

AI 模型参数是什么意思?新手也能看懂
从参数量、量化、上下文到显存占用,一篇讲清模型说明页里最容易看懵的新手概念。
| 快速导读 | 你会学到什么 |
| 适合谁看 | 刚接触大模型、本地部署、开源模型选型,或者总被 7B / 14B / 70B / 4-bit 这些术语绕晕的人。 |
| 看完能解决 | 搞懂“参数是什么、参数影响什么、量化是什么意思、怎么看模型介绍页、如何按场景选模型”。 |
| 核心结论 | 参数量重要,但不是唯一标准;真正实用的判断方式,是把任务、设备、量化和实际测试放在一起看。 |
很多人第一次接触大模型,都会被 7B、14B、70B、4-bit、上下文长度、显存占用这些词绕晕。其实它们并不神秘。参数可以理解成模型在训练后学到的大量数字,参数量决定了模型体量和潜在上限,但并不等于“参数越大就一定越强”。真正影响体验的,还包括训练数据、架构、量化方式、上下文长度、推理速度和你的实际任务。
| 先记住这句话: 参数重要,但真正选型要把任务、量化、上下文和硬件一起看。 |
开头导语
如果你最近开始接触本地部署、开源模型或 AI 工具,大概率已经见过这些说法:这个模型是 7B,那个模型是 70B,这个版本是 4-bit 量化,那个支持 128K 上下文。很多新手听到这些术语时,最常见的反应是:我是不是应该直接选参数最大的?
先说结论:不用。参数量确实重要,但它只是理解模型的其中一把钥匙,不是唯一答案。对新手来说,更实用的做法是先搞懂“参数到底是什么、会影响什么、不会影响什么”,再根据任务、设备和预算去选。
一、参数到底是什么
可以把模型想象成一个非常复杂的数学函数。训练的过程,本质上就是让模型不断调整内部的数字,直到它更会预测下一个词、更会理解问题、更会生成你想要的结果。这些被训练出来的数字,统称为参数。
所以,模型参数并不是一堆给用户手动设置的开关,而是模型在训练后学到的“内部数值记忆”。它们分布在不同层、不同模块里,负责把输入变成输出。你看到的 7B、14B、70B,指的就是大约 70 亿、140 亿、700 亿个参数。
一个常见类比是:参数像一家工厂里的工人数量。工人更多,理论上能处理更复杂的流程,但如果生产线设计不好、原材料不好、分工不合理,工人再多也不一定比一家流程更好的工厂产出更高。
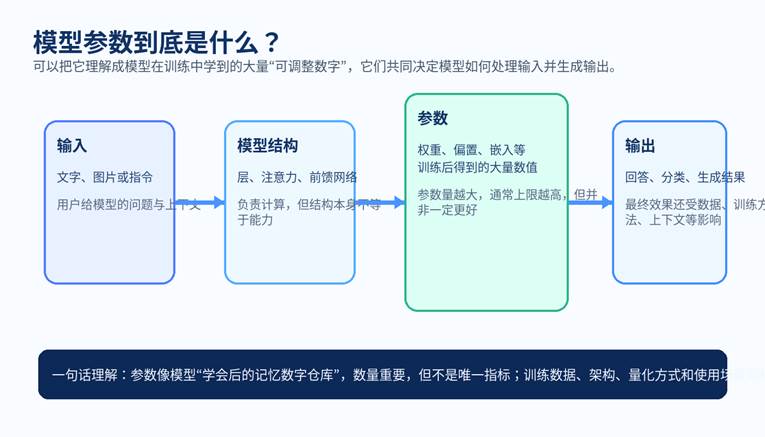
图 1:把参数理解成模型训练后形成的“内部数值记忆”,比把它看成某个可以手动开关的设置,更接近真实。
二、参数量会影响什么
第一,它通常会影响模型的容量上限。参数越多,模型表达复杂模式的能力往往越强,更有机会学到细腻的语言规律、复杂推理路径和更丰富的知识分布。
第二,它会明显影响资源占用。参数越多,模型文件通常越大,显存和内存需求也更高,推理速度往往更慢,部署成本会跟着上升。
第三,它会影响你可接受的使用方式。轻量模型适合本地聊天、快速摘要和低成本尝试;更大模型更适合复杂分析、强生成、长上下文和更高质量场景,但也更依赖硬件或云端。
三、参数量不会直接决定什么
它不直接等于实际效果。一个训练得更好的 7B 模型,完全可能在你的任务上胜过一个训练一般、调校一般、提示词也不合适的更大模型。
它不直接等于稳定性。模型会不会胡说、会不会漏信息、会不会格式失控,还和指令微调、对齐策略、系统提示词、上下文管理密切相关。
它也不直接等于“你一定要买更强电脑”。因为量化会显著改变资源需求,同一个参数档位,FP16、8-bit、4-bit 的占用会差很多。
四、新手最容易混淆的几个概念
参数量、模型文件大小、显存占用,这三个词经常被混着说。参数量是模型体量;模型文件大小是你下载到本地后占多少空间;显存占用则是模型运行时到底吃掉多少硬件资源。
上下文长度和参数量不是一回事。上下文长度决定模型一次能处理多长的输入,不是说参数更大,上下文就一定更长。很多模型在参数相近时,上下文能力也可能差很多。
MoE 模型要特别注意“总参数”和“激活参数”的区别。总参数听上去很大,但推理时可能只会激活其中一部分,所以它的实际资源占用和传统稠密模型并不完全一样。
一页看懂:模型参数相关概念
| 概念 | 一句话解释 | 新手应该怎么理解 |
| 参数量 | 模型里可训练数字的大致规模,如 7B、14B、70B。 | 决定体量与上限的重要线索,但不是唯一判断标准。 |
| 上下文长度 | 模型一次能“看见”的文本范围。 | 上下文越长,越适合长文、长对话和文档处理。 |
| 量化 | 把参数用更省空间的形式存储,如 8-bit、4-bit。 | 直接影响显存占用、速度和精度折中。 |
| 显存/内存占用 | 模型运行时需要的硬件资源。 | 能不能在自己电脑上跑起来,先看这个。 |
| 训练数据与训练方法 | 模型用什么数据训练、怎么训练。 | 很多时候比“单纯更大”更影响实际效果。 |
| MoE / 激活参数 | 混合专家模型每次只激活部分参数。 | 总参数很大,不代表每次推理都用全部参数。 |
五、为什么会有 4-bit、8-bit、FP16 这些词
这类词通常在说量化或精度格式。直观理解就是:同样一堆参数,可以用更精细、更占空间的方式存,也可以用更紧凑、更省资源的方式存。
FP16 通常更接近原始精度,效果稳定,但更吃显存。8-bit 和 4-bit 会更省空间,更适合本地部署,但精度可能有一定折损。对新手而言,最重要的不是背术语,而是记住一句话:量化是在“资源占用”和“效果损失”之间做折中。
也正因为如此,很多人会发现一个 7B 模型经过 4-bit 量化后,能在自己的电脑上流畅跑起来;而同档位的高精度版本,可能就已经超出显存能力。
六、如何读懂模型介绍页
第一步,看任务定位。它到底偏聊天、写作、代码、数学、视觉理解,还是检索增强问答?先看场景,再看参数。
第二步,看参数量和架构。是 3B、7B、14B 这类稠密模型,还是 MoE?这一项决定你大致能期待的体量和资源范围。
第三步,看上下文长度和量化版本。对于处理长文档、会议纪要、知识库问答的人,这两项经常比“单纯更大”更重要。
第四步,看实际 benchmark 和用户反馈,但别只看总分。你最该关心的是:它在你自己的提示词、你自己的语料、你自己的场景里表现如何。
第五步,看部署门槛。包括显存、内存、速度、生态兼容性,以及有没有成熟的本地运行工具可用。
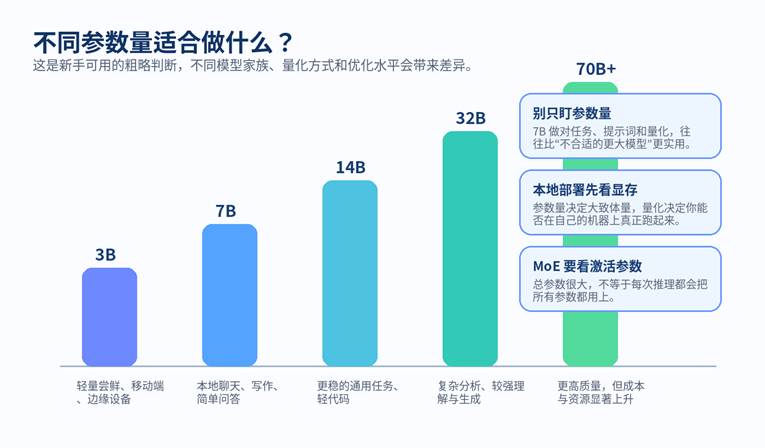
图 2:参数档位只是粗粒度判断,新手真正该优先看的是“我的任务 + 我的机器 + 我能接受的速度”。
按场景选模型:新手更实用的看法
| 你的场景 | 建议优先看的参数档位 | 为什么这样选 |
| 只是想入门体验 | 3B—7B | 先理解概念、跑通流程、做轻量问答或摘要。 |
| 日常写作/办公/聊天 | 7B—14B | 兼顾速度和效果,是多数新手最容易上手的区间。 |
| 轻代码与复杂分析 | 14B—32B | 通常更稳,但对显存和推理速度要求更高。 |
| 追求高质量输出 | 32B 以上或云端大模型 | 本地成本明显上升,很多人会转向云端调用。 |
| 本地设备比较弱 | 量化 4-bit 的轻量模型 | 先保证能跑起来,再谈升级。 |
七、新手怎么选模型更省事
如果你只是想理解概念、体验本地聊天或跑轻量问答,优先看 3B 到 7B 的轻量模型就够了。先跑通流程,比一开始追大模型更重要。
如果你要做日常写作、总结、翻译、知识整理、一般办公辅助,7B 到 14B 往往是比较均衡的选择。
如果你想做更复杂的分析、较强的代码辅助或更稳的长文任务,再考虑 14B 到 32B 甚至更大。但这时候你需要认真评估显存、量化和速度,别只看名字里的参数。
如果机器配置一般,不妨把思路改成:本地留一个轻量模型做常驻工具,复杂任务再用云端大模型补位。很多一人团队和个人创作者,都是这样搭配的。
八、最常见的 7 个误区
误区一:参数越大一定越聪明。实际上你用起来最顺手的,往往是“足够好且足够稳”的模型。
误区二:看到 70B 就默认碾压 7B。不同训练数据、不同指令微调、不同量化和不同任务,会让实际差距发生很大变化。
误区三:只看模型文件大小,不看量化说明。下载包一样大,并不代表运行时资源占用完全一样。
误区四:只看跑分,不做自己的样本测试。跑分是参考,不是你的真实工作流。
误区五:把上下文长度当作参数量的一部分。它们是两个不同维度。
误区六:把 MoE 的总参数当作每次推理都全量使用。不是。
误区七:本地部署追求一步到位。正确路径通常是先跑通、再优化、再升级。
把上面内容浓缩成一句话,就是别把“参数量”当成唯一决策器。下面这份避坑清单,适合在你准备下载模型或看模型页时快速过一遍:
• 先看任务,再看参数;先看机器,再看量化。
• 别把上下文长度、模型大小、显存占用混为一谈。
• 别只看总参数,MoE 还要看激活参数和部署生态。
• 别只看 benchmark,总要拿自己的真实提示词做测试。
• 别急着一步到位,轻量模型 + 主力模型的组合通常更稳。
新手选模型的 5 步判断法
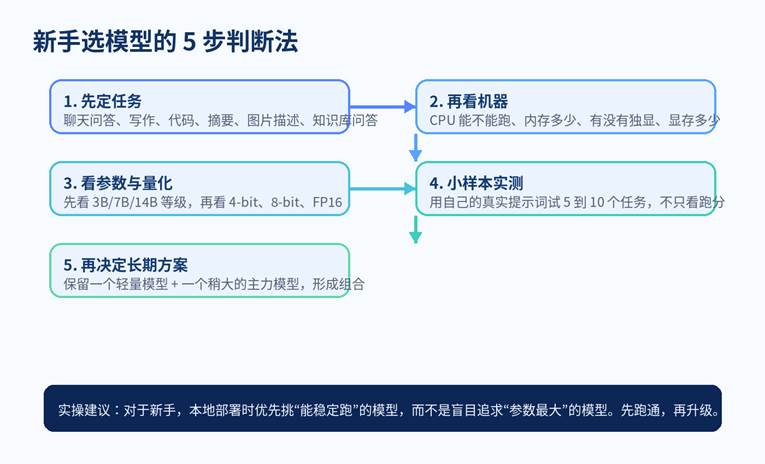
图 3:先从任务与设备出发,再结合量化和真实测试结果决定是否升级,这比盲目追“最大参数”更省时间。
九、给新手的实操建议
先列出你最常做的 5 个任务,例如总结长文、改写标题、写邮件、问答、代码解释。没有任务,选型就会飘。
再看你的设备。有没有独显?显存多少?内存多少?你能接受多慢的响应速度?硬件条件决定了你应该先看哪一档模型。
然后挑两个候选:一个轻量版本、一个稍大版本。用同一组真实提示词做对照测试,看谁更符合你自己的工作流。
最后再决定是否升级。很多人真正需要的不是“更大”,而是“更稳定、更快、更容易接入自己的流程”。
实操模板:5 分钟看懂一个模型
| 任务:我主要用它做什么? 设备:我的显存 / 内存够不够? 体量:它是几 B?是稠密模型还是 MoE? 部署:我打算用什么量化版本? 测试:我会拿哪 5 条真实提示词来验证? 结论:它是“适合我”,还是只是“看上去很强”? |
FAQ:新手最常问的问题
参数量越大,模型一定越好吗?
不一定。参数量只是影响效果的因素之一。训练数据、模型架构、指令微调、量化方式、上下文长度以及你的具体任务,都会影响最终体验。
7B、14B、70B 这些数字该怎么理解?
它们是参数量的大致档位,B 代表 billion,也就是十亿。7B 约等于 70 亿参数,14B 约等于 140 亿参数。
量化会不会让模型变笨?
可能会有一定损失,但换来的是更低的显存占用和更容易本地部署。对多数新手来说,量化版本往往更实用。
为什么有些小模型也很好用?
因为“好不好用”取决于任务匹配度。对摘要、翻译、固定格式输出等任务,一个调校成熟的小模型可能比大而泛的模型更顺手。
MoE 模型是不是一定更划算?
不一定。MoE 会在效率和规模之间带来新的折中,但生态成熟度、部署工具支持和具体实现方式也非常关键。
我看模型介绍页时最先看哪三项?
先看任务定位,再看参数量与量化版本,最后看上下文长度和部署门槛。这样最容易做出靠谱判断。
相关阅读
• n8n、Dify、Coze 是什么?自动化工作流入门教程
结语
理解 AI 模型参数,真正的价值不是为了背术语,而是让你以后看到模型页面时不再只盯着“几 B”。当你学会把参数量、量化、上下文、部署成本和任务场景放在一起看,选型这件事就会清楚很多。对于新手来说,先跑通一个合适的小模型,再逐步升级,远比一开始就追求“最大的那个”更有效。
环境配置与 Docker 工作流
适合阅读安装部署、本地配置、服务器搭建和自动化流程类文章后继续转化。

2 回复