

2026年中文大模型横向测评:DeepSeek vs 文心一言 vs 通义千问,谁更适合你的真实场景?
从中文写作、推理编码、多模态、Agent、成本与生态五个维度看透差异
定位:AI 工具评测 / 选型指南 | 适合人群:内容创作者、开发者、AI 工作流搭建者、企业数字化团队
| 先看结论 • 想要低成本、高速度、开发者友好、推理与代码都强:先看 DeepSeek。 • 想要中文表达稳、多模态能力全、企业合规与百度生态配套成熟:优先看文心一言 / 文心大模型。 • 想要开源生态、长上下文、Agent 与本地化二次开发能力兼得:通义千问通常更均衡。 • 如果你不是在做通用测评,而是在做真实业务,最好的模型往往不是“总榜第一”,而是“在你的任务上最顺手”。 |
一、为什么 2026 年要重新比较这三家?
过去一年,中文大模型已经从“谁先发布新参数”转向“谁更适合真实工作流”。同样是聊天入口,DeepSeek、文心一言、通义千问背后的产品路线已经明显分化:有的以高性价比和开源影响力吸引开发者,有的把原生全模态和企业级能力做深,有的则同时经营开源权重、云端模型、Agent 工具和长上下文生态。
这篇文章不做单一榜单式结论,而是按真实使用场景来比较。因为 2026 年的一个基本事实已经越来越清楚:顶级模型的绝对差距在缩小,决定选型的往往不是某个跑分,而是中文体验、工具调用、接入成本、生态兼容和团队长期可维护性。
二、先别急着排总榜:这三家根本不是同一条产品路线

图 1:三家模型的核心差异,更适合用“路线”而不是“单榜第一”来理解
DeepSeek、文心一言、通义千问之所以经常被放在一起讨论,是因为它们都能回答问题、写文案、生成代码、理解图片,表面看起来很像。但如果把它们放进真实业务里,你会发现三家的发力方向并不一致。DeepSeek 更像一把锋利、便宜、上手快的开发者刀;文心更像一个大厂平台化解决方案;通义则更像一个可云可本地、可开源可商用的综合底座。
所以,这篇文章不会简单回答“谁最强”,而会回答另一个更有价值的问题:你在哪一种任务上最容易从它身上拿到结果?
三、DeepSeek:为什么程序员和自动化玩家会先看它?
DeepSeek 之所以在 2026 年仍然拥有很高讨论度,核心不只是“便宜”,而是它把开发者最在意的几个点做成了组合拳:OpenAI 兼容接口、明确的 thinking / non-thinking 使用心智、工具调用能力、以及强烈的开源社区存在感。当前 API 文档显示,`deepseek-chat` 与 `deepseek-reasoner` 对应 DeepSeek-V3.2 的非思考与思考模式,统一为 128K 上下文;输入输出价格依旧维持极低水平,这让它在批量写作、代码补全、自动化工作流和中小团队 Agent 原型里非常有吸引力。
更关键的是,DeepSeek 并没有停留在“便宜替代品”的角色。官方更新记录里已经反复强调其 tool use、多步 agent 任务、SWE / Terminal-Bench 等方向的加强,这意味着它更适合被放进自动化链路里,而不是只做一个聊天窗口。对于程序员、自动化玩家、AI 工作流搭建者来说,DeepSeek 往往是最容易起步、最低心理成本、同时又足够能打的一条线。
它的短板也同样明显。第一,官方消费端体验和企业级产品包装没有百度、阿里那样完整;第二,中文写作虽然已经很强,但在一些需要“更稳的中文语气”和官方风格表达的场景里,不一定总能赢;第三,企业采购、行业解决方案、完整平台能力并不是它最强的卖点。
四、文心一言:为什么它在中文和企业场景里仍然很难绕开?
文心一言在 2026 年的优势,已经不只是“国产大厂有流量入口”,而是百度把模型、搜索、Agent Infra、企业平台和原生全模态路线捏成了一套更重的平台能力。百度公开资料显示,文心 5.0 已在千帆上线,主打原生全模态统一建模,支持文本、图像、音频、视频的输入与输出;同时,文心 4.5 Turbo、X1 Turbo 仍然是面向开发者和应用落地的重要主力线。
放在真实使用里,文心一言最大的优点是中文表达的稳定性、知识型内容组织能力、以及企业交付时的“成套能力”。如果你做的是企业知识问答、中文客服、政企内容、严肃信息整合、百度生态相关分发或带搜索的复杂问答,文心的整体完成度往往会更高。尤其在需要合规、供应商交付、平台级服务支持的场景里,它比很多单点能力更强的模型更容易被采购。
但文心的劣势也不能回避。对于个人开发者和追求极致性价比的中小团队来说,它在“开源影响力”和“社区自由度”上不如 DeepSeek / Qwen;如果你的核心诉求是本地部署、深度二开、模型社区丰富度和快速迭代玩法,文心路线通常没有前两者灵活。
五、通义千问:为什么它越来越像“长期主义”的底座型选手?
通义千问的独特之处,在于它不是单一模型,而是一整条开放生态路线。到了 2026 年,阿里已经把 Qwen 做成了“开源权重 + 云端商业模型 + Agent 工具链 + 多模态系列”的组合:Qwen3 与 Qwen3.5 系列持续公开权重,百炼平台里又提供 Max、Plus、Flash、Coder、VL、Omni 等多线产品,开发者既能云上调用,也能本地部署或二次训练。
从选型角度看,Qwen 的最大长板是均衡。它不一定在每一个细分点都最极致,但往往在最多场景里都能给出‘不差而且好用’的体验。百炼官方文档显示,当前旗舰已扩展到 Qwen3.6-Plus / Qwen3.5-Plus,支持最高 100 万上下文;而 GitHub 上的 Qwen3 / Qwen3.5 权重发布,又给了开源社区非常强的二次开发空间。对做 RAG、长文档问答、代码 Agent、私有化部署和混合架构团队来说,Qwen 往往是最稳的中枢模型之一。
它的挑战主要在两点。第一,产品线很多,新手容易选花眼;第二,如果只看 API 性价比,某些场景下它未必像 DeepSeek 那样‘便宜得很夸张’。所以 Qwen 更像一个工程师和团队型选手:当你需要长期建设,而不是只要一个最便宜的入口时,它会越来越香。
六、五个关键维度横向测评
| 维度 | DeepSeek | 文心一言 | 通义千问 |
| 中文写作 | 技术说明、结构化总结、直给型输出很强;风格偏利落。 | 中文语气、正式文本、知识型内容整合更稳。 | 长文、多轮续写、创意写作和跨语种任务更均衡。 |
| 推理与代码 | 推理强,价格低;对自动化、函数调用、代码任务非常友好。 | 企业知识问答、复杂检索、多模态问答更有平台配套。 | Qwen Coder / Agent 线强,适合长期工程化建设。 |
| 多模态 | 以文本+推理心智最突出。 | 文心 5.0 主打原生全模态,是百度路线的核心卖点。 | Qwen 在 VL、Omni、TTS、ASR 等方向布局完整。 |
| 成本与接入 | API 价格很有冲击力,OpenAI 兼容接口好上手。 | 按平台能力采购更有价值,4.5 Turbo/X1 Turbo 仍有性价比。 | 模型梯度丰富,能按预算和任务精细选型。 |
| 开源与生态 | 开源声量大,社区活跃,适合快速实验。 | 更偏平台交付和闭源能力整合。 | 开源权重、云上调用、Agent 框架三线并进。 |
| 适合谁 | 个人开发者、小团队、自动化工作流搭建者。 | 企业客户、中文内容团队、合规与平台采购场景。 | 做长期产品、RAG、私有部署、Agent 平台的团队。 |
如果一定要给一个简化结论,我的建议是:把 DeepSeek 当成高性价比的开发者模型,把文心当成中文 + 企业 + 原生多模态平台,把通义当成开源与工程化并重的长期底座。
七、真正好用的选型方法:按任务选,不按热度选
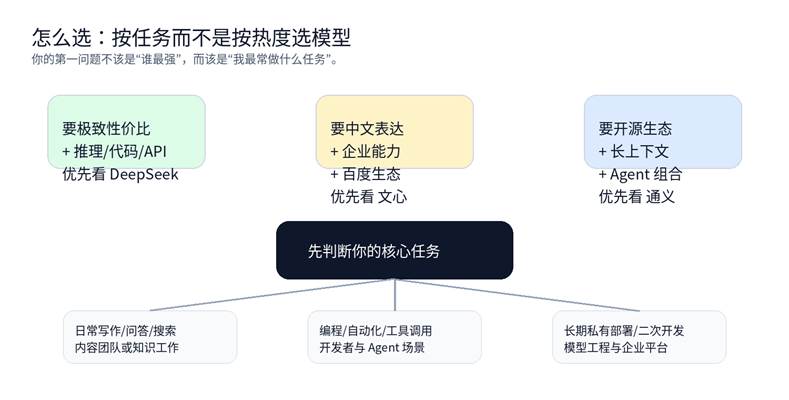
图 2:2026 年模型选型更像分流,而不是一次性押注
对个人内容创作者来说,如果你每天都在写文章、做脚本、润色标题和整理资料,那么先看谁更顺手;对开发者来说,优先比较 API 成本、函数调用、Agent 稳定性和代码质量;对企业团队来说,则应该先看供应商能力、数据与平台、安全合规、以及是否能纳入原有工作流。
换句话说,‘你每天重复做的任务’比‘网友热议的榜单’更能决定答案。模型选型一旦进入真实生产环境,稳定性、成本、接口兼容、上下文长度和团队迁移成本,往往比单次惊艳回答更重要。
八、我的实战建议:三种典型人群怎么选
第一类是个人用户或一人公司。你最适合从 DeepSeek 与通义千问开始对比。前者能快速压低成本,后者更适合逐步搭建长期工作流。如果你重度写中文内容,也可以同步保留文心入口作为‘中文语感校正器’。
第二类是内容团队和知识工作团队。你们更应该比较文心与通义。文心在企业语境、知识整合、多模态和平台能力上更稳,通义则在开放性、可组合性和后续私有化路线里更灵活。
第三类是开发者和 Agent 团队。优先把 DeepSeek 与 Qwen 放到同一张表里看。DeepSeek 适合快速原型、自动化脚本、批量工作流和低预算实验;Qwen 则更适合作为长上下文、代码 Agent、私有部署和复杂应用编排的底座。
九、FAQ
1. 哪个最适合中文写作?
如果你主要做中文内容创作、商务写作、知识整理、偏正式语气的问答,文心通常更稳;如果是技术写作、结构化输出、效率优先,DeepSeek 往往更利落;如果是长文协作和多轮扩写,通义千问更均衡。
2. 哪个最适合程序员和 Agent?
DeepSeek 和通义千问更值得优先考虑。DeepSeek 胜在成本和接入友好,Qwen 胜在长上下文、Coder 线和 Agent 生态完整度。
3. 哪个更适合企业采购?
如果你更看重平台能力、合规支持、搜索与 Agent 基建、供应商交付,文心一言 / 百度千帆通常更容易进入企业方案。
4. 一定要只选一家吗?
不一定。2026 年更常见的做法是‘主模型 + 备份模型 + 垂直模型’组合,例如写作用文心、自动化用 DeepSeek、长文档和本地部署用 Qwen。
5. 本地部署应该优先谁?
从开源权重与社区生态看,Qwen 和 DeepSeek 都更适合;如果你希望有更多尺寸、更成熟的社区工具和教程,Qwen 会更友好。
6. 普通用户不写代码,怎么选?
只看前端体验与日常效率,谁的入口你最常用、回答风格最顺手,谁就是更好的选择。对多数普通用户来说,‘稳定、快、便宜、好上手’比跑分更重要。
十、相关阅读
• OpenClaw 是什么?为什么 2026 年大家都在聊 AI Agent“龙虾”生态
• AI 浏览器会不会成为下一个超级入口?从搜索到执行的产品演进
• 从 0 到 1 搭建你的个人 AI 第二大脑:Obsidian + AI 深度整合指南
附:本文参考口径说明
本文采用的是“产品与场景选型”视角,而不是纯实验室跑分视角。由于 2026 年三家产品线都在持续更新,文中更关注截至 2026 年 4 月公开可确认的主力模型、上下文、平台能力、定价路线与生态形态。不同细分任务里,最佳选择可能仍会变化。
• DeepSeek API Docs – Models & Pricing / Change Log / V3.1, V3.2 release pages
• 百度智能云千帆 – 文心 5.0 上线公告、模型列表、文心 4.5 Turbo / X1 Turbo 发布说明
• 阿里云百炼 / PAI / Qwen 官方 GitHub – 模型列表、Qwen3 / Qwen3.5 权重发布、Qwen Code 与 Qwen Chat 页面
• SuperCLUE 中文大模型测评基准 2026 年 3 月榜单页面(用于了解当期测评维度,而非单一结论来源)
结语:别再问谁是绝对第一,先问谁最适合你
如果你把 2026 年的中文大模型竞争看成一场“谁把谁彻底打服”的战争,往往会失真。更贴近现实的理解是:DeepSeek 把开发者成本线拉低了,文心把平台与企业路线做深了,通义把开源与工程化的中间地带做厚了。它们并不是简单互相替代,而是在不断重叠、分流和争夺更具体的使用场景。
对读者来说,最有效的办法永远不是追当天的热搜,而是拿自己的真实任务去跑一轮:同一份长文、同一段代码、同一份知识库问答、同一条自动化流程,让三家模型都做一次。谁更稳定、谁更省钱、谁更顺手,答案通常会非常清楚。
最后一句建议:个人用户先看体验,开发者先看成本与接口,企业团队先看平台与治理。把这个顺序记住,选型就不会跑偏。
