
开源大模型推荐:适合本地部署的有哪些
从模型选择、硬件匹配到实际部署,把本地部署这件事一次讲清楚
文档类型:资源与模型 / 入门教程 更新日期:2026-04-05 适合人群:想把大模型跑在自己电脑上的新手与进阶用户
封面图:本地部署不只是“能跑起来”,更重要的是模型、硬件与使用场景的匹配。
| 先给结论 如果你是第一次尝试本地部署,最稳妥的路线通常不是一上来追求“最大参数”,而是先选一个真正跑得动、响应速度可接受、中文能力够用的模型。对大多数个人电脑来说,8B 到 14B 往往是最好上手的甜点位;想要更强推理,可以优先考虑 DeepSeek-R1 的蒸馏模型,而不是直接上完整的 671B 大模型。 |
一、先弄清楚:什么样的模型更适合“本地部署”?
很多人第一次接触开源大模型时,最容易陷入两个误区:第一,只盯着排行榜;第二,只看参数量。真正适合本地部署的模型,不是“网上最火”的那个,而是“你的设备能够稳定跑、你的任务能明显受益、你的使用成本可持续”的那个。
本地部署时,最重要的并不是理论能力上限,而是以下四个维度:
- 硬件门槛:你的 CPU、显卡、显存、统一内存和硬盘空间是否能承受;
- 量化与格式:同一个模型,GGUF、MLX、原始权重在本地部署难度上差别很大;
- 任务类型:你要的是聊天写作、代码补全、中文总结、长文推理,还是图文多模态;
- 维护成本:命令行、图形界面、Web UI、知识库接入、模型升级,这些都会影响长期使用体验。
三个概念别混淆
1)开源 / 开放权重:不同模型的开放程度并不一样;2)参数量不等于体验:量化、推理框架和设备架构都会影响真实速度;3)本地部署不等于纯离线:有些工具本地跑模型,但下载模型、插件或界面组件时仍可能联网。
二、先记住这几个关键词:你后面选模型一定会用到
关键词是什么意思为什么重要给新手的理解方式 Instruct经过指令对齐,适合直接聊天和完成任务。新手几乎都应该优先选 Instruct,而不是 Base。把它理解成“能直接拿来用”的版本。 GGUF适合 llama.cpp / Ollama / LM Studio 等本地推理生态的常见格式。决定你是否能方便地量化、下载和运行。很多人本地部署的第一站,基本都会遇到它。 量化把模型权重压缩成 8bit、4bit 甚至更低精度,减少内存占用。能不能在普通电脑跑起来,往往就看量化。画质略降但体积大幅缩小,类似把视频压缩后更好传输。 上下文长度模型一次能“记住”多少输入内容。影响长文总结、知识库问答、多轮对话。上下文越大越爽,但也越吃内存。 MoE混合专家架构,推理时只激活其中一部分参数。有些大模型看起来很大,但激活参数更少,效率更高。像一个大团队里只叫相关专家开会。
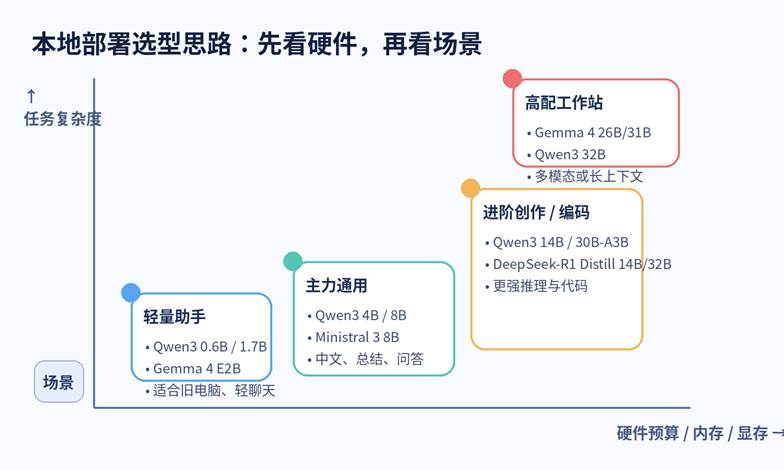
图 1:本地部署的核心不是盲目追大,而是把模型能力与硬件和场景配平。
三、2026 年仍值得重点看的本地部署模型
下面这份推荐清单,优先考虑的是“个人用户能实际部署”的价值,而不是单纯拼榜单。换句话说:我更看重它们在普通电脑、Apple Silicon、单张消费级显卡上的可用性。
| 模型家族 | 适合谁 | 推荐理由 | 本地部署难度 | 我会怎么用 |
| Qwen3 | 想要中文、通用、代码兼顾的用户 | 尺寸覆盖从 0.6B 到 32B,还有 30B-A3B / 235B-A22B;同时支持 thinking 与 non-thinking 两种模式,部署生态也很齐。 | 低到中 | 把它作为大多数本地用户的第一主力模型。 |
| Gemma 4 | 想要轻量、多模态、长上下文的人 | Gemma 4 提供 E2B、E4B、26B A4B、31B,官方强调可从手机、笔记本一直覆盖到服务器;并且 Apache 2.0 许可友好。 | 低到中 | 轻量本地助手或图文理解非常值得试。 |
| Ministral 3 / Mistral 3 | 更关注英文、边缘部署与工程可控性 | Mistral 3 发布了 3B、8B、14B 小模型与更大的 Large 3,Apache 2.0,边缘部署路线清楚。 | 中 | 适合做更偏工程化的本地服务。 |
| DeepSeek-R1 Distill | 重视推理、数学、代码问题的人 | 不要直接冲完整 R1;对个人用户来说,1.5B / 7B / 14B / 32B 等蒸馏版本更现实,尤其是 Qwen 蒸馏系。 | 中 | 当你想要比通用聊天更强的“思考味”时很有价值。 |
| Llama 系列 | 有特定生态偏好、能接受许可差异的用户 | 生态成熟、资料多,但新一代 Llama 4 更偏高配和多模态路线;对普通个人电脑,新手未必把它放第一优先级。 | 中到高 | 更适合有明确生态目的,而不是完全从零开始。 |
1)Qwen3:现在最适合大多数本地用户优先试的“通用主力”
Qwen3 的一个优势在于,它不是只给你一个“大旗舰”,而是给出一整套从轻量到进阶的尺寸。官方仓库明确列出了 0.6B、1.7B、4B、8B、14B、32B 以及 30B-A3B、235B-A22B 等规格;同时官方还给出了 llama.cpp、Ollama、LM Studio、MLX、OpenVINO、vLLM 等多条本地部署路线。对中文用户来说,这种“模型尺寸够全 + 中文表现稳定 + 工具支持齐全”的组合,几乎就是最省心的选择。
2)Gemma 4:轻量设备和多模态设备里,非常值得关注
Gemma 4 这代最吸引人的地方,是它把“轻量”和“能力”做了更好的平衡。官方模型卡给出 E2B、E4B、26B A4B 和 31B 四个尺寸,并强调从高端手机、笔记本到消费级工作站都能找到对应部署位置。再加上官方给出长上下文、多模态和 Apache 2.0 许可,对个人开发者和内容工作流都很友好。
3)DeepSeek-R1 Distill:不是每个人都需要,但需要的人会很喜欢
如果你希望模型在数学、代码、结构化推理上更有“思考感”,那 DeepSeek-R1 的蒸馏模型很值得试。官方仓库直接提醒,完整 R1 是 671B 总参数、37B 激活参数的超大模型;对个人电脑来说,真正现实的是基于 Qwen 和 Llama 的蒸馏版,例如 7B、14B、32B。它们保留了一部分 reasoning 风格,但部署成本要友好得多。

图 2:普通用户最容易成功的,通常是 4B-14B 这一档;过大模型往往让维护成本迅速上升。
四、别从模型反推硬件,先从你的电脑反推模型
下面这个方法很实用:先把自己的设备分层,再决定目标模型。这样做的好处是,你不会把时间浪费在下载一个根本跑不动的模型上。
A. 轻量设备:8GB-16GB 内存,或者只有 4GB-8GB 显存
- 优先考虑 Gemma 4 E2B / E4B、Qwen3 0.6B / 1.7B / 4B 这类轻量模型;
- 这类设备的目标不是“最强能力”,而是“响应快、稳定、能长期挂着用”;
- 适合做写作草稿、日常问答、轻量翻译、文案润色、基础知识整理。
B. 主流电脑:16GB-32GB 内存,或 8GB-12GB 显存
- 这通常是本地部署最舒服的区间:Qwen3 8B、Ministral 3 8B 都值得优先试;
- 如果你是程序员,也可以把代码场景与通用场景分开,保留一个专门的代码模型;
- 多数个人用户真正长期使用的“主力模型”都在这个层级。
C. 高配桌面 / Apple Silicon:32GB-64GB 统一内存,或 24GB 左右显存
- 可以开始看 Qwen3 14B / 30B-A3B、DeepSeek-R1 Distill Qwen 14B / 32B、Gemma 4 26B A4B;
- 这时你已经不仅在乎“能不能跑”,而是会开始在乎更强推理、更多上下文、更好的输出稳定性;
- 适合做较复杂的本地知识库、代码审查、长文分析与深度研究辅助。
D. 工作站 / 多卡环境
- 这类设备当然能看更大的模型,但新手没必要把它当作第一步;
- 模型越大,调度、显存管理、框架兼容、量化策略就越复杂;
- 如果你还没形成稳定的使用场景,先把 8B-14B 用顺,比一开始硬上巨型模型更划算。
五、用什么工具跑最省心?新手优先这样选
工具适合谁优点注意点Ollama最想快点跑起来的人安装简单,模型获取方便,命令很直观,还能接 OpenAI 兼容 API。模型标签和原始命名可能不完全一致,参数默认值也要注意。LM Studio更喜欢图形界面的用户下载、加载、聊天、调参、开本地服务器都更直观。对低内存设备仍然要谨慎,图形界面不代表更省资源。llama.cpp愿意折腾、想更细调性能的人生态成熟、格式丰富、量化灵活、CPU/GPU 混合推理路线清楚。命令参数较多,对新手来说学习曲线略高。Open WebUI想把本地模型变成网页工作台的人支持 Ollama 和 OpenAI 兼容后端,适合知识库、多模型切换和团队内使用。它是“界面层”,不是替你跑模型的核心引擎。

图 3:对新手最稳的路线通常是「Ollama / LM Studio 跑模型」+「Open WebUI 做界面」。
我的建议
如果你只想尽快体验:用 LM Studio。若你想后面接 API、知识库、自动化工作流:优先学会 Ollama。若你已经开始关心量化、显卡 offload、不同后端性能:再认真学 llama.cpp。
六、给新手的一条实操路线:先用 Ollama 跑一个主力模型
下面这套流程的目标不是“最极客”,而是“成功率最高”。你先用它把本地部署跑通,后面再考虑更复杂的框架。
- 先安装 Ollama。它是目前上手门槛最低的一类本地模型运行工具之一,支持通过简单命令拉取模型并启动本地服务。
- 先选 1 个主力模型,不要一口气下载 5 个。对普通用户来说,Qwen3 8B 是一个很稳的起点;想更轻一点就试 Gemma 4 小模型;想试 reasoning 风格再看 DeepSeek-R1 Distill。
- 模型第一次跑通后,再决定要不要接 Open WebUI、知识库、自动化流程。很多人一开始把东西堆太多,反而排障更难。
ollama serve
# 2) 拉取并运行一个主力模型(示例)
ollama run qwen3:8b
# 3) 如果你想用网页界面,再接 Open WebUI
docker run -d -p 3000:8080 –add-host=host.docker.internal:host-gateway \
-v open-webui:/app/backend/data –name open-webui –restart always \
ghcr.io/open-webui/open-webui:main
跑通之后,你要做的第一件事不是马上追更大模型,而是先验证三件事:
- 速度你能不能接受:首 token 是否太慢,连续输出是否卡顿;
- 质量是否够用:对你的真实任务,8B 模型是不是已经足够;
- 稳定性是否足够:多轮对话、长文本、文档总结会不会明显掉质量。
七、最容易踩的坑,我建议你提前避开
1)把“能加载”误以为“能顺畅用”
- 有些模型虽然能勉强跑起来,但回复速度慢到根本用不起来。
- 本地部署是长期工作流,不是一次性演示。
2)直接追完整的 DeepSeek-R1、Llama 4 大模型
- 完整 R1 是 671B 级别,对个人电脑并不现实。
- 很多人真正需要的,是它们的蒸馏版或更小尺寸变体。
3)忽略许可差异
- Gemma 4 和 Mistral 3 系列官方都给出 Apache 2.0;
- Llama 4 采用的是 Llama 4 Community License,和 Apache / MIT 不是一回事。
4)一开始就想把 RAG、自动化、Agent、知识库全部堆上
- 先把单模型聊天、摘要、问答跑顺,后面再逐步接工作流。
- 每多一层组件,排障复杂度都会显著上升。
八、FAQ:本地部署新手最常问的 8 个问题
1. 我只有普通笔记本,能不能玩本地大模型?
可以,但要把目标放对。普通笔记本更适合跑轻量或中小尺寸模型,例如 1.5B、4B、8B 这一档,而不是去追完整旗舰模型。
2. 我是中文用户,优先试哪个?
如果只想要一个稳妥起点,我会优先试 Qwen3。它的中文、通用任务和部署生态都比较均衡。
3. 想要更强的推理,是不是一定要上超大模型?
不一定。对个人用户来说,DeepSeek-R1 的蒸馏版往往比完整模型更现实,也更适合本地体验。
4. LM Studio 和 Ollama 选哪个?
喜欢图形界面、想快速体验,先用 LM Studio;想后续接 API、Open WebUI、自动化工作流,优先学 Ollama。
5. 为什么同一个模型别人说很好,我这里却很慢?
因为设备结构、量化格式、上下文设置、是否 GPU offload、是否走图形界面,都会影响体感速度。
6. 量化是不是一定会让效果变差很多?
会有损失,但往往比你想象的小。对大多数本地场景来说,量化是把模型真正用起来的关键步骤。
7. 本地部署是不是一定更安全?
本地运行意味着数据不一定要发给云端模型,但你仍然要注意下载来源、插件、联网组件和界面工具本身的权限。
8. 新手应该准备多少预算才舒服?
没有唯一答案,但从体验角度看,能稳定运行 8B-14B 模型的设备,通常就已经能覆盖很多真实工作任务。
九、相关阅读(相对路径)
十、本文参考的官方资料
- Gemma 4 model card(Google AI for Developers) https://ai.google.dev/gemma/docs/core/model_card_4
- Qwen3 official repository(GitHub) https://github.com/QwenLM/qwen3
- Introducing Mistral 3(Mistral AI) https://mistral.ai/news/mistral-3
- DeepSeek-R1 official repository(GitHub) https://github.com/deepseek-ai/DeepSeek-R1
- llama.cpp official repository(GitHub) https://github.com/ggml-org/llama.cpp
- LM Studio system requirements https://lmstudio.ai/docs/app/system-requirements
- Open WebUI docs https://docs.openwebui.com/
- Llama 4 official docs / model page https://www.llama.com/models/llama-4/
环境配置与 Docker 工作流
适合阅读安装部署、本地配置、服务器搭建和自动化流程类文章后继续转化。

2 回复