

小白必看:本地部署 DeepSeek 需要什么样的电脑配置?
2026 版入门指南|适合网站发布的长文稿
关键词:DeepSeek、本地部署、显存、统一内存、电脑配置、蒸馏模型
很多人第一次说“我要本地部署 DeepSeek”,脑子里想的是满血版 DeepSeek-R1;真到买电脑时,又发现显卡、显存、内存、硬盘、量化、上下文这些词全挤到一起,越看越乱。
这篇文章的目标只有一个:把事情讲明白。你不需要先懂模型论文,也不需要先懂 CUDA、ROCm、GGUF。只要先分清“你到底想跑哪一种 DeepSeek”,配置选择就会立刻清晰很多。
| 先给结论 对绝大多数小白来说,“本地部署 DeepSeek”真正适合入手的不是满血版 R1 / V3,而是 DeepSeek-R1-Distill 7B、8B、14B,最多再往上看到 32B。普通消费级电脑最重要的不是 CPU 跑分,而是显存(或 Apple Silicon 的统一内存)够不够。 |
一、先把误区拆掉:你想跑的 DeepSeek,可能根本不是同一种
DeepSeek 这几个名字,经常被混着说:DeepSeek-V3、DeepSeek-R1、DeepSeek-R1-Distill。对于新手来说,它们的部署难度完全不是一个量级。
| 类别 | 你会听到的名字 | 适合谁 | 现实建议 |
| 满血大模型 | DeepSeek-V3、DeepSeek-R1 | 企业、研究、服务器玩家 | 普通家用机不建议直接冲;更多是云端、集群或工作站路线 |
| 蒸馏版 | DeepSeek-R1-Distill 1.5B / 7B / 8B / 14B / 32B / 70B | 个人用户、本地爱好者、开发者 | 大多数小白真正该看的,是这条路线 |
| 桌面体验层 | Ollama、LM Studio、llama.cpp、vLLM 等 | 想快速跑起来的人 | 先选好模型,再选工具;不要反过来 |
一句人话总结:
• 你不是在问“DeepSeek 能不能本地部署”,而是在问“我这台电脑,能跑哪一档 DeepSeek,而且速度还像回事”。
• 如果你的目标只是本地聊天、写作、翻译、轻度代码补全,优先看蒸馏版 7B / 8B / 14B;如果你一上来就盯着 DeepSeek-R1 本体,多半会把预算花错地方。
二、为什么说“满血版”不适合大多数普通电脑
很多人以为,只要模型开源,就意味着家里电脑也能轻松跑。事实上,开源不等于低门槛。
满血版 DeepSeek-R1 / V3 的体量非常大。真正麻烦的不只是模型文件有多大,而是推理时需要的显存、内存带宽、并行方案以及运行框架配套。
| 你真正要记住的一句话 “能加载”不等于“能好用”。有些电脑确实能靠 CPU 或超低速方式把模型塞进去,但如果一秒只出 1~2 个 token,或者一开长上下文就频繁爆内存,体验上仍然等于不可用。 |
所以本文所有配置建议,都会围绕“可用、能用、用着不烦”这个标准来写,而不是围绕“理论上能启动”。
三、本地部署最关键的 5 个硬件指标
1)显存 / 统一内存
这是最核心的指标。Windows / Linux 台式机重点看独立显卡的 VRAM;Mac 重点看统一内存。模型越大、上下文越长、生成越复杂,对这一项要求越高。
2)系统内存(RAM)
即使主力由 GPU 推理,系统内存仍然承担模型缓存、上下文、程序本身以及数据搬运压力。想跑得稳,不要把 RAM 配得太极限。
3)硬盘空间
模型文件、量化版本、缓存和环境都要占空间。你今天只下载一个模型,明天往往就会试第二个、第三个,所以 SSD 最好别太小。
4)CPU
CPU 当然重要,但对大多数本地 LLM 用户来说,它不是第一购买指标。只要不是太老的低压 U,通常都不该优先于显卡和内存。
5)系统与生态
新手优先考虑兼容性最成熟的路线。NVIDIA + Windows / Linux 台式机,以及 Apple Silicon Mac,是目前最容易少踩坑的组合。
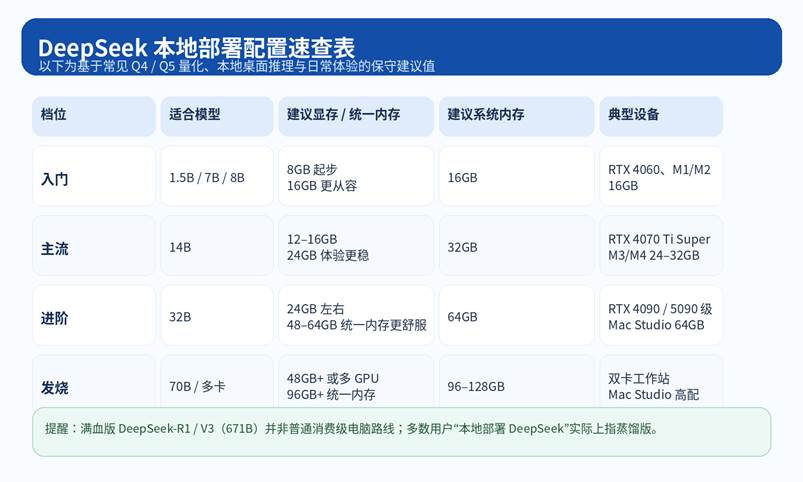
图 1|按常见量化与桌面端体验整理的配置速查表
四、不同模型档位,电脑配置到底该怎么买
1)入门档:1.5B / 7B / 8B
这一档最适合第一次接触本地模型的人。它的优势是部署快、占用低、容错高,适合先把流程跑通。
如果你只是想本地问答、写作润色、简单表格分析、基础代码片段生成,这一档就已经能覆盖相当多场景。
• Windows / Linux:有 8GB 显存就可以开始玩,16GB 会明显舒服很多。
• Mac:16GB 统一内存可以入门,但更建议至少 16GB 以上,不要同时开太多重应用。
• 硬盘:建议预留 50GB 以上,别只给模型留 10GB。
2)主流档:14B
如果你希望模型的逻辑更完整、长回答更稳、写代码更像样,14B 往往是一个非常合理的升级点。它不像 32B 那样直接把预算推高,但体验会比 7B / 8B 更接近“可长期用”的状态。
这时候你就不该再把电脑按“办公本”标准来买了,而要按“轻度 AI 工作站”标准来配。
• Windows / Linux:12~16GB 显存更合适,系统内存最好 32GB。
• Mac:24GB 或 32GB 统一内存更稳。
这档位非常适合想认真把本地模型用进日常工作流的人。
3)进阶档:32B
32B 已经不是“小打小闹”的级别了。你会明显感觉到它更接近真正可依赖的推理工具,但代价也来了:显存、内存、硬盘、散热和预算都会一起上升。
• 对于 Windows / Linux 用户,这档位通常意味着你最好直接冲 24GB 级别显卡,系统内存拉到 64GB;对 Mac 用户来说,48GB 或 64GB 统一内存会更从容。
如果你还没跑过 7B / 14B,就不建议把 32B 当作第一台机器的目标。原因很简单:一旦部署流程卡住,你很难判断问题到底出在模型太大,还是环境没装对。
4)发烧档:70B 及以上
这一档已经接近“工作站 / 多卡 / 高统一内存”的消费级上限区。你当然可以追求,但不适合把它写进“小白第一台 DeepSeek 本地机”的购物清单。
更关键的是,很多人嘴上说想跑“70B 甚至满血 R1”,实际每天的使用场景却仍然是:写文章、改文案、总结资料、问点代码。这时候花大钱上极限配置,并不一定划算。
五、Windows 台式机、Mac、旧笔记本,分别怎么选
| Windows / Linux 台式机 最稳的路线仍然是 NVIDIA 独显优先。对新手来说,生态成熟、教程多、兼容问题少,意味着你把时间花在“用模型”而不是“修环境”上。建议从 32GB RAM + 1TB SSD 起步。 | Apple Silicon Mac Mac 的优势是安静、省心、统一内存体验自然,尤其适合不想折腾驱动和 CUDA 的用户。缺点是升级空间没台式机大,所以一开始的内存档位就要选对:16GB 只适合小模型,24GB / 32GB 起更舒服。 |
| 旧笔记本 / 核显机 不是完全不能跑,但要把预期放低。更现实的目标是 1.5B、7B 这种小模型,或者把它当“先体验流程”的临时方案。别指望老机器跑大模型还又快又稳。 | AMD 显卡用户 并不是不能用,但新手要知道:驱动、ROCm 支持列表、工具链成熟度,都会影响你踩坑概率。如果你只是想快速上手,优先级通常仍然排在 NVIDIA 之后。 |
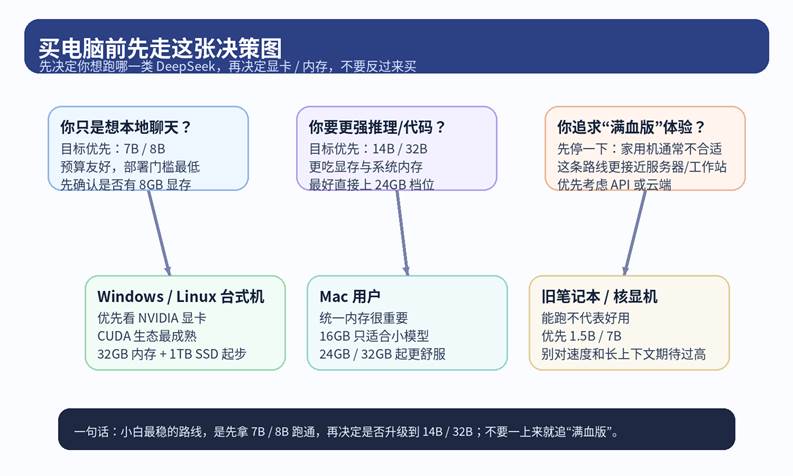
图 2|买电脑前先决定模型档位,再决定显卡与内存
六、预算怎么花,才不会买错
• 预算有限:先确保能顺利跑 7B / 8B。与其为了“以后可能要用”去硬挤高端显卡,不如先买一台真正能稳定跑通流程的机器。
• 预算中等:优先把目标定在 14B。这个区间往往是“投入”和“体验”最平衡的位置,适合多数认真想用本地模型的人。
• 预算充足:再考虑 32B 甚至 70B。但在这之前,先问自己:你每天是否真的会持续用到更强推理能力,还是只是在追参数数字。
| 一个很常见的错误购买逻辑 把大部分预算砸到 CPU、炫酷机箱或高刷新显示器上,却只留了一张显存不够的显卡。对于本地 LLM 来说,这种配法经常是“看起来很强,真正跑模型却卡”。 |
七、给小白的三套最实用建议
| 场景 | 建议路线 | 为什么这样配 |
| 只是想先玩懂 | 先从 7B / 8B + 简单工具开始 | 门槛最低,最适合建立正反馈 |
| 准备长期用 | 14B 作为主力目标 | 体验明显提升,预算还算可控 |
| 你已经是深度玩家 | 32B 往上再看 70B / 多卡 | 这时你才真正需要考虑更高阶的硬件与部署方式 |
八、FAQ
Q1:我只有 16GB 内存的普通笔记本,能本地部署 DeepSeek 吗?
能,但更现实的目标是 1.5B 或 7B 这类小模型,且最好别同时开太多软件。能跑和好用不是一回事。
Q2:本地部署一定要独显吗?
不是一定,但独显会大幅改善体验。Windows / Linux 上,独显尤其重要;Mac 则依赖统一内存。
Q3:为什么别人说自己“跑起来了”,但我这里还是很卡?
因为“跑起来”只代表成功启动,不代表输出速度、上下文长度和多轮稳定性都达标。模型大小、量化方式、软件后端、驱动和硬件带宽都会影响体感。
Q4:我要不要直接冲满血版 DeepSeek-R1?
如果你是小白,不建议。先把蒸馏版跑明白,再决定是否需要更高档位。对大多数个人用户来说,这样更省钱也更高效。
Q5:Mac 和 Windows 台式机,哪个更适合新手?
想省心、少折腾,可优先看 Apple Silicon Mac;想追求更高上限和后续升级空间,优先看 NVIDIA 台式机。
Q6:为什么文章里一直强调 7B / 8B / 14B?
因为它们恰好落在“个人用户能买、能装、能长期用”的甜点区间;这才是小白最需要的现实答案。
九、相关阅读
• 《三分钟读懂 Prompt:如何像指挥官一样给 AI 下达指令?》
• 《ChatGPT 注册与订阅全攻略(2026 最新修订版)》
• 《2026 年 5 款主流 AI 视频生成工具深度实测:Sora 之后谁最抗打?》
• 《一个人如何用 AI 批量生产短视频内容,完整流程拆解》
十、写在最后
真正适合小白的答案,往往不是“最强配置是什么”,而是“哪一档配置能让我今天就开始用,而且三个月后还愿意继续用”。
如果你只记住一句话,那就是:先按 7B / 8B / 14B 的现实路线买电脑,再决定要不要往 32B 或更高档位升级。对本地部署 DeepSeek 来说,这比一开始盯着满血版更聪明。
| 资料说明 本文根据 DeepSeek 官方仓库与模型页面、LM Studio 官方文档、Ollama 官方文档、llama.cpp 官方项目说明整理,并结合常见量化部署经验给出面向新手的配置建议。其中具体显存 / 内存数值属于保守经验估算,实际表现会随量化方式、上下文长度、推理后端与系统环境变化。 |
环境配置与 Docker 工作流
适合阅读安装部署、本地配置、服务器搭建和自动化流程类文章后继续转化。

一个回复