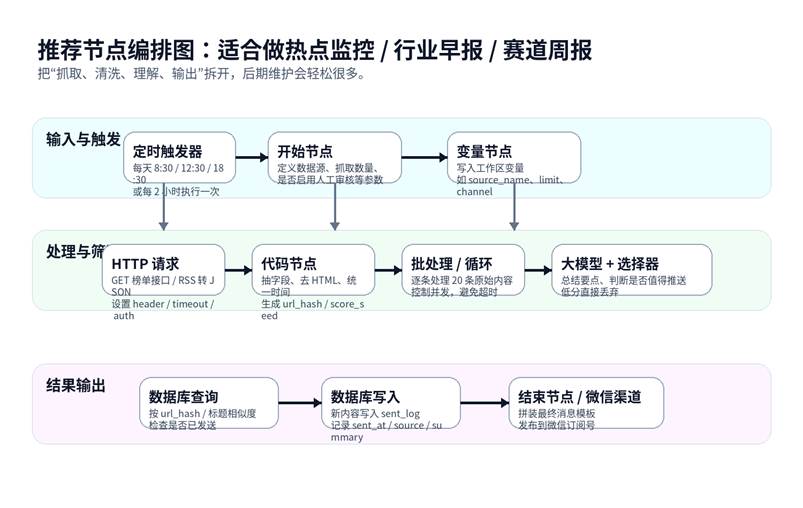
图 2:推荐的节点编排图,把输入触发、处理筛选、结果输出三层拆开
五、准备工作清单:别急着拖节点,先把账号和材料备齐
| 准备项 | 是否必需 | 你要准备什么 | 备注 |
| 扣子账号与工作空间 | 必需 | 可创建低代码智能体 / 工作流的空间 | 建议单独为“内容自动化”建一个工作空间 |
| 微信订阅号 | 必需 | 公众号后台、AppID、必要的微信侧配置 | 一套机器人最好先只接一个订阅号 |
| 热点数据源 | 必需 | RSS、JSON API、或你自己的聚合接口 | 优先选择稳定、更新频率可预测的数据源 |
| 数据库表 | 强烈建议 | sent_log / source_log / error_log | 先只建 sent_log 也能跑通 MVP |
| 内容模板 | 强烈建议 | 推送格式、标题风格、摘要长度规则 | 避免每次输出风格飘忽 |
| 审核策略 | 可选 | 自动发 / 人工确认后发 | 新手建议先人工确认,再逐步放开 |
六、实操步骤:从 0 到 1 搭一个最小可用版本
步骤 1:新建一个低代码智能体,并把角色定义清楚
不要上来就让模型“自由发挥”。你要先定义机器人到底干什么:它不是百科问答,也不是泛聊天,而是一个面向微信读者的“热点筛选与摘要助手”。
| 推荐角色定义 • 你是一个中文热点订阅编辑,负责从抓取结果中选出最值得读者花时间看的内容。 • 输出要求:不夸张、不标题党、不制造焦虑;优先保留来源、时间、核心结论和链接。 • 每次最多输出 5 条;每条用“标题 + 1 句摘要 + 来源 + 链接”的结构。 |
步骤 2:先接一个数据源,跑通闭环再扩展
对于零基础用户,我更建议你先接一个 JSON 结构清晰的数据源,而不是一开始就处理原始 HTML。最常见的做法是:用 RSS 转 JSON 服务,或者自己做一个简单热点聚合接口。
• 最省心:你已有一个返回 JSON 的内部接口。
• 第二选择:用 RSS 源 + 中转服务,把 XML 转成结构规整的 JSON。
• 最不建议新手直接做:在工作流里硬抓网页 HTML 再解析。页面一改版,你的流程就断。
步骤 3:配置 HTTP 请求节点,把原始热点取回来
HTTP 节点里重点不是“能不能请求成功”,而是请求结果是否足够稳定、字段是否足够规整。你最好要求返回的数据至少包含 title、url、source、published_at、content 或 summary。
| 配置项 | 推荐写法 | 说明 |
| Method | GET | 先用 GET 拉公开热点源,最容易排查 |
| Timeout | 8~15 秒 | 太短容易误判失败,太长会拖慢整条链路 |
| Limit | 10~20 条 | MVP 不要一次抓 100 条,调试成本太高 |
| Header | User-Agent / Authorization | 按你接入的数据源要求填写 |
| Response | JSON 数组 | 越结构化,后面越好处理 |
步骤 4:用代码节点清洗数据,别把脏数据扔给大模型
代码节点很适合做四件事:字段统一、空值过滤、时间格式转换、生成去重键。你可以把这里理解为“轻量 ETL”。只要清洗得好,后面的大模型节点和数据库节点都会变得很稳定。
Python 示例
| def handler(params): seen, out = set(), [] for item in params.get(“items”, []) or []: title = (item.get(“title”) or “”).strip() url = (item.get(“url”) or “”).strip() if not title or not url: continue key = f”{title[:40]}|{url}”.lower() if key in seen: continue seen.add(key) out.append({“title”: title, “url”: url, “dedupe_key”: key}) return {“cleaned_items”: out[:20]} |
步骤 5:把“是否值得推送”交给大模型,而不是只做机械摘要
这一层的关键不是让模型复述原文,而是让它扮演编辑:理解信息、判断重要性、压缩表达、统一格式。
Prompt 示例
| 你是一个科技/行业热点编辑。请对输入的候选热点逐条处理: 1. 判断是否值得推送给订阅读者,给出 importance_score(1-10)。 2. 如果低于 7 分,标记为 drop 并说明原因。 3. 如果高于等于 7 分,请输出: – rewrite_title:更清晰但不过度夸张的中文标题 – short_summary:50~80 字中文摘要 – angle:这条内容为什么值得看(机会 / 风险 / 产品变化 / 商业信号) 4. 保留原始来源与 URL。 5. 输出 JSON。 |
• 新手常见错误:让模型直接“总结所有内容”,结果要么太长,要么每条都像营销文。
• 更稳的做法:先在代码节点完成清洗,再在大模型节点做评分与重写。
• 如果你需要更稳的可读性,可以把“大模型评分”和“最终排版”拆成两个节点。
步骤 6:用数据库节点做去重,不要只靠标题判断
热点类内容最怕重复推送。只看标题会漏掉“同一链接换标题”的情况,所以更建议在数据库里记录 dedupe_key 或 url_hash。
| 字段 | 类型 | 作用 | 建议 |
| dedupe_key | Text | 唯一去重键 | 标题前 40 字 + URL,或直接存哈希 |
| title | Text | 原始标题 | 便于人工排查和回溯 |
| sent_at | Datetime | 推送时间 | 用于做 24 小时 / 7 天规则 |
| source | Text | 来源站点 | 方便观察哪个来源质量更高 |
| status | Text | sent / dropped / error | 建议至少保留 3 种状态 |
步骤 7:拼装最终推送模板,别直接扔原始 JSON
最终推给微信订阅读者的内容,需要更接近“栏目”而不是“日志”。推荐每次只输出 3~5 条,结构统一,读者才会形成阅读习惯。
| 推荐消息模板 • 【今日 AI / 行业热点】 • 1)标题 一句摘要 来源:XX 链接:URL • 2)标题 一句摘要 来源:XX 链接:URL • 末尾加一句固定引导:回复“更多”获取完整榜单。 |
步骤 8:发布到微信订阅号,并先用“小流量”测试
发布前你需要在微信侧准备好订阅号相关配置,再回到扣子发布页面进行渠道配置。新手不要一上线就全量开放,先拿自己的号、同事号、小范围读者做测试,观察一周再扩量。
• 先测消息格式:在微信里是否容易读、链接是否能打开、是否太长。
• 再测节奏:一天 1 次通常最稳;如果读者很垂直,可以提升到 2~3 次。
• 最后测内容质量:读者真正愿意点开的,通常不是“最多”的内容,而是“最筛过”的内容。
七、进阶优化:把机器人从“能跑”升级成“好用”
| 优化方向 | 怎么做 | 收益 |
| 多源聚合 | 接 2~3 个不同来源,再统一排序 | 减少单一来源偏差 |
| 人工审核开关 | 加一个变量控制“自动发 / 人工确认后发” | 新账号更稳,减少翻车 |
| 主题分类 | 按 AI、出海、电商、融资、产品更新分类 | 读者更容易快速浏览 |
| 异常日志 | 把接口失败和空数据写入 error_log | 更容易定位是源头问题还是工作流问题 |
| 周报模式 | 每天入库、每周统一汇总 | 适合 ToB、投资、研究类场景 |
八、常见报错与排查顺序
• HTTP 节点报错:先确认数据源本身能否正常访问,再看 header、鉴权、超时和返回格式。
• 代码节点无输出:优先打印输入样例,确认 items 是数组而不是字符串;必要时先加 JSON 反序列化。
• 模型输出不稳定:别让模型直接处理过多脏字段;缩短上下文,给明确 JSON 输出要求。
• 重复推送:检查数据库写入是否发生在真正发送之后;确认 dedupe_key 是否稳定。
• 微信侧无法联通:优先检查公众号侧配置、回调地址、AppID 信息和发布渠道选择是否正确。
九、合规与运营提醒:这部分很多人会忽略
• 抓取第三方热点源前,先看对方是否提供公开 RSS / API,以及是否允许商用或再分发。
• 不要把整篇原文搬运到订阅号,尽量输出“摘要 + 链接 + 观点”,把流量导回原始来源。
• 如果你的机器人会涉及证券、医疗、教育、政策类信息,务必增加人工审核。
• 稳定更新比高频轰炸更重要。你真正运营的是一个“信息栏目”,不是一个抓取脚本。
十、FAQ
1. 小白能不能不写代码?
可以,但我仍建议保留最少量的代码节点。因为热点数据一旦来源变多,纯拖拽方式做字段清洗和去重会越来越难维护。
2. 我一定要接 RSS 吗?
不一定。最理想的是你自己控制的 JSON 接口;RSS 更适合做快速验证,特别是媒体类内容源。
3. 为什么不建议一开始就抓很多榜单?
因为你一旦遇到报错,根本分不清是哪个源的问题。先用单源跑通,再加第二个、第三个,才是正确顺序。
4. 订阅号场景适合什么内容?
适合日报、行业快讯、产品更新、政策摘要、垂直赛道监控。越垂直,读者越容易形成阅读习惯。
5. 如果我要做完全自动发,最少要加哪些保护?
至少加:接口失败兜底、数据库去重、低分内容丢弃、敏感词与高风险内容人工审核。
十一、相关阅读
• 《OpenClaw 是什么?为什么 2026 年大家都在聊 AI Agent“龙虾”生态》
• 《提示词工程(Prompt Engineering):让 AI 听懂人话的 5 个万能模板》
• 《Notion AI 深度集成:打造你的个人智能知识库》
• 《AI 浏览器会不会成为下一个超级入口?从搜索到执行的产品演进》
| 一句话总结 • 想把 Coze 做成一个真正有用的微信订阅机器人,关键不是把“抓取”做复杂,而是把“筛选、去重、重写、节奏”做扎实。先跑通一个稳定数据源,再逐步升级成多源自动化内容系统。 |
会员充值与订阅排查资料
适合阅读会员充值、订阅购买、权益对比和支付问题类文章后继续转化。
